1. 创建表:
-- Create table
create table TEST_USER
(user_id NUMBER(3),user_name VARCHAR2(20),user_age NUMBER(3)
)
tablespace GUAN_TABLESPACEpctfree 10initrans 1maxtrans 255storage(initial 64Knext 1Mminextents 1maxextents unlimited);--测试数据
insert into TEST_USER (USER_ID, USER_NAME, USER_AGE)
values (1, '小明', 22);insert into TEST_USER (USER_ID, USER_NAME, USER_AGE)
values (2, '小芳', 23);insert into TEST_USER (USER_ID, USER_NAME, USER_AGE)
values (3, '小李', 19);insert into TEST_USER (USER_ID, USER_NAME, USER_AGE)
values (4, '李四', 30);insert into TEST_USER (USER_ID, USER_NAME, USER_AGE)
values (5, '小芳', 32);insert into TEST_USER (USER_ID, USER_NAME, USER_AGE)
values (6, '小芳', 30);2. 两种去重方法:
--方法1:
--常用的关键字:distinct
--缺点:只能应对单个字段去重,多个字段查询还是会有重复数据
select distinct t.user_name, t.user_age from TEST_USER t;--方法2:
--思路:给重复的数据建立有序下标,然后只查询下标为:1的数据即可
select f.user_name, f.user_agefrom (select t.*,row_number() over(partition by user_name order by user_name) as group_idxfrom TEST_USER t) fwhere f.group_idx = 1;
方法1查询结果: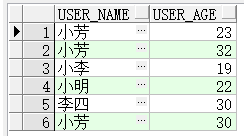
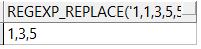
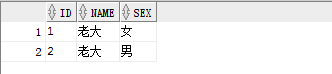
方法2查询结果:








![[mysql]linux服务器mysql默认密码查看](https://img-blog.csdnimg.cn/20210826132857460.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_Q1NETiBAUGluY2tuZXlfRW1peWE=,size_21,color_FFFFFF,t_70,g_se,x_16)