前言
生产者消费者问题(英语:Producer-consumer problem),也称有限缓冲问题(英语:Bounded-buffer problem),是一个多线程同步问题的经典案例。该问题描述了两个共享固定大小缓冲区的线程——即所谓的“生产者”和“消费者”——在实际运行时会发生的问题。生产者的主要作用是生成一定量的数据放到缓冲区中,然后重复此过程。与此同时,消费者也在缓冲区消耗这些数据。该问题的关键就是要保证生产者不会在缓冲区满时加入数据,消费者也不会在缓冲区中空时消耗数据。
看完了定义,相信懵逼的依然懵逼,那我就来说人话吧。
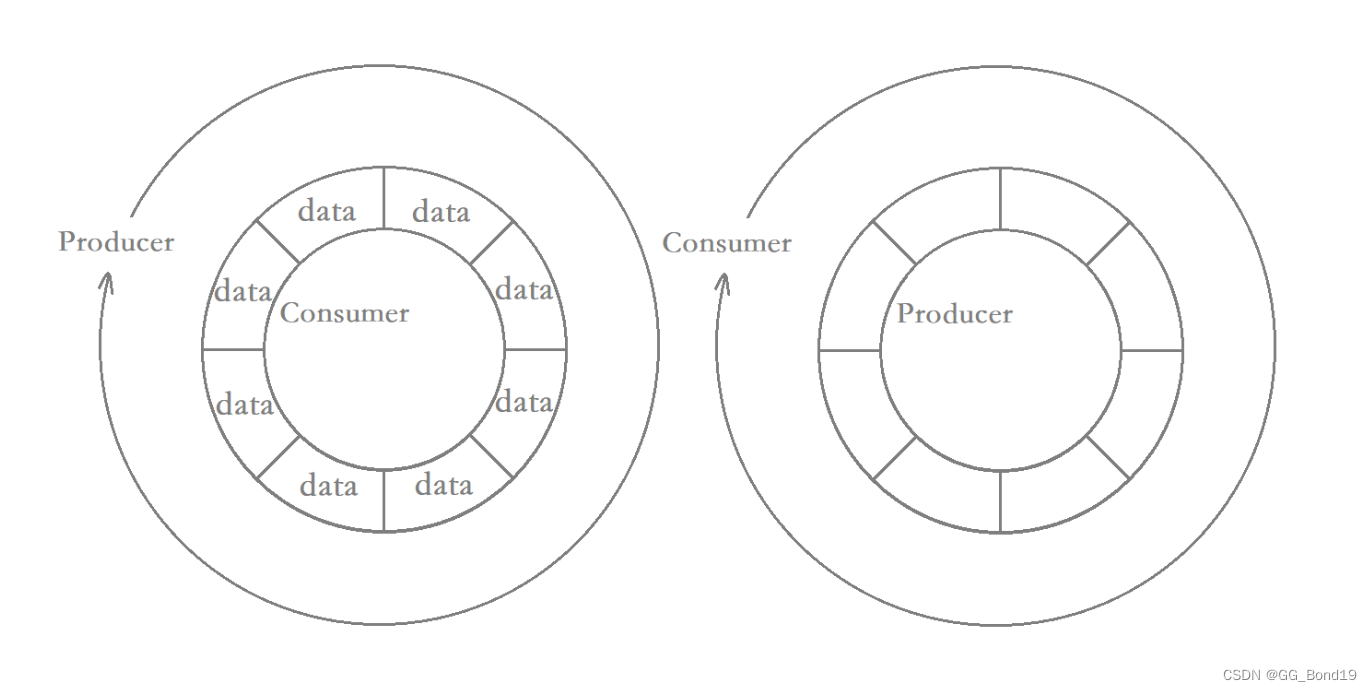
生产者消费者模型需要抓住“三个主体,三个要点“,三个主体是指:生产者、消费者、缓冲区。生产者往缓冲区放数据,消费者从缓冲区取数据。

整个模型大致就是上面图示的结构。
三个要点是指:
- 缓冲区有固定大小
- 缓冲区满时,生产者不能再往缓冲区放数据(产品),而是被阻塞,直到缓冲区不是满的
- 缓冲区为空时,消费者不能再从缓冲区取数据,而是被阻塞,直到缓冲区不是空的。
因为数据(产品)往往是先生产出来的先被消费。所以缓冲区一般用有界队列实现,又由于生产者、消费者在特定情况下需要被阻塞,所以更具体一点,缓冲区一般用有界阻塞队列来实现。
本篇用三种方式实现生产者-消费者模型:wait/notify + 队列、Lock/Condition + 队列、有界阻塞队列。
wait/notify + 队列
实现生产者-消费者模型,主要是实现两个核心方法:往缓冲区中放元素、从缓冲区中取元素。
以下是缓冲区的代码实现,是生产者-消费者模型的核心。
import java.util.LinkedList;
import java.util.Queue;/*** wait/notify机制实现生产者-消费者模型*/
public class ProducerConsumerQueue<E> {/*** 队列最大容量*/private final static int QUEUE_MAX_SIZE = 3;/*** 存放元素的队列*/private Queue<E> queue;public ProducerConsumerQueue() {queue = new LinkedList<>();}/*** 向队列中添加元素** @param e* @return*/public synchronized boolean put(E e) {// 如果队列是已满,则阻塞当前线程while (queue.size() == QUEUE_MAX_SIZE) {try {wait();} catch (InterruptedException e1) {e1.printStackTrace();}}// 队列未满,放入元素,并且通知消费线程queue.offer(e);System.out.println(Thread.currentThread().getName() + " -> 生产元素,元素个数为:" + queue.size());notify();return true;}/*** 从队列中获取元素* @return*/public synchronized E get() {// 如果队列是空的,则阻塞当前线程while (queue.isEmpty()) {try {wait();} catch (InterruptedException e) {e.printStackTrace();}}// 队列非空,取出元素,并通知生产者线程E e = queue.poll();System.out.println(Thread.currentThread().getName() + " -> 消费元素,元素个数为:" + queue.size());notify();return e;}
}
实现了缓冲区后,对于生产者、消费者线程的实现就比较简单了
/*** 生产者线程*/
public class Producer implements Runnable {private ProducerConsumerQueue<Integer> queue;public Producer(ProducerConsumerQueue<Integer> queue) {this.queue = queue;}@Overridepublic void run() {for (int i = 0; i < 10; i++) {queue.put(i);}}
}/*** 消费者线程*/
public class Consumer implements Runnable {private ProducerConsumerQueue<Integer> queue;public Consumer(ProducerConsumerQueue<Integer> queue) {this.queue = queue;}@Overridepublic void run() {for (int i = 0; i < 10; i++) {queue.get();}}
}
测试代码如下:
import java.util.Random;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public class ProducerConsumerDemo {private final static ExecutorService service = Executors.newCachedThreadPool();public static void main(String[] args) throws InterruptedException {Random random = new Random();// 生产者-消费者模型缓冲区ProducerConsumerQueue<Integer> queue = new ProducerConsumerQueue<>();Producer producer = new Producer(queue);Consumer consumer = new Consumer(queue);for (int i = 0; i < 3; i++) {// 休眠0-50毫秒,增加随机性Thread.sleep(random.nextInt(50));service.submit(producer);}for (int i = 0; i < 3; i++) {// 休眠0-50毫秒,增加随机性Thread.sleep(random.nextInt(50));service.submit(consumer);}// 关闭线程池service.shutdown();}
}
执行结果(由于执行结果比较长,所以截取部分结果)
pool-1-thread-1 -> 生产元素,元素个数为:1
pool-1-thread-1 -> 生产元素,元素个数为:2
pool-1-thread-1 -> 生产元素,元素个数为:3
pool-1-thread-4 -> 消费元素,元素个数为:2
pool-1-thread-1 -> 生产元素,元素个数为:3
pool-1-thread-4 -> 消费元素,元素个数为:2
pool-1-thread-3 -> 生产元素,元素个数为:3
pool-1-thread-4 -> 消费元素,元素个数为:2
pool-1-thread-4 -> 消费元素,元素个数为:1
pool-1-thread-4 -> 消费元素,元素个数为:0
pool-1-thread-2 -> 生产元素,元素个数为:1
pool-1-thread-2 -> 生产元素,元素个数为:2
pool-1-thread-2 -> 生产元素,元素个数为:3
pool-1-thread-4 -> 消费元素,元素个数为:2
......
虽然是部分结果,但是依然可以看出几点:
- 由于队列的最大长度是3(
QUEUE_MAX_SIZE),所以缓冲区元素不会超过3,说明缓冲区满时,生产者确实被阻塞了 - 缓冲区元素个数最小为0,不会出现负数,说明缓冲区为空时,消费者被阻塞了
这就是生产者-消费者模型基于wait/notify+队列的基本实现。
Lock/Condition + 队列
同样,核心部分缓冲区的实现代码实现如下:
import java.util.LinkedList;
import java.util.Queue;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;/*** Lock/Condition实现生产者-消费者模型*/
public class ProducerConsumerQueue<E> {/*** 队列最大容量*/private final static int QUEUE_MAX_SIZE = 3;/*** 存放元素的队列*/private Queue<E> queue;private final Lock lock = new ReentrantLock();private final Condition producerCondition = lock.newCondition();private final Condition consumerCondition = lock.newCondition();public ProducerConsumerQueue() {queue = new LinkedList<>();}/*** 向队列中添加元素* @param e* @return*/public boolean put(E e) {final Lock lock = this.lock;lock.lock();try {while (queue.size() == QUEUE_MAX_SIZE) {// 队列已满try {producerCondition.await();} catch (InterruptedException e1) {e1.printStackTrace();}}queue.offer(e);System.out.println(Thread.currentThread().getName() + " -> 生产元素,元素个数为:" + queue.size());consumerCondition.signal();} finally {lock.unlock();}return true;}/*** 从队列中取出元素* @return*/public E get() {final Lock lock = this.lock;lock.lock();try {while (queue.isEmpty()) {// 队列为空try {consumerCondition.await();} catch (InterruptedException e1) {e1.printStackTrace();}}E e = queue.poll();System.out.println(Thread.currentThread().getName() + " -> 消费元素,元素个数为:" + queue.size());producerCondition.signal();return e;} finally {lock.unlock();}}
}
可以看到,代码基本和wait/notify实现方式一致,基本只是API的不同而已。生产者线程、消费者线程、测试代码更是和wait/notify方式一致,所以就不赘述了。
有界阻塞队列
同样,缓冲区的实现也是其核心部分,不过阻塞队列已经提供了相应的阻塞API,所以不需要额外编写阻塞部分的代码
/*** 阻塞队列实现生产者-消费者模型* 对应的阻塞方法是put()/take()*/
public class ProducerConsumerQueue<E> {/*** 队列最大容量*/private final static int QUEUE_MAX_SIZE = 3;/*** 存放元素的队列*/private BlockingQueue<E> queue;public ProducerConsumerQueue() {queue = new LinkedBlockingQueue<>(QUEUE_MAX_SIZE);}/*** 向队列中添加元素* @param e* @return*/public boolean put(E e) {try {queue.put(e);System.out.println(Thread.currentThread().getName() + " -> 生产元素,元素个数为:" + queue.size());} catch (InterruptedException e1) {e1.printStackTrace();}return true;}/*** 从队列中取出元素* @return*/public E get() {try {E e = queue.take();System.out.println(Thread.currentThread().getName() + " -> 消费元素,元素个数为:" + queue.size());return e;} catch (InterruptedException e1) {e1.printStackTrace();}return null;}
}
生产者线程、消费者线程、测试代码也和前面两种一模一样。
总结
通过三种方式实现生产者-消费者模型,可以看出使用阻塞队列的方式最简单,也更安全。其实看看阻塞队列的源码,会发现其内部的实现和这里的前两种差不多,只是JDK提供的阻塞队列健壮性更好。
说完了三种实现方式,再来说说为什么要使用生产者-消费者模式,消费者直接调用生产者不好吗?
回顾文章开始的那张图,试想一下,如果没有生产者-消费者模式会怎样,大概会变成如下这样

可以看到,三个生产者,三个消费者就会产生 3 * 3 = 9条调用关系(箭头方法代表数据走向),还有一点就是消费者也有可能还是生产者,生产者也有可能还是消费者,一旦生产者、消费者的数量多了之后就会形成复杂的调用网。所以生产者-消费者模型的最大好处就是解耦。
其次如果生产者和消费者的速度上有较大的差异,就一定会存在一方总是在等待另一方的情况。比如快递小哥如果每一个快递都必须直接送到用户手上,如果某个用户一直联系不上,或者说过了很久才取快递,那么快递小哥就只能一直等待。所以就出现了快递站,快递小哥只需要把快递放在指定位置,用户去指定位置取就行了。所以生产者-消费者模型的第二个好处就是平衡生产能力和消费能力的差异。
以上就是本篇关于生产者-消费者模型的全部内容。