MySql数据库
视图:虚拟的表 索引:目录 事务:操作
安装数据库:sudo apt install mysql-server //mysql8.0
安装C/C++开发库:sudo apt install libmysqlclient-dev
数据库:1.mysql 文件本身 2.数据库管理系统(应用程序)
C/S 模式 (客户端 / 服务器端)
stu@localhost // 本主机登录
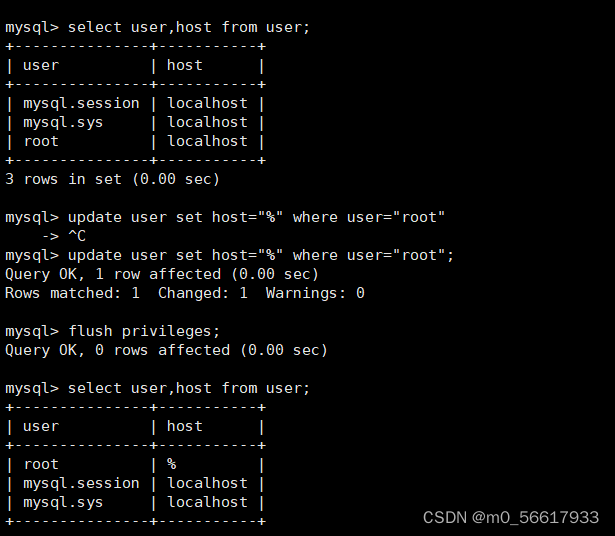
stu@% // 远程登陆
使用TCP协议链接服务器客户端 ,数据库端口号 3306
关系型数据库:oracle 、mysql 等就是采用了关系模型来组织数据的数据库,关系模型就是指二维表格模型,其核心元素:数据行、数据列、数据表、数据库。
非关系型数据库:memcahe redis 等指分布式、非关系型且一般不保证ACID原则的数据库存储系统,非关系型数据库以键值对存储,且结构不固定。(ACID是指原子性、一致性、隔离性、持久性)
ubuntu中
数据库启动:service mysql start 重启:restart
查看状态:service mysql status
数据库关闭:service mysql stop
链接数据库命令
mysql -uroot -p
没有设置过密码的情况下,直接回车就直接进去了,exit退出数据库
数据库操作
更改密码
ALTER user 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '***';
设置权限:
grant all privileges on *.* to 'root'@'%';
创建用户并设定加密方式
create user 'stu'@'localhost' IDENTIFIED WITH mysql_native_password BY '***';
查看数据库
show databases
查看表
show tables
创建数据库
creat database 名称 charset=utf8
使用数据库
use 数据库名称
创建表
create table 数据库表名(字段名 类型 约束)
查看表属性
desc 表名
插入数据
insert into 表名 values (2022,"张三");
修改数据
update 表名 set id=1001 where name="张三";
删除数据
delete from stu1 where id=1002;
查看表的数据
select * from 表名;

数据类型
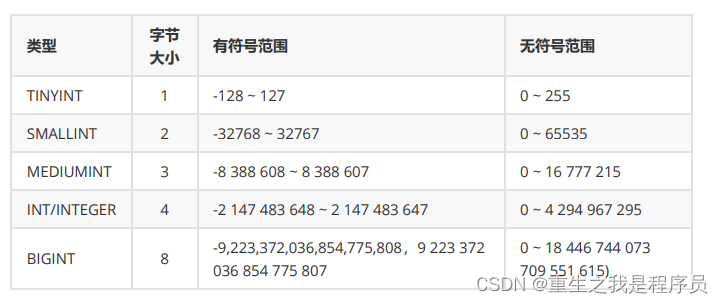
整型:
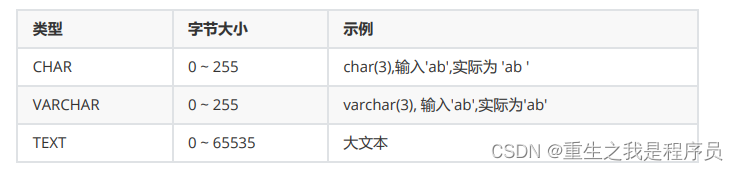
字符串:
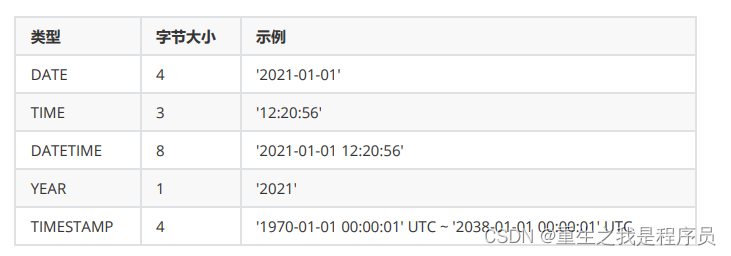
时间日期:
约束
主键:primary key 物理上存储顺序
非空:not null 此字段不允许填写空值
唯一:unique 此字段值不允许重复
默认:default 当不填写此值时使用默认值
外键:foreign key 对关系字段进行约束当为关系字段填写值时,会到关联的表中查询此值是否存 在,如果存在则写成功,如果不存在则写失败。 虽然外键约束可以保证数据的有效性,但是在进行 数据的crud(增加,修改,删除,查询)时,都会降低数据库的性能
使用c语言访问mysql
头文件:#include<mysql.h>
初始化: MYSQL *mysql_init (MYSQL * mysql);

连接数据库:mysql_real_connect(连 接 句 柄 , 本 地 主 机 登 录 , 用 户 , 密 码 , 数 据 库 名 , 端 口 , 本 地 域 套 接 字, 标 识 0);

执行sql语句: mysql_query(句柄,数组); //返回为0则成功


使用C语言打印数据库表格数据
提取数据:MYSQL_RES* r=mysql_store_result(&mysql);
获取结果集中行数:int num= mysql_num_rows( res);
记录列数:int num=mysql_field_count(&mysql);
读取一行数据:mysql_fetch_row(res);
释放集合空间:mysql_free_result(res)
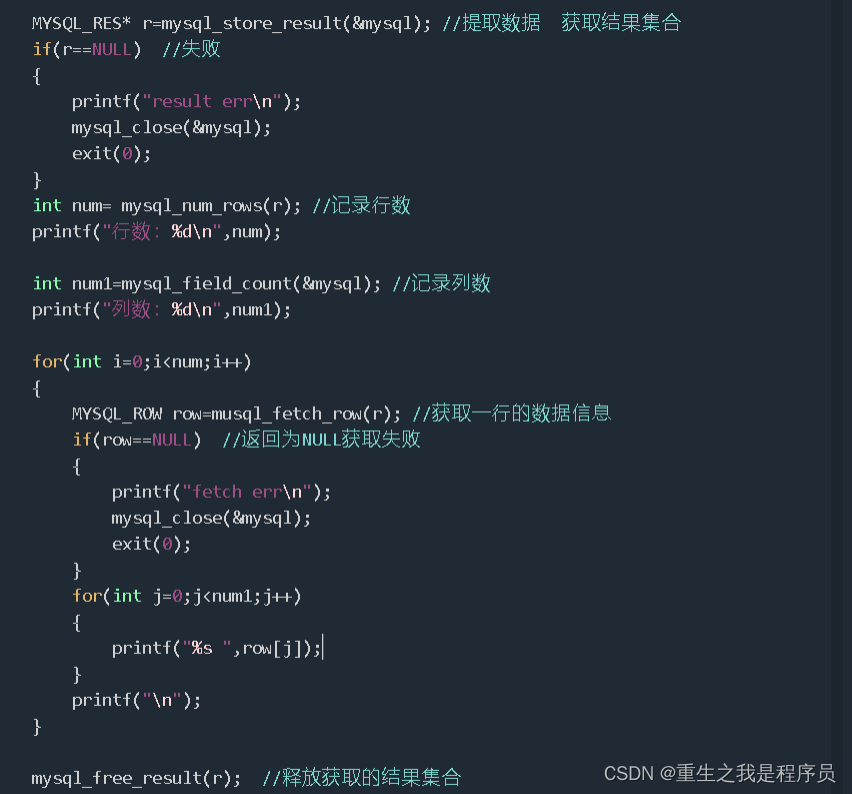
关闭数据库连接:mysql_close(句柄);

索引:是一种特殊文件,包含对数据表里所有记录的引用指针,简单讲,就是一本书的目录,能加加快查询。一般对数据库的操作是以查询为主,数据量大时,优化是关键
索引确实会让搜索数据的时间变短,但不用刻意地加很多个索引,索引修改时每个都会被修改,这样会增加运行时间,所以视情况而定,在必要的字段上加索引,没必要加很多个索引
查看数据库存储引擎:show engines;
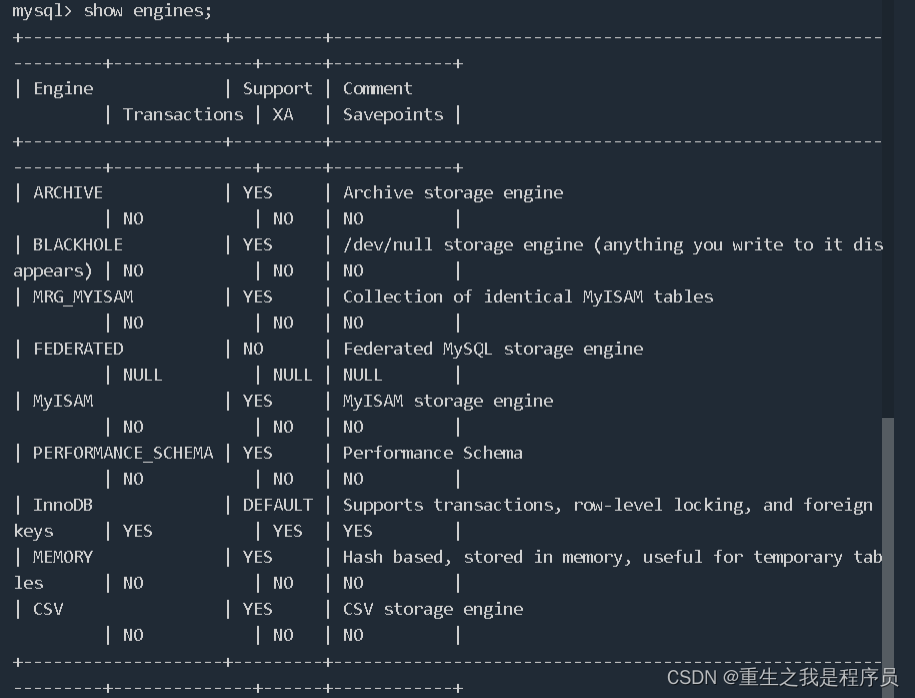
在InnoDB存储引擎中索引选用的b+树数据结构,稳定性好
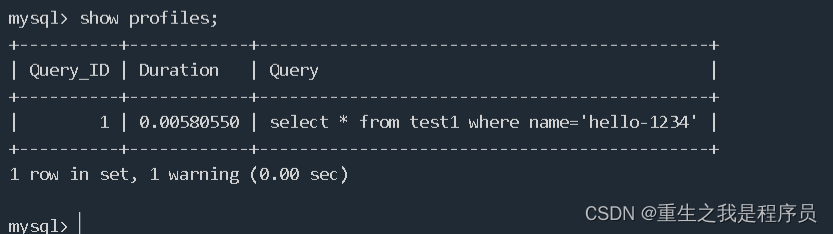
数据库开启运行时间检测:set profiling=1;
查找一条数据:select * from 表名 where title=' 数据名 ';
查看执行事件的时间:show profiles;
为表创建索引:create index 索引名 on 表名 (name(20));
创建索引之后我们可以明显看到查找时间减少了非常多
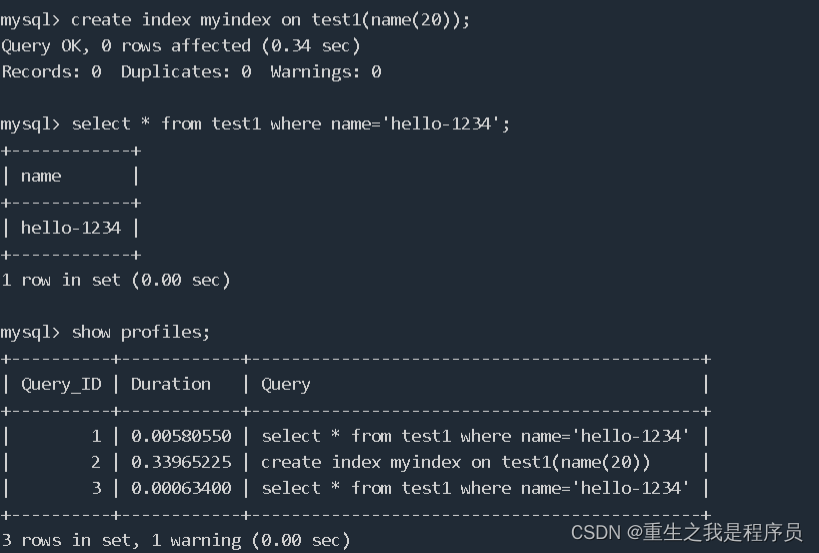
删除索引:drop index 索引名 on 表名

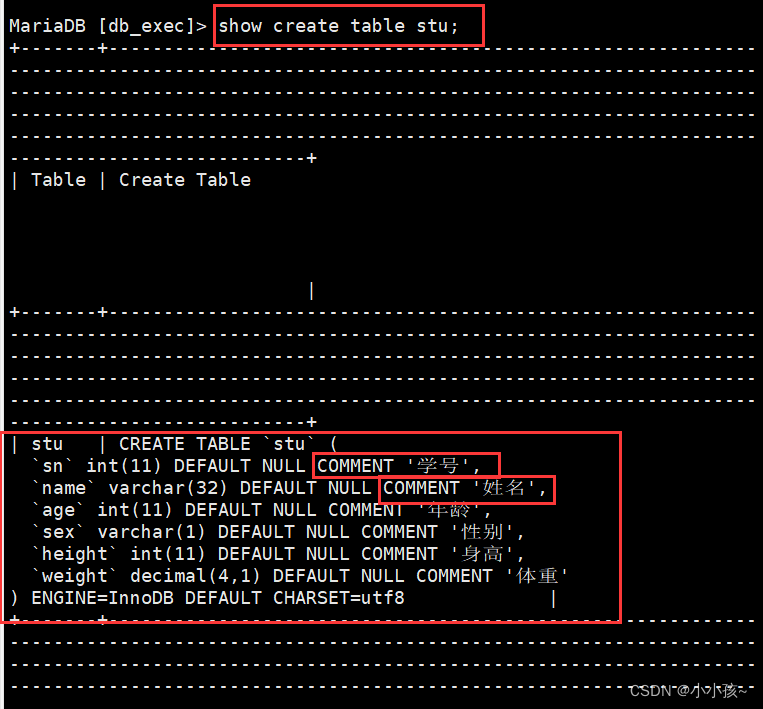
查看表信息:show create table test1;

事务:就是一组原子性的sql查询,或者说是一个独立的工作单元,事务内的语句,要么全部执行成功,要么全部执行失败
拿转账来说,转账的流程中,但凡有一步失败,钱就会到不了账户,或者钱被清空了也没到对方账户,或者自己的钱还在,对方钱也转成功了
ACID测试表示原子性、一致性、隔离性、持久性,一个运行良好的事务处理系统必须具备这些标准特性
原子性:要么成功提交,要么失败回滚
一致性:从一个正确状态转换到另一个正确状态(转200,我的账户状态少200,对方状态多200)
隔离性:事务所做的修改在最终提交之前对其他事务是不可见的
持久性:一旦事务提交,所做的 修改会永久保存在数据库中,既是系统崩溃,修改的数据不会改变
面试!!!!!隔离级别(4种级别从低到高越来越强)
1.未提交读: READ UNCOMMITTED
2.提交读:READ COMMITTED
3.可重复读:REPEATABLE 解决了脏读问题,保证了同一事物下多次读取结果一致,但有特殊情况,我们在读的时候其他人改了,但我们接收不到修改,这就是幻读
4.可串行化:SERIALIZABLE
事务命令:(必须的是InnoDB类型引擎才行)
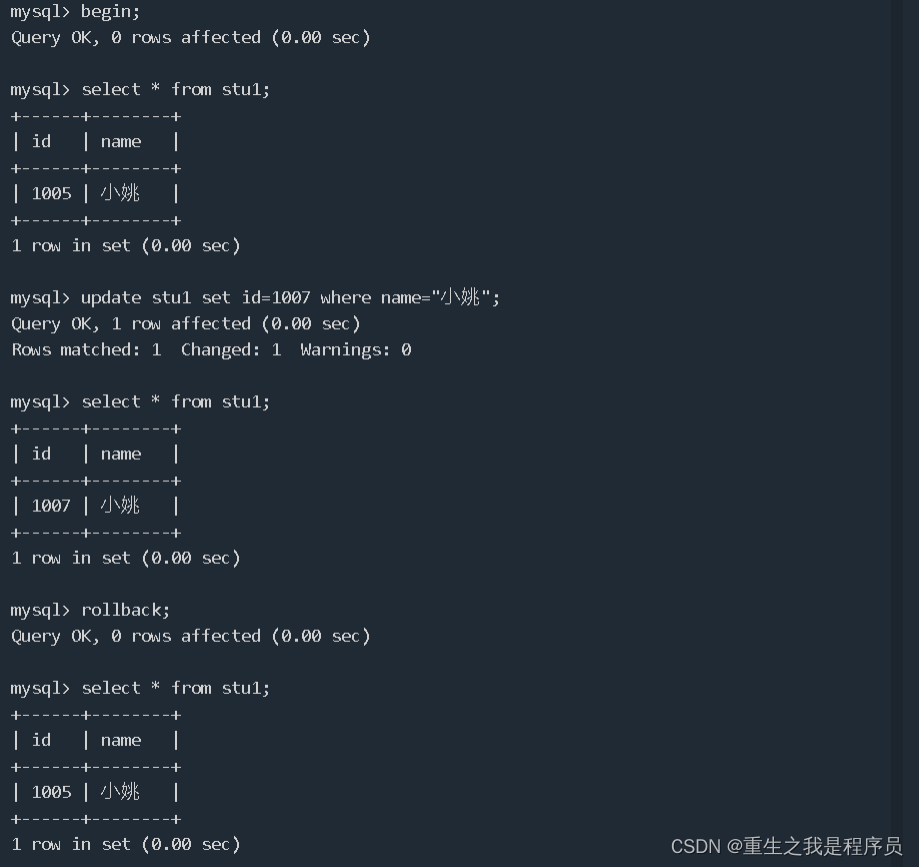
开始事务:begin;
提交事务:commit;
回滚事务:rollback;
如果不commit;则可以rollback;可以恢复
查看当前会话隔离级别:SELECT @@SESSION.transaction_isolation;
可见当前隔离级别为:可重复读(连续查询都数据都一样,别人修改不了)
设置会话隔离级别:set session transaction isolation level

查看系统的隔离级别:SELECT @@GLOBAL.transaction_isolation;
设置系统隔离级别:set global transaction isolation level
视图:虚拟的表
通过创建视图操作表更加安全一些,它不会在数据库中实际存放数据,它的数据来自定义视图时使用的基本表,并且是在使用视图时动态生成的
创建一个视图:create view v_名称 as select 类型 from 表名,表名 where 表名.id=表名.id;
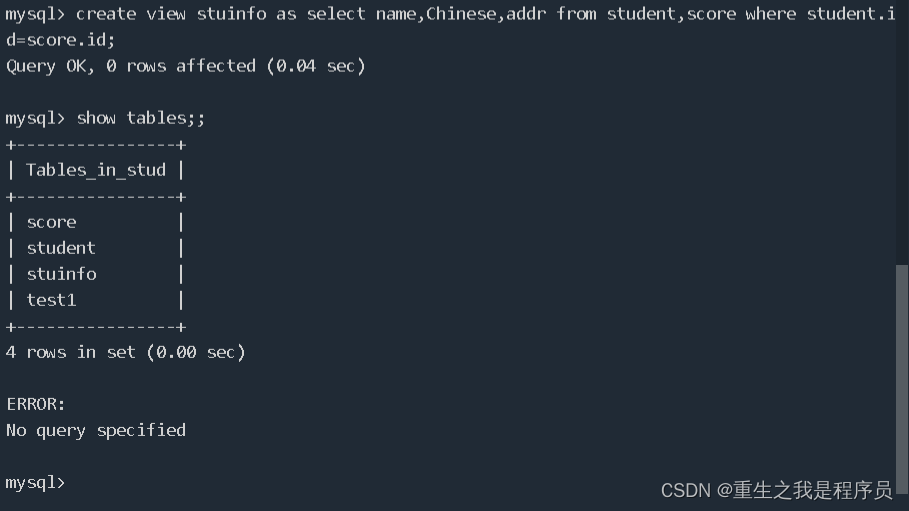
删除视图:drop view 视图名
为什么要使用视图?
1.简化复杂得sql操作,在编写查询后,可方便的重用而不用知道它的查询细节
2.重复使用sql语句
3.使用表的组成部分而不是全部
4.保护数据,可以给用户特定的权限
5.更改数据格式和表示
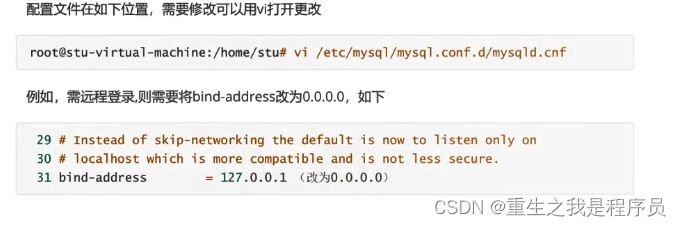
修改地址: