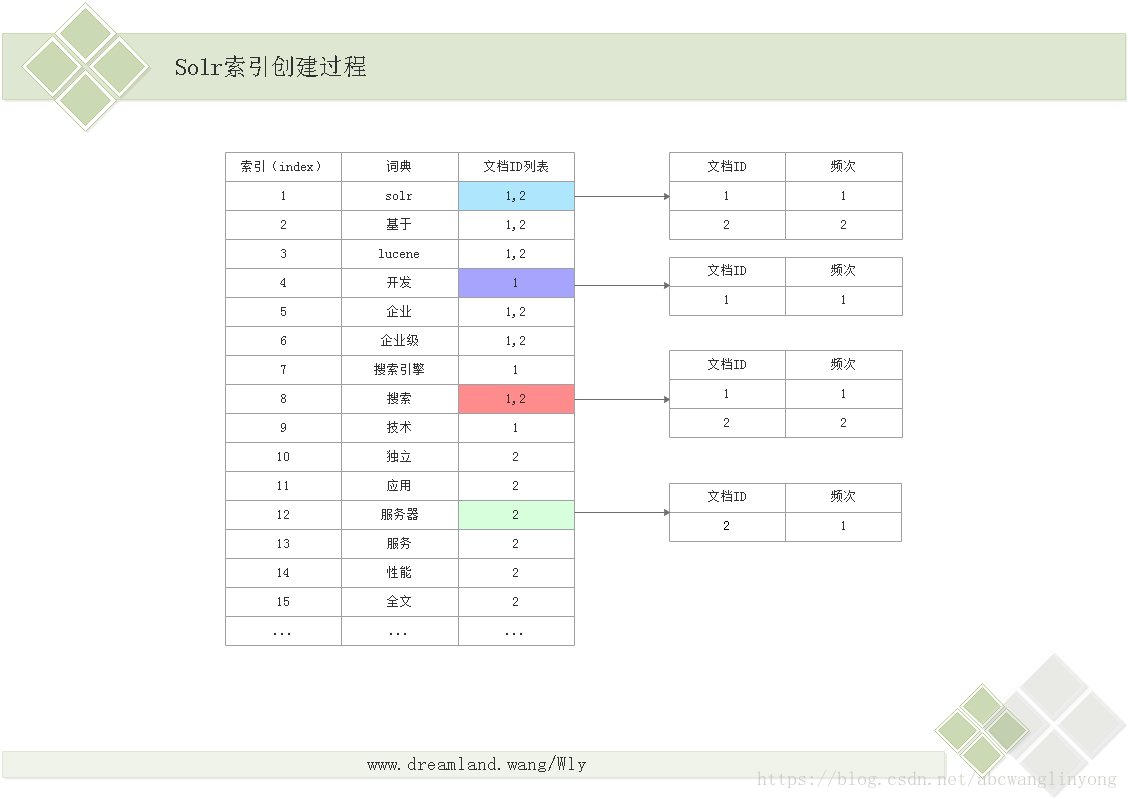
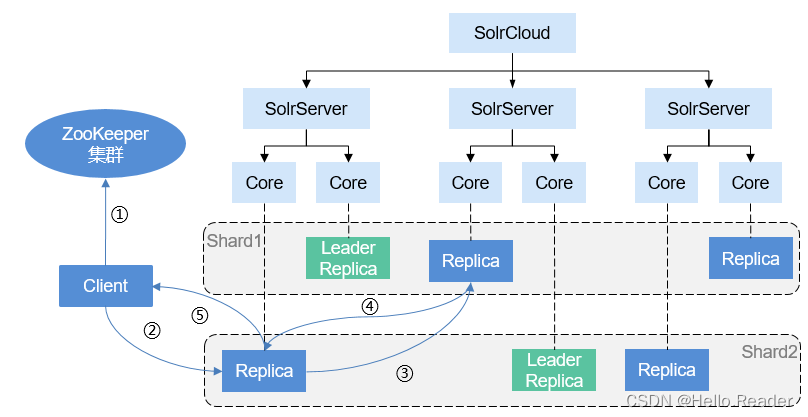
Solr集群启动,都做了哪些事情?做了很多事,over。 启动流程大致如下:
1. 启动入口:web.xml。Solr归根结底是个Web服务,必须部署到jetty或者tomcat容器上。
2. SolrRequestFilter过滤器的实现类是org.apache.solr.servlet.SolrDispatchFilter。
<!-- Any path (name) registered in solrconfig.xml will be sent to that filter --><filter><filter-name>SolrRequestFilter</filter-name><filter-class>org.apache.solr.servlet.SolrDispatchFilter</filter-class><!--Exclude patterns is a list of directories that would be short circuited by the SolrDispatchFilter. It includes all Admin UI related static content.NOTE: It is NOT a pattern but only matches the start of the HTTP ServletPath.--><init-param><param-name>excludePatterns</param-name><param-value>/css/.+,/js/.+,/img/.+,/tpl/.+</param-value></init-param></filter><filter-mapping><!--NOTE: When using multicore, /admin JSP URLs with a core specifiedsuch as /solr/coreName/admin/stats.jsp get forwarded by aRequestDispatcher to /solr/admin/stats.jsp with the specified coreput into request scope keyed as "org.apache.solr.SolrCore".It is unnecessary, and potentially problematic, to have the SolrDispatchFilterconfigured to also filter on forwards. Do not configurethis dispatcher as <dispatcher>FORWARD</dispatcher>.--><filter-name>SolrRequestFilter</filter-name><url-pattern>/*</url-pattern></filter-mapping>
3. [SolrDispatchFilter] 既然是个Filter,就要实现init(),doFilter()和destroy()三个方法。
package javax.servlet;import java.io.IOException;
import javax.servlet.FilterChain;
import javax.servlet.FilterConfig;
import javax.servlet.ServletException;
import javax.servlet.ServletRequest;
import javax.servlet.ServletResponse;public interface Filter {void init(FilterConfig var1) throws ServletException;void doFilter(ServletRequest var1, ServletResponse var2, FilterChain var3) throws IOException, ServletException;void destroy();
}
4. [SolrDispatchFilter] 在init()方法中,初始化cores,并开始加载这些cores。请注意,load()方法是最重要的加载Solr Core的方法。
/*** Override this to change CoreContainer initialization* @return a CoreContainer to hold this server's cores*/protected CoreContainer createCoreContainer(Path solrHome, Properties extraProperties) {NodeConfig nodeConfig = loadNodeConfig(solrHome, extraProperties); // 从ZK读取solr.xml配置文件到nodeConfig中cores = new CoreContainer(nodeConfig, extraProperties, true);cores.load();return cores;}
5. [SolrDispatchFilter] 实际项目可以在createCoreContainer方法尝试加载Cores之后,另外启动一个线程去recovery failed cores,来再一次尝试加载load失败的Solr cores。
6. [CoreContainer] load()方法首先会通过initZooKeeper函数初始化ZK得到一个ZkController实例。
7. [CoreContainer] coresLocator.discover(this)是去遍历Solr Home目录下有哪些cores需要去加载的。
// 这里真正开始加载Solr Cores// setup executor to load cores in parallelExecutorService coreLoadExecutor = ExecutorUtil.newMDCAwareFixedThreadPool(cfg.getCoreLoadThreadCount(isZooKeeperAware()),new DefaultSolrThreadFactory("coreLoadExecutor") );final List<Future<SolrCore>> futures = new ArrayList<>();try {// 遍历Solr Home,发现需要加载的coresList<CoreDescriptor> cds = coresLocator.discover(this);if (isZooKeeperAware()) {//sort the cores if it is in SolrCloud. In standalone node the order does not matterCoreSorter coreComparator = new CoreSorter().init(this);cds = new ArrayList<>(cds);//make a copyCollections.sort(cds, coreComparator::compare); // 对集合中的Core排序}checkForDuplicateCoreNames(cds);
hdfs是个single shard single replica的索引,发现在日志中会打印:
2018-12-10 09:52:16,581 | INFO | localhost-startStop-1 | Looking for core definitions underneath /srv/BigData/solr/solrserveradmin | org.apache.solr.core.CorePropertiesLocator.discover(CorePropertiesLocator.java:125)
2018-12-10 09:52:16,610 | INFO | localhost-startStop-1 | Found 1 core definitions | org.apache.solr.core.CorePropertiesLocator.discover(CorePropertiesLocator.java:158)
Solr实例中的状态如下:
host1:~ # ll /srv/BigData/solr/solrserveradmin/hdfs_shard1_replica1/
total 4
-rw------- 1 omm wheel 190 Dec 10 09:49 core.properties
host1:~ # cat /srv/BigData/solr/solrserveradmin/hdfs_shard1_replica1/core.properties
#Written by CorePropertiesLocator
#Mon Dec 10 09:49:09 CST 2018
numShards=1
collection.configName=confWithHDFS
name=hdfs_shard1_replica1
shard=shard1
collection=hdfs
coreNodeName=core_node1
8. [CoreContainer] 然后启动一个线程池去并行加载Cores(SolrCloud模式下是8个并发线程)
// 开始加载Cores咯!按顺序遍历所有找到的Coresfor (final CoreDescriptor cd : cds) {if (cd.isTransient() || !cd.isLoadOnStartup()) {solrCores.putDynamicDescriptor(cd.getName(), cd);} else if (asyncSolrCoreLoad) {solrCores.markCoreAsLoading(cd);}if (cd.isLoadOnStartup()) {futures.add(coreLoadExecutor.submit(() -> {SolrCore core;try {if (zkSys.getZkController() != null) {zkSys.getZkController().throwErrorIfReplicaReplaced(cd);}// 根据coreDe去创建core,false表示暂时不往ZK注册。下面会有更详细的解析。core = create(cd, false);} finally {if (asyncSolrCoreLoad) {solrCores.markCoreAsNotLoading(cd);}}try {// 这边往ZK注册!!!真正往Cluster中加载shard,主要做如下三件事:// 1. Shard leader选举// 2. 复读TLog重放数据,恢复现场,保证数据一致性// 3. 完成数据的恢复(leader数据会迁移到副本),这个恢复动作是后台运行的zkSys.registerInZk(core, true);} catch (RuntimeException e) {SolrException.log(log, "Error registering SolrCore", e);}return core;}));}}// 结束加载Core咯!// Start the background threadbackgroundCloser = new CloserThread(this, solrCores, cfg);backgroundCloser.start();} finally {if (asyncSolrCoreLoad && futures != null) {coreContainerWorkExecutor.submit((Runnable) () -> {try {for (Future<SolrCore> future : futures) {try {future.get();} catch (InterruptedException e) {Thread.currentThread().interrupt();} catch (ExecutionException e) {log.error("Error waiting for SolrCore to be created", e);}}} finally {ExecutorUtil.shutdownAndAwaitTermination(coreLoadExecutor);}});} else {ExecutorUtil.shutdownAndAwaitTermination(coreLoadExecutor);}}if (isZooKeeperAware()) {zkSys.getZkController().checkOverseerDesignate();}
9. [CoreContainer] 下面详细对create方法和registerInZk方法做一个介绍。
先来看看create方法。
方法注解写着Creates a new core based on a CoreDescriptor,简洁明了。
- create里面的preRegister方法首先会将该core的状态设置为DOWN状态
- 因为传入的publishState是false,则该core暂时不会去往ZK注册(往ZK注册会涉及到Shard Leader选举)
/*** Creates a new core based on a CoreDescriptor.** @param dcore a core descriptor* @param publishState publish core state to the cluster if true** @return the newly created core*/private SolrCore create(CoreDescriptor dcore, boolean publishState) {if (isShutDown) {throw new SolrException(ErrorCode.SERVICE_UNAVAILABLE, "Solr has been shutdown.");}SolrCore core = null;try {MDCLoggingContext.setCore(core);SolrIdentifierValidator.validateCoreName(dcore.getName());if (zkSys.getZkController() != null) {// 1. 向ZK的overseerJobQueue队列/overseer/queue发布该core的信息包括DOWN状态;// 2. 通知zkStateReader要watch该core所在collection的state.json的监控zkSys.getZkController().preRegister(dcore);}ConfigSet coreConfig = coreConfigService.getConfig(dcore);log.info("Creating SolrCore '{}' using configuration from {}", dcore.getName(), coreConfig.getName());core = new SolrCore(dcore, coreConfig);MDCLoggingContext.setCore(core);// always kick off recovery if we are in non-Cloud modeif (!isZooKeeperAware() && core.getUpdateHandler().getUpdateLog() != null) {core.getUpdateHandler().getUpdateLog().recoverFromLog();}// 注意create方法传入的参数是false,因此不会在下面的方法中去调用zkSys.registerInZk()往ZK注册。registerCore(dcore.getName(), core, publishState);return core;} catch (Exception e) {coreInitFailures.put(dcore.getName(), new CoreLoadFailure(dcore, e));log.error("Error creating core [{}]: {}", dcore.getName(), e.getMessage(), e);final SolrException solrException = new SolrException(ErrorCode.SERVER_ERROR, "Unable to create core [" + dcore.getName() + "]", e);if(core != null && !core.isClosed())IOUtils.closeQuietly(core);throw solrException;} catch (Throwable t) {SolrException e = new SolrException(ErrorCode.SERVER_ERROR, "JVM Error creating core [" + dcore.getName() + "]: " + t.getMessage(), t);log.error("Error creating core [{}]: {}", dcore.getName(), t.getMessage(), t);coreInitFailures.put(dcore.getName(), new CoreLoadFailure(dcore, e));if(core != null && !core.isClosed())IOUtils.closeQuietly(core);throw t;} finally {MDCLoggingContext.clear();}}
10. [CoreContainer->ZkContainer->ZkController] registerInZk方法,会调用zkController.register(core.getName(), core.getCoreDescriptor())会在后台新启一个线程去执行,不影响Solr启动。
具体主要做了如下三件事。具体主要做了如下三件事。
- 进行Shard Leader选举!!!最近刚看过选举机制,很简单,mzxid最小的就是leader。
- 接下来,会从ULog重放数据,恢复现场
- 判断是否需要恢复数据
/**4. Register shard with ZooKeeper.5. 6. @return the shardId for the SolrCore*/public String register(String coreName, final CoreDescriptor desc) throws Exception {return register(coreName, desc, false, false);}/**6. Register shard with ZooKeeper.7. 9. @return the shardId for the SolrCore*/public String register(String coreName, final CoreDescriptor desc, boolean recoverReloadedCores, boolean afterExpiration) throws Exception {try (SolrCore core = cc.getCore(desc.getName())) {MDCLoggingContext.setCore(core);}try {// pre register has published our down statefinal String baseUrl = getBaseUrl();final CloudDescriptor cloudDesc = desc.getCloudDescriptor();final String collection = cloudDesc.getCollectionName();final String coreZkNodeName = desc.getCloudDescriptor().getCoreNodeName();assert coreZkNodeName != null : "we should have a coreNodeName by now";String shardId = cloudDesc.getShardId();Map<String,Object> props = new HashMap<>();// we only put a subset of props into the leader nodeprops.put(ZkStateReader.BASE_URL_PROP, baseUrl);props.put(ZkStateReader.CORE_NAME_PROP, coreName);props.put(ZkStateReader.NODE_NAME_PROP, getNodeName());if (log.isInfoEnabled()) {log.info("Register replica - core:" + coreName + " address:" + baseUrl + " collection:"+ cloudDesc.getCollectionName() + " shard:" + shardId);}ZkNodeProps leaderProps = new ZkNodeProps(props);// 1. 进行Shard Leader选举!!!最近刚看过选举机制,很简单,mzxid最小的就是leader。try {// If we're a preferred leader, insert ourselves at the head of the queueboolean joinAtHead = false;Replica replica = zkStateReader.getClusterState().getReplica(desc.getCloudDescriptor().getCollectionName(),coreZkNodeName);if (replica != null) {joinAtHead = replica.getBool(SliceMutator.PREFERRED_LEADER_PROP, false);}joinElection(desc, afterExpiration, joinAtHead);} catch (InterruptedException e) {// Restore the interrupted statusThread.currentThread().interrupt();throw new ZooKeeperException(SolrException.ErrorCode.SERVER_ERROR, "", e);} catch (KeeperException | IOException e) {throw new ZooKeeperException(SolrException.ErrorCode.SERVER_ERROR, "", e);}// in this case, we want to wait for the leader as long as the leader might// wait for a vote, at least - but also long enough that a large cluster has// time to get its act togetherString leaderUrl = getLeader(cloudDesc, leaderVoteWait + 600000);String ourUrl = ZkCoreNodeProps.getCoreUrl(baseUrl, coreName);log.info("We are " + ourUrl + " and leader is " + leaderUrl);boolean isLeader = leaderUrl.equals(ourUrl);try (SolrCore core = cc.getCore(desc.getName())) {CoreDescriptor cd = core.getCoreDescriptor();if (SharedFsReplicationUtil.isZkAwareAndSharedFsReplication(cd) && !isLeader) {// with shared fs replication we don't init the update log until now because we need to make it read only// if we don't become the leaderDelayedInitSolrCore.initIndexReaderFactory(core);core.getUpdateHandler().setupUlog(core, null);core.getSearcher(false, false, null, true);// the leader does this in ShardLeaderElectionContext#runLeaderProcess}// 2. 接下来,会从TLog重放数据,恢复现场// recover from local transaction log and wait for it to complete before// going active// TODO: should this be moved to another thread? To recoveryStrat?// TODO: should this actually be done earlier, before (or as part of)// leader election perhaps?UpdateLog ulog = core.getUpdateHandler().getUpdateLog();// we will call register again after zk expiration and on reload if (!afterExpiration && !core.isReloaded() && ulog != null && !SharedFsReplicationUtil.isZkAwareAndSharedFsReplication(cd)) {// disable recovery in case shard is in construction state (for shard splits)Slice slice = getClusterState().getSlice(collection, shardId);if (slice.getState() != Slice.State.CONSTRUCTION || !isLeader) {Future<UpdateLog.RecoveryInfo> recoveryFuture = core.getUpdateHandler().getUpdateLog().recoverFromLog();if (recoveryFuture != null) {log.info("Replaying tlog for " + ourUrl + " during startup... NOTE: This can take a while.");recoveryFuture.get(); // NOTE: this could potentially block for// minutes or more!// TODO: public as recovering in the mean time?// TODO: in the future we could do peersync in parallel with recoverFromLog} else {log.info("No LogReplay needed for core=" + core.getName() + " baseURL=" + baseUrl);}}}// 3. 是否需要恢复数据// a. 如果是leader,则不需要recovery,直接将Replica状态发布为Replica.State.ACTIVE;// b. 如果不是leader,则判断是否需要recovery。若需要recover,新启一个线程去从leader恢复数据到同一个数据版本,此时Replica状态变成了Replica.State.RECOVERING状态。// c. 在recover完成之后,再将Replica状态发布为Replica.State.ACTIVE状态。boolean didRecovery = checkRecovery(coreName, desc, recoverReloadedCores, isLeader, cloudDesc, collection,coreZkNodeName, shardId, leaderProps, core, cc, afterExpiration);if (!didRecovery) {// 将replica的状态变成ACTIVEpublish(desc, Replica.State.ACTIVE);}core.getCoreDescriptor().getCloudDescriptor().setHasRegistered(true);}// make sure we have an update cluster state right awayzkStateReader.forceUpdateCollection(collection);return shardId;} finally {MDCLoggingContext.clear();}}
11. [ZkController] 检查是否需要recovery过程
/*** Returns whether or not a recovery was started*/private boolean checkRecovery(String coreName, final CoreDescriptor desc,boolean recoverReloadedCores, final boolean isLeader,final CloudDescriptor cloudDesc, final String collection,final String shardZkNodeName, String shardId, ZkNodeProps leaderProps,SolrCore core, CoreContainer cc, boolean afterExpiration) {if (SKIP_AUTO_RECOVERY) {log.warn("Skipping recovery according to sys prop solrcloud.skip.autorecovery");return false;}boolean doRecovery = true;// leaders don't recover, shared fs replication replicas don't recover CoreDescriptor cd = core.getCoreDescriptor();if (!isLeader && !SharedFsReplicationUtil.isZkAwareAndSharedFsReplication(cd)) {log.info("I am not the leader");if (!afterExpiration && core.isReloaded() && !recoverReloadedCores) {doRecovery = false;}if (doRecovery) {log.info("Core needs to recover:" + core.getName());// 这里会新启一个异步线程去recover,不会阻塞主线程。core.getUpdateHandler().getSolrCoreState().doRecovery(cc, core.getCoreDescriptor()); return true;}// see if the leader told us to recoverfinal Replica.State lirState = getLeaderInitiatedRecoveryState(collection, shardId,core.getCoreDescriptor().getCloudDescriptor().getCoreNodeName());if (lirState == Replica.State.DOWN) {log.info("Leader marked core " + core.getName() + " down; starting recovery process");core.getUpdateHandler().getSolrCoreState().doRecovery(cc, core.getCoreDescriptor());return true;}} else {log.info("I am the leader, no recovery necessary");}return false;}
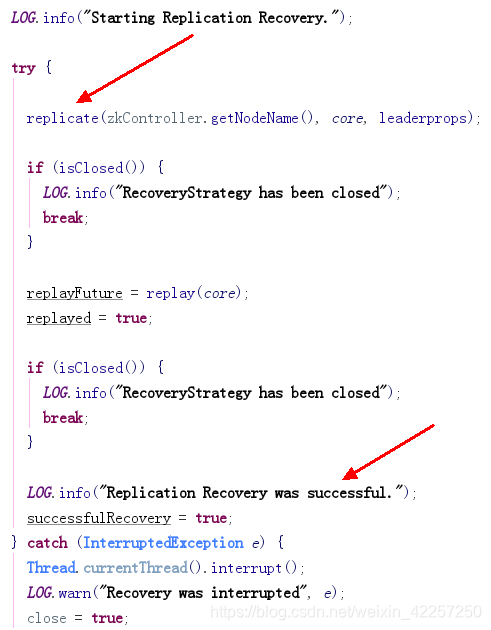
12. [RecoveryStrategy] 启动recovery线程。在recovery完成之后,再将Replica状态发布为Replica.State.ACTIVE状态。
@Overridepublic void run() {// set request info for loggingtry (SolrCore core = cc.getCore(coreName)) {if (core == null) {SolrException.log(LOG, "SolrCore not found - cannot recover:" + coreName);return;}MDCLoggingContext.setCore(core);LOG.info("Starting recovery process. recoveringAfterStartup=" + recoveringAfterStartup);try {// !!!这边开始去做Recovery!!!doRecovery(core);} catch (InterruptedException e) {Thread.currentThread().interrupt();SolrException.log(LOG, "", e);throw new ZooKeeperException(SolrException.ErrorCode.SERVER_ERROR, "", e);} catch (Exception e) {LOG.error("", e);throw new ZooKeeperException(SolrException.ErrorCode.SERVER_ERROR, "", e);}} finally {MDCLoggingContext.clear();}}
13. [RecoveryStrategy] Recovery流程介绍。
Recovery分为PeerSync和Replication两种方式。Recovery流程先尝试做PeerSync Recovery,失败的话再尝试Replication Recovery。
- PeerSync:如果中断的时间较短,recovering node只是丢失少量update请求,那么它可以从leader的update log中获取。这个临界值是100个update请求,如果大于100,就会从leader进行完整的索引快照恢复。
- Replication:如果节点下线太久以至于不能从leader那进行同步,或者如果PeerSync失败(参考这里),它就会使用Solr的基于http进行索引的快照恢复。

Reference
https://blog.csdn.net/weixin_42257250/article/details/89512282
https://www.cnblogs.com/rcfeng/p/4145349.html