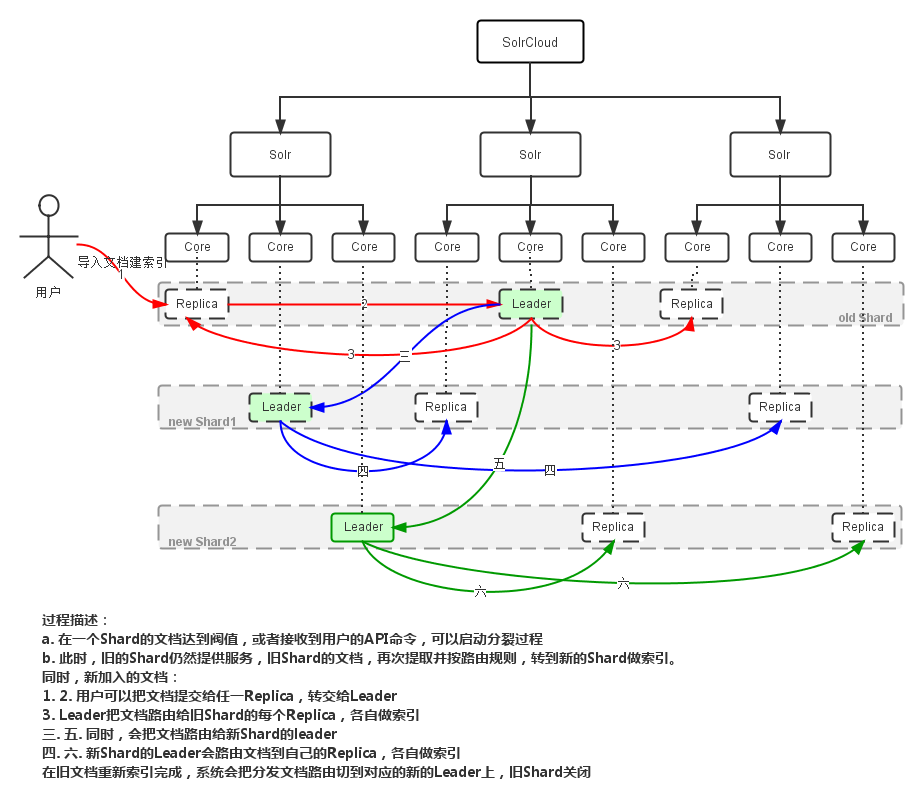
好久没写solr的文章了,刚好需要在公司作个分享,先总结一些先。
引用请声明原文:http://blog.csdn.net/duck_genuine/article/details/17014991
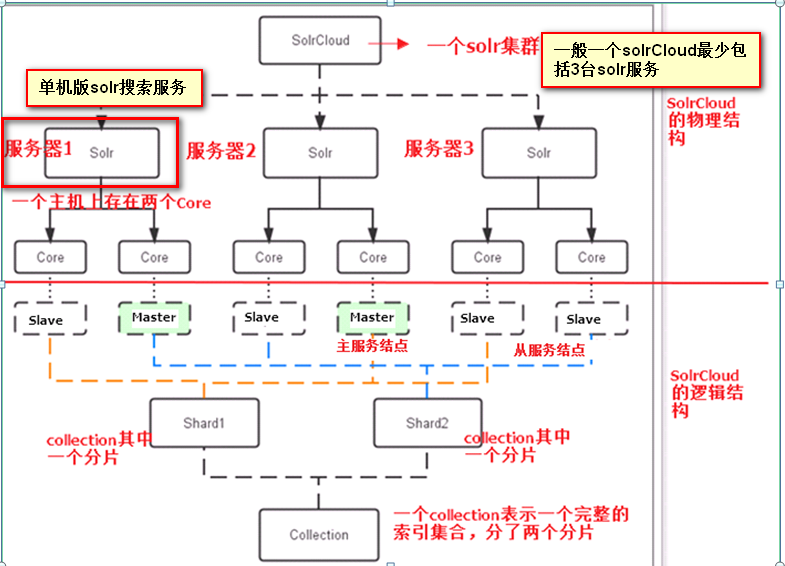
solrCloud分布式检索主要流程如下:

搜索 video,“美女斗秀场” 取按相关度排序取得2条记录~
过程是:
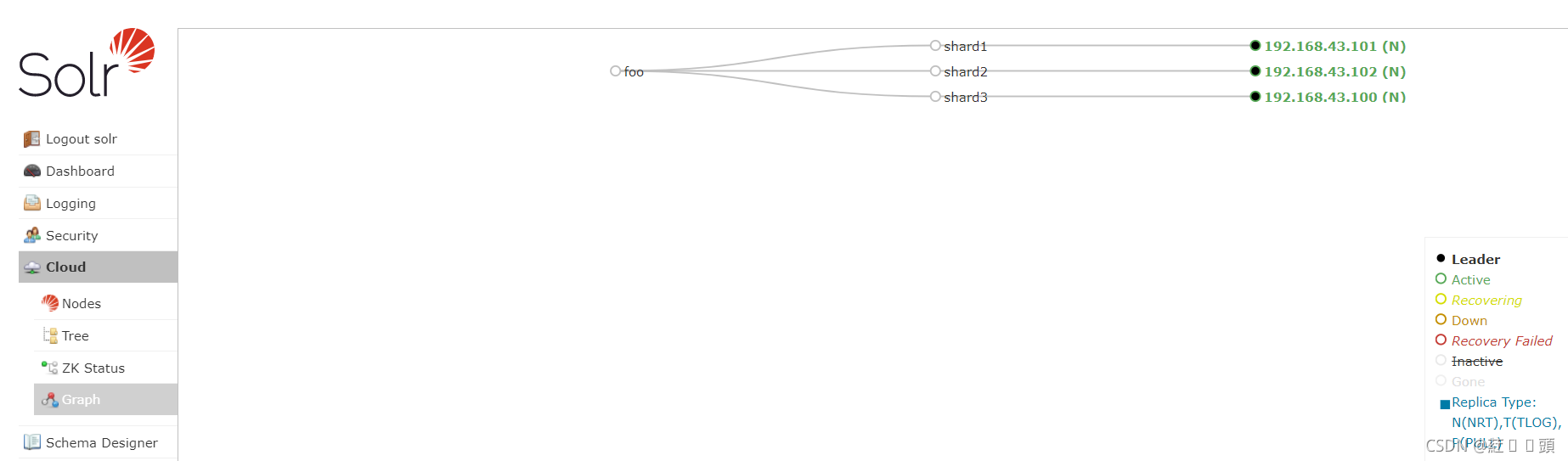
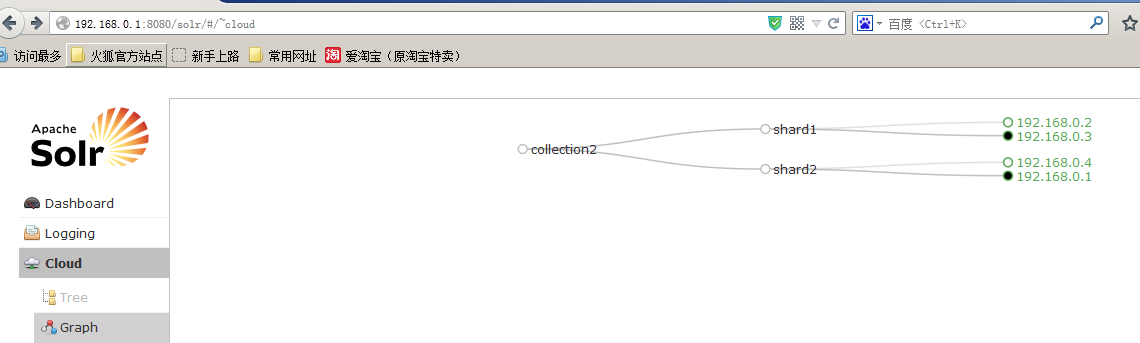
从集群里得知:video—>两个分片信息
所以请求被并行分发到两个分片搜索,各自取top2
第一次返回
返回:
shard1返回:
vid:score
1, 0.5f
2, 0.3f
shard2返回:
vid:score
3, 0.6f
4, 0.2f
合并结果:取top2
vid:score
3, 0.6f (shard2)
1, 0.5f (shard1)
再取正向文档数据:
通过主键并行去两个分片取正向文档数据:字段(vid,times,hd)
文档id分别:
3:
{vid:3,times:100,hd:1}
1:
{vid:1,times:200,hd:0}
再合并结果返回
如果是要翻页,也就是取第3到第4个结果,则会发起请求每一个分片返回4个结果再合并排序
引用请声明原文:http://blog.csdn.net/duck_genuine/article/details/17014991