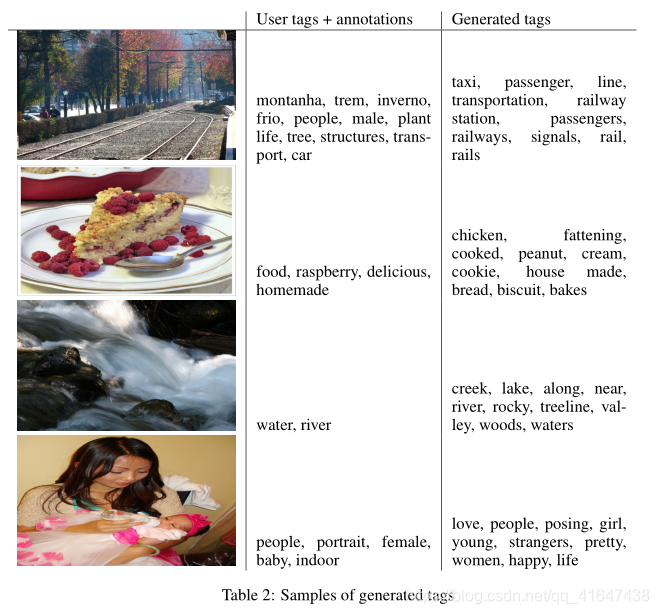
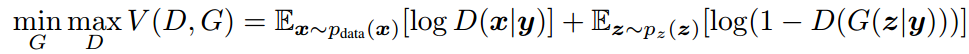本文是学习自李宏毅深度学习教程的内容,之前学习过CGAN,本文想做一些补充的内容,也算是完善下认识。
也是因为自己有强迫症。
1:网络结构稍加改变
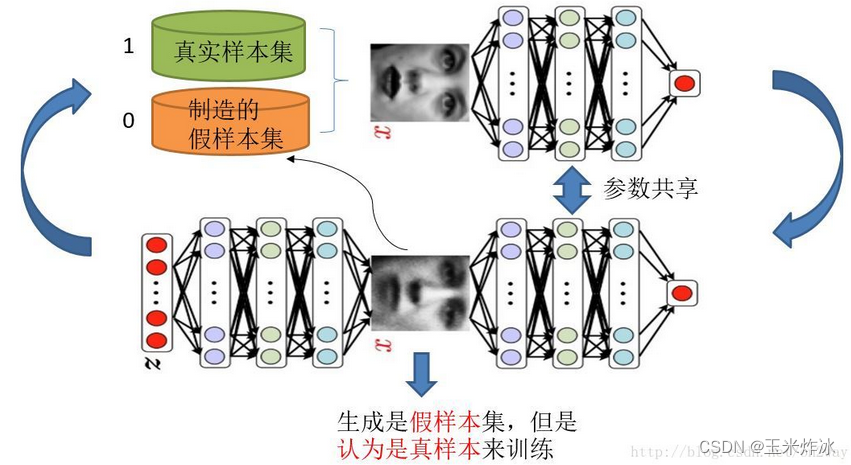
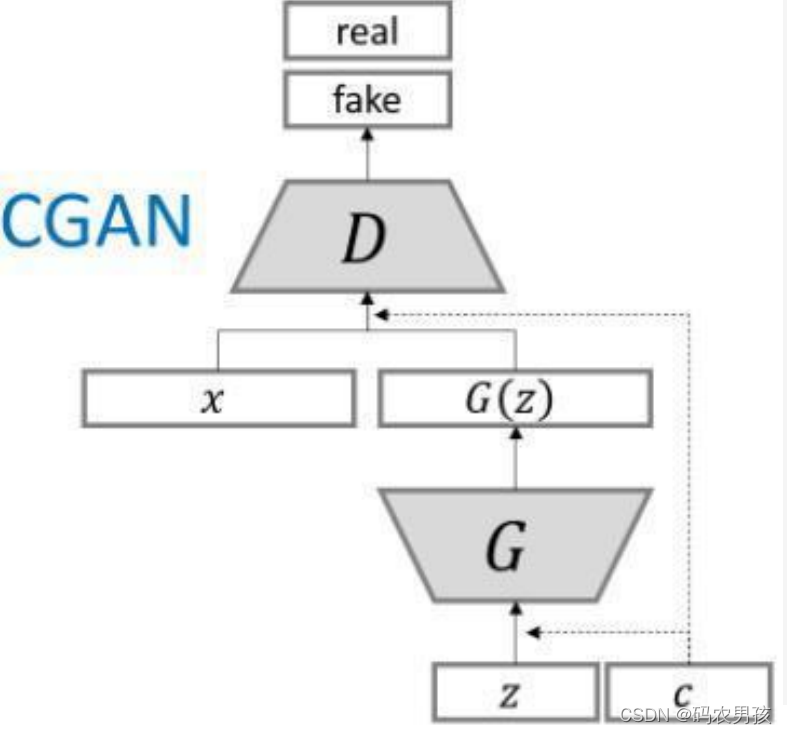
之前认识的CGAN的结构如下:
最后在D网络输入的地方,只输出一个标量,这个标量既要代表是否是真实的图片,还要代表C和Z是否是匹配的,这样做的话呢,如果给一个样本输入,最后给了个低分,我们就无法区分出到底是哪个原因导致的。
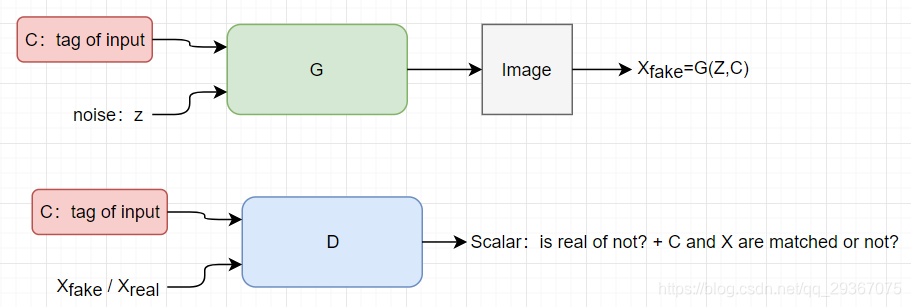
因此对D网络稍稍做了点改变就是为了使我们能区分出是哪个原因导致的,也就是输出两个标量,一个代表是真实的?另一个代表数据X和条件C是不是匹配的?

输出是两个标量,可以在基础上稍加改进,增加一个小网络结构

两个标量的含义都是容易理解的,只不过分开做了表示,在结果解释上就更加清晰明了,最后只会需要将这俩的损失和相加即可。
2:负样本来源
以前我们学的负样本来自G的构造,期望D 把G构造的X判定为不是真实数据。
现在还有一个负样本(X,C)pair是来自真实数据源本身,那就是真实的标签tag和随机采样的真实X,也就是驴唇不对马嘴,虽然D会觉得X是真实的,但是C和X不匹配,这也是不行的。所以这也是负样本。

对于G来说,没有变化,此处增加了一项负样本的计算。