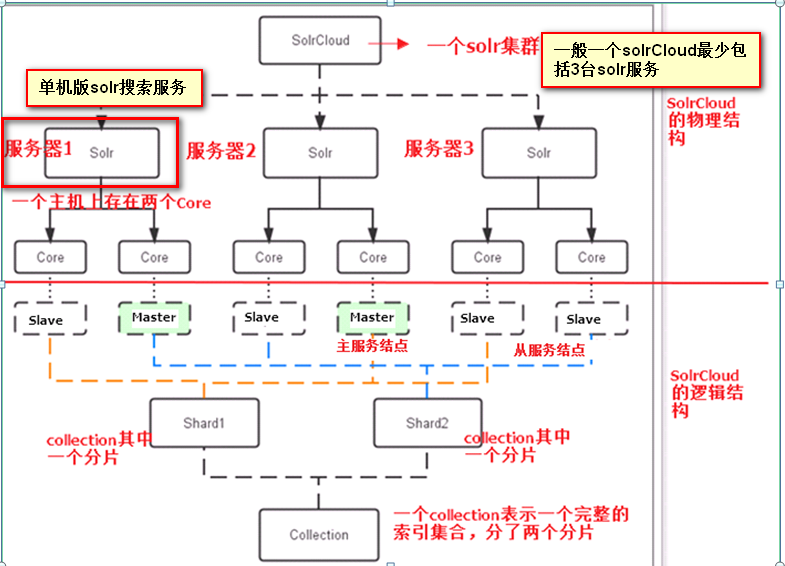
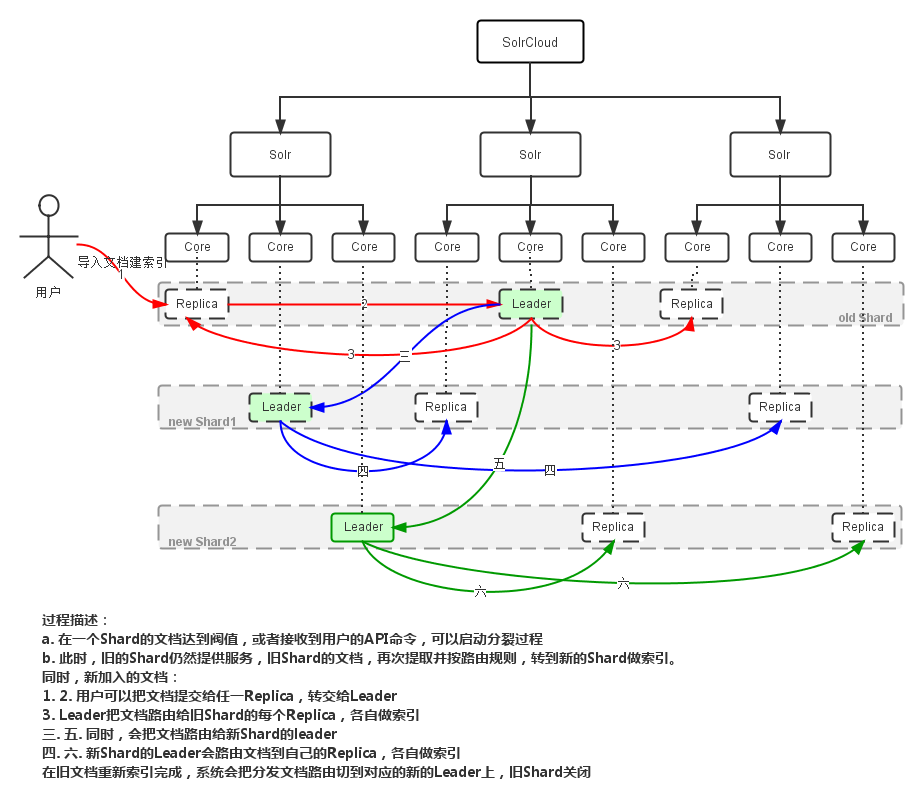
我们已经基于SolrCloud 4.3.1+Tomcat 7搭建了搜索服务器集群,一个Collection对应3个节点上的3个分片(Shard),同时包含对应分片的副本(Replica),此时,该Collection一共有6000万左右Document,平均每个分片大约接近2000万。
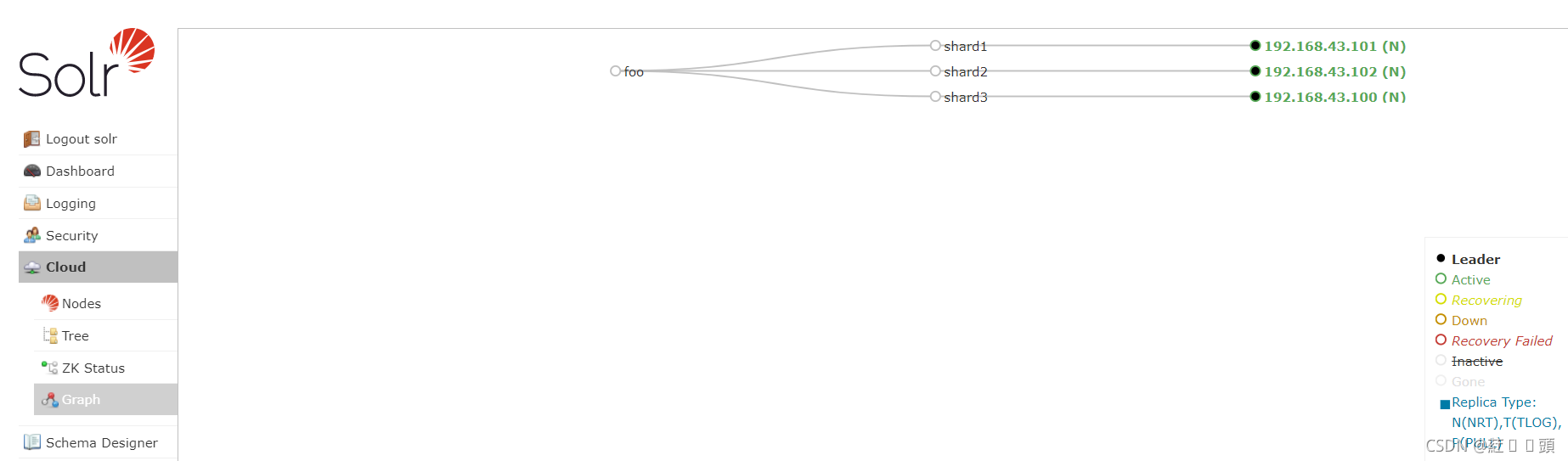
SolrCloud集群节点的具体分布,如图所示:

只有shard1有一个副本,并且位于不同的节点上。
随着索引数据量的增长,如果我们的Collection的每个分片都不断的增大,最后导致单个分片在搜索的时候,相应速度成为瓶颈,那么,我们要考虑将每个分片再次进行分片。因为第一次系统规划时已经设置好分片数量,所以每个分片所包含的Document数量几乎是相同的,也就是说,再次分片后,重新得到的分片的数量是原来的二倍。
目前,SolrCloud不支持自动分片,但是支持手动分片,而且手动分片后得到的新的分片所包含的Document数量有一定的差异(还不清楚SolrCloud是否支持手动分片后大致均分一个分片)。下面,我们看一下,在进行手动分片过程中,需要执行哪些操作,应该如何重新规划整个SolrCloud集群。
首先,我增加了一个节点(slave6 10.95.3.67),把集群中原来的配置文件、solr-cloud.war及其Tomcat服务器都拷贝到这个新增的节点上,目的是将10.95.3.62上的shard1再次分片,然后将再次得到分片运行在新增的10.95.3.67节点上。启动新增节点的Tomcat服务器,它自动去连接ZooKeeper集群,此时ZooKeeper集群增加live_nodes数量,主要是通过在Tomcat的启动脚本中增加如下内容:
| JAVA_OPTS="-server -Xmx4096m -Xms1024m -verbose:gc -Xloggc:solr_gc.log -Dsolr.solr.home=/home/hadoop/applications/solr/cloud/multicore -DzkHost=master:2188,slave1:2188,slave4:2188" |
这样,就能告知ZooKeeper集群有新节点加入SolrCloud集群。
如上图所示,我们打算将shard1进行二次手动分片,执行如下命令即可:
| curl 'http://master:8888/solr-cloud/admin/collections?action=SPLITSHARD&collection=mycollection&shard=shard1' |
这个过程花费的时间比较长,而且可能会伴有如下异常相应信息:
<?xml version="1.0" encoding="UTF-8"?>
<response>
<lst name="responseHeader"><int name="status">500</int><int name="QTime">300138</int></lst><lst name="error"><str name="msg">splitshard the collection time out:300s</str><str name="trace">org.apache.solr.common.SolrException: splitshard the collection time out:300sat org.apache.solr.handler.admin.CollectionsHandler.handleResponse(CollectionsHandler.java:166)at org.apache.solr.handler.admin.CollectionsHandler.handleSplitShardAction(CollectionsHandler.java:300)at org.apache.solr.handler.admin.CollectionsHandler.handleRequestBody(CollectionsHandler.java:136)at org.apache.solr.handler.RequestHandlerBase.handleRequest(RequestHandlerBase.java:135)at org.apache.solr.servlet.SolrDispatchFilter.handleAdminRequest(SolrDispatchFilter.java:608)at org.apache.solr.servlet.SolrDispatchFilter.doFilter(SolrDispatchFilter.java:215)at org.apache.solr.servlet.SolrDispatchFilter.doFilter(SolrDispatchFilter.java:155)at org.apache.catalina.core.ApplicationFilterChain.internalDoFilter(ApplicationFilterChain.java:243)at org.apache.catalina.core.ApplicationFilterChain.doFilter(ApplicationFilterChain.java:210)at org.apache.catalina.core.StandardWrapperValve.invoke(StandardWrapperValve.java:222)at org.apache.catalina.core.StandardContextValve.invoke(StandardContextValve.java:123)at org.apache.catalina.core.StandardHostValve.invoke(StandardHostValve.java:171)at org.apache.catalina.valves.ErrorReportValve.invoke(ErrorReportValve.java:99)at org.apache.catalina.valves.AccessLogValve.invoke(AccessLogValve.java:953)at org.apache.catalina.core.StandardEngineValve.invoke(StandardEngineValve.java:118)at org.apache.catalina.connector.CoyoteAdapter.service(CoyoteAdapter.java:408)at org.apache.coyote.http11.AbstractHttp11Processor.process(AbstractHttp11Processor.java:1023)at org.apache.coyote.AbstractProtocol$AbstractConnectionHandler.process(AbstractProtocol.java:589)at org.apache.tomcat.util.net.JIoEndpoint$SocketProcessor.run(JIoEndpoint.java:310)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)at java.lang.Thread.run(Thread.java:722)
</str><int name="code">500</int></lst>
</response>Solr这个版本,实际真正的执行手动分片的动作已经在SolrCloud集群中进行,可以忽略这个异常。我们需要注意的是,在进行手动分片的时候,尽量不要在集群操作比较频繁的时候进行,例如,我就是在保持10个线程同时进行索引的过程中进行手动分片的,观察服务器状态,资源消费量比较大,而且速度很慢。
在执行手动分片的过程中,我们可以通过Web管理页面。观察当前集群中节点的状态变化。
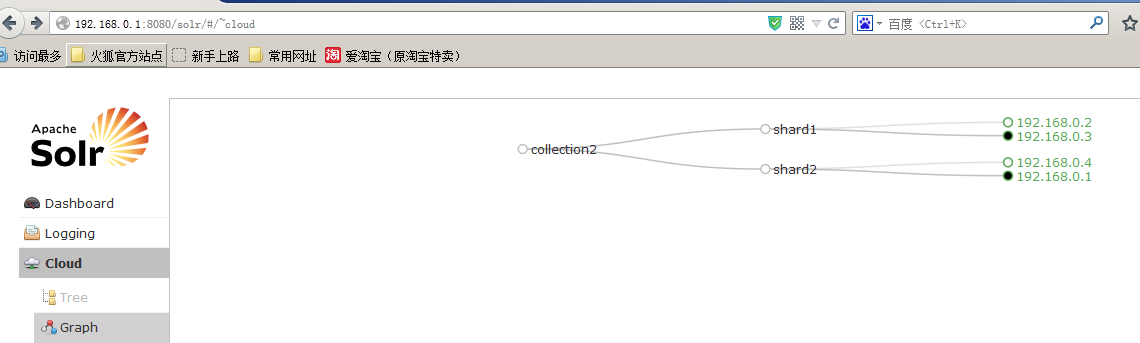
提交上面的命令以后,可以看到,集群中新增节点的状态,如图所示:

上面的状态是“Recovering”,也就是在将shard1中分成两个子分片,新增节点加入到集群,准备接收分片(或者对应的复制副本),如上图可见,shard3和shard1在新增节点上分别增加了一个副本。
接续看集群状态变化,如图所示:

在shard1所在节点(10.95.3.62)上,将shard1分成了两个子分片:shard1_0和shard1_1,此时,在10.95.3.62节点上有3个分片出于“Active”状态。实际上,到目前为止,子分片shard1_0和shard1_1已经完全接管了shard1分片,只是没有从图中自动离线退出,这个就需要我们在管理页面你上手动“unload”掉不需要的shard。
这时,新得到的两个子分片,并没有处理之前shard1的两个副本,他们也需要进行分片(实际上是重新复制新分片的副本),这个过程,如图所示:

等待“Recovering”恢复完成以后,我们就可以看到进入“Active”状态的节点图,如图所示:

手动分片的工作基本已经完成,这时候,如果继续索引新的数据,shard1及其副本不会再接收请求,所以数据已经在再次分片的子分片上,请求也会发送到那些子分片的节点上,下面需要将之前的shard1及其分片unload掉,即退出集群,要处理的分片主要包含如下几个:
| mycollection_shard1_replica1 mycollection_shard1_replica_2 mycollection_shard1_replica_3 |
一定不要操作失误,否则可能会造成索引数据丢失的。unload这几个分片以后,新的集群的节点分布,如图所示:

shard1_0和shard1_1两个新的分片,对应的副本,分别如下所示:
| mycollection_shard1_0_replica1 mycollection_shard1_0_replica2 mycollection_shard1_0_replica3 mycollection_shard1_1_replica1 mycollection_shard1_1_replica2 mycollection_shard1_1_replica3 |
下面,我们对比一下,手动二次分片以后,各个节点上Document的数量,如下表所示:
| 分片/副本名称 | 所在节点 | 文档数量 |
| mycollection_shard1_0_replica1 | 10.95.3.62 | 18839290 |
| mycollection_shard1_0_replica2 | 10.95.3.67 | 18839290 |
| mycollection_shard1_0_replica3 | 10.95.3.61 | 18839290 |
| mycollection_shard1_1_replica1 | 10.95.3.62 | 957980 |
| mycollection_shard1_1_replica2 | 10.95.3.61 | 957980 |
| mycollection_shard1_1_replica3 | 10.95.3.67 | 957980 |
| mycollection_shard2_replica1 | 10.95.3.62 | 23719916 |
| mycollection_shard3_replica1 | 10.95.3.61 | 23719739 |
| mycollection_shard3_replica1 | 10.95.3.67 | 23719739 |
可见,二次分片的shard1_1上面,Document数量相比于其它分片,十分不均。
SolrCloud也正在不断的更新中,在后续的版本可能会更多地考虑到分片的问题。另外,对于某个节点上的分片如果过大,影响了搜索效率,可以考虑另一种方案,就是重建索引,即使新增节点,重新索引再次重新分片,并均匀地分布到各个节点上。
参考链接
- http://wiki.apache.org/solr/SolrCloud#Managing_collections_via_the_Collections_API
- http://searchhub.org/2013/06/19/shard-splitting-in-solrcloud/