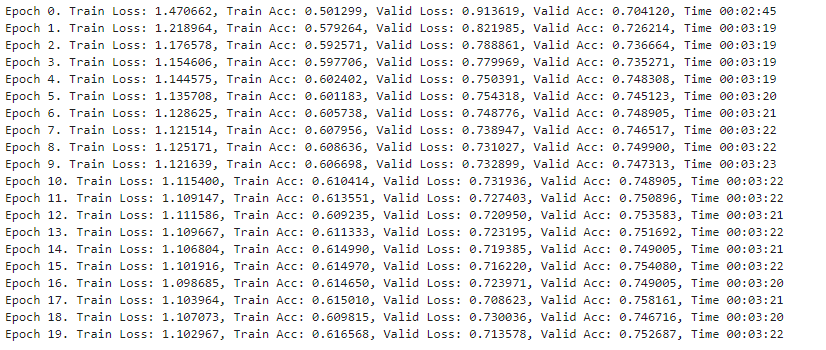
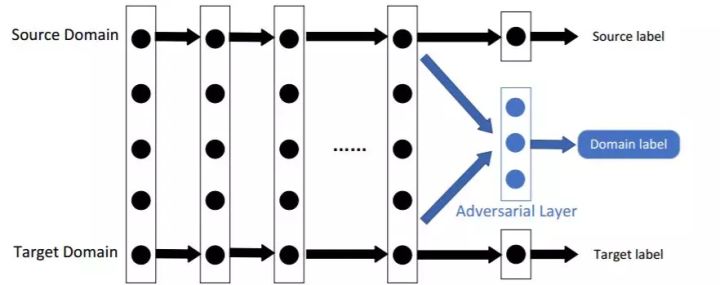
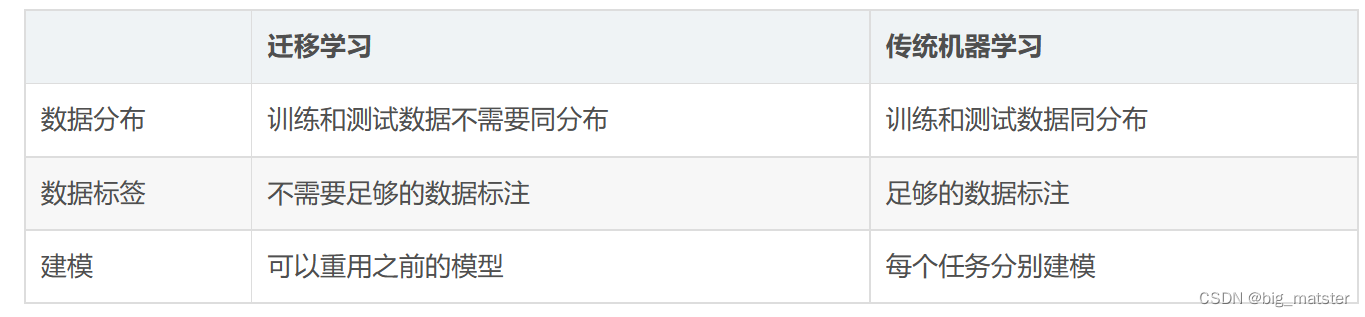
目录
- 迁移学习的基础知识
- 迁移学习的概念
- 迁移学习的分类
- 按目标域标签分
- 按学习方法分
- 按特征分类
- 按离线与在线形式分
- 迁移学习的基本方法
- 基于样本的迁移
- 基于特征的迁移
- 基于模型的迁移
- 基于关系的迁移
- 深度迁移学习
- 深度网络的可迁移性
- 最简单的迁移学习——finetune
- finetune的使用技巧
- 参考:
迁移学习的基础知识

迁移学习的概念
迁移学习的核心是:找到源域和目标域之间的相似性;
找到相似性,下一步工作是如何度量和利用这种相似性。
我们人类天生就有迁移学习的能力,比如:当你学会了怎么骑电动自行车后,再去学习骑小摩托就会很容易上手。再比如:本科阶段学会了C语言,那么读了研究生,开始学习python或C++时,就会少了很多困惑。
迁移学习是一种学习的思想和模式。其核心问题是,找到新问题(目标域)和原问题(源域)之间的相似性,这种相似性很好理解,举几个栗子:
- 自行车和摩托车的骑行方式是相似的
- 网球和羽毛球的打法是相似的
- 中国象棋和国际象棋是相似的
这种相似性也可以理解为不变量。
再举一个杨强教授的栗子,在中国大陆开车,汽车是左舵的,在马路上靠右行驶,而在香港、英国等地区,汽车是右舵的,在马路上靠左行驶。那么要如何适应不同地区的驾驶方式呢?找出这里的不变量,就是说,无论是左舵还是右舵,驾驶员的位置始终是处于马路中间的,这就是问题的不变量。
找到相似性之后,下面要解决的问题是如何衡量这种相似性,这就需要一个很好的度量准则。
度量的目标是:
- 很好的度量两个领域的相似性,不仅定性地告诉我们他们是否相似,更要定量地给出相似的程度是多少。
- 以度量为准则,通过我们所要采用的学习手段,增大两个领域之间的相似性,从而完成迁移学习。
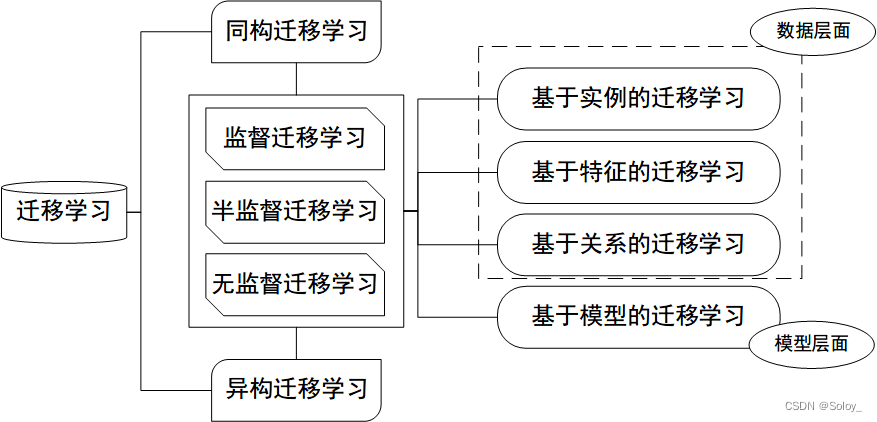
迁移学习的分类
按目标域标签分
类比机器学习,迁移学习也可以按照有无标签分为以下几类:
- 监督迁移学习
- 半监督迁移学习
- 无监督迁移学习
显然,少标签和无标签的迁移学习问题是研究的热点和难点。
按学习方法分
按照学习方法,迁移学习可以分为以下四类:
- 基于样本的迁移学习
- 基于特征的迁移学习
- 基于模型的迁移学习
- 基于关系的迁移学习
在后面会对这几种学习方法加以说明。
按特征分类
按照特征,迁移学习可以被分为:
- 同构迁移学习
- 异构迁移学习
如果特征和维度都是相同的,就叫同构;如果不同,就叫异构。
例如,不同图片之间的迁移就是同构的,而不同文本之间就是异构的。
按离线与在线形式分
按离线和在线的区别,迁移学习可以被分为:
- 离线迁移学习
- 在线迁移学习
目前的绝大多数迁移学习方法都使用了离线迁移学习,就是说,源域和目标域都是给定的,迁移一次即可,这样的局限性是很明显的:算法无法对新加入的数据进行学习,模型也无法得到更新。与之相对,使用在线迁移学习,随着数据的动态加入,模型也会不断地进行更新。
迁移学习的基本方法
基于样本的迁移
简单来说,就是权重重用,对源域和目标域的样例进行迁移。直接对不同的样本赋予不同的权重。比如说相似的样本,我们就可以赋予大权重,这样就完成了迁移,非常的简单,直接。
源域中的数据不能直接用于目标域的训练,但是在源域中还是可以找到与目标域重叠的部分,调整其权重,让两个域中的数据匹配,以便进行迁移。
根据一定的权重生成规则,对数据样本进行重用,来进行迁移学习,如图中所示:

源域中存在不同种类的多种动物,猫,狗,鸟,而目标域中只有狗这一种类别,在迁移过程中,为了最大限度地和目标域相似,我们可以人为地提高源域中属于狗这个类别的样本权重
基于特征的迁移
基于特征的迁移方法是指通过特征变换的方法进行互相迁移,来减少源域和目标域之间的差距,或者找到一些共同特征,将源域和目标域中的特征变换到统一的特征空间中。
基于特征的迁移是迁移学习领域中最热门的研究方法。
基于模型的迁移
基于模型的迁移是指从源域和目标域中找到他们共享的参数信息,以实现迁移的方法。假设目标任务和源任务之间共享一些参数,或者共享模型超参数的先验分布,这样,把原来的模型迁移到新的域中,也可以达到不错的精度。常见的预训练+finetune可以看做是一种基于模型的迁移。
基于关系的迁移
这种迁移方式和之前的几种思路截然不同,这种方法比较关注目标域和源域之间的关系,比如说:当你掌握了如何和老师相处之后,就会更好地学习怎样和公司老板相处;了解了生物学上病毒是如何传播的,就会更容易理解计算机病毒是怎么传播的。
深度迁移学习
随着深度学习的蓬勃发展,与越来越多的研究者将迁移学习应用到深度学习上面。
深度网络的可迁移性
神经网络本身就是一个黑盒子,看得见,摸不着,解释性不好;但是由于神经网络具有良好的层次结构,很自然的就有人关注,能否通过这些层次结构来很好地解释网络?预示就有了下面的例子:

假设我们的神经网络要识别一只猫,那么一开始它只能检测到一些线条和圆形等,和猫没有半毛钱关系,但是随着网络的加深,
最简单的迁移学习——finetune
finetune,也叫微调,fine-tuning,是深度学习中的一个重要概念。
总的说来,finetune就是利用别人已经训练好的网络,针对自己的网络进行微调。
为什么使用已经训练好的网络?
在通常的应用中,我们不会针对每一个新的任务,就从头训练一个神经网络,这样的操作显然是非常耗时的。尤其是,我们的数据不可能向ImageNet那么大,不足以训练出具有足够泛化能力的网络模型。即便说我们有那么大的数据,我们从头再开始训练,代价也是不能承受的。
利用迁移学习,我们可以利用之前已经训练好的某种网络,将他很好地应用到自己的任务上。
为什么需要finetune?
别人训练好的模型可能不会完全适用于我们的任务:可能别人的数据和我们的数据之间服从的不是同一种分布;可能被人的网络比我们的网络能做更多的事;可能别人的任务比较复杂,我们的任务比较简单……
比如在CIFAR-100上已经训练好的神经网络,我们想拿过来训练一个猫狗二分类的神经网络,CIFAR-100实现100个分类,而我们只需要两个分类,那么我们就可以针对我们的任务,固定原始网络的相关层,改变原始网络的输出层,来达到我们任务的要求。
finetune的优势有哪些?
- 不需要针对新的任务从头开始训练网络,节省了时间成本;
- 预训练好的模型通常都是在大数据集上进行的,无形中扩充了我们的训练数据,是的模型具有更好的鲁棒性,泛化能力更好;
- finrtune操作更简单,让我们只专注于自己的任务就行了。
finetune的使用技巧
在实际操作中,考虑到目标数据集的不同大小,以及新旧数据集的相似性不同。迁移学习可以分为四种主要情形:
- 小数据集,新旧数据集相似度高
- 大数据集,新旧数据集相似度高
- 小数据集,新旧数据集相似度低
- 大数据集,新旧数据集相似度低
大数据集可能有几十万至几百万的样本,小数据集可能有几千至几万样本;
狗和狼的相似度可能高一点,但是猫和花的相似度可能低一点。
表中表示了这四种情形对应的一般处理方法:
| 小数据集 | 大数据集 | |
|---|---|---|
| 相似度高 | 具有过拟合的风险,一般删除前几层神经网络,冻结后几层神经网络;添加个全连接层,设置输出层的数量和新数据集中的数量一样,初始化全连接层的参数,重新训练整个网络 | 改变最后一层全连接层,输出层数量和新数据集的数量一样;随机初始化全连接层的权重,用预训练的权重初始化整个网络的权重 |
| 相似度低 | 具有过拟合的风险,一般删除后几层神经网络,冻结前几层神经网络;添加个全连接层,设置输出层的数量和新数据集中的数量一样,初始化全连接层的参数,重新训练整个网络 | 改变最后一层全连接层,输出层数量和新数据集的数量一样;从头训练网络,随机初始化整个网络的权重 |
可以看出来,当数据集较小时,经迁移学习的新的网络会出现过拟合的风险,这时保留并冻结预训练结果部分的网络,以免训练“用力过猛”。
在数据集较大时,最好的情况是数据之间的相似度也很高,这样会节省很多的资源和时间。
数据集大,相似度低时,也可以使用预训练的权重初始化整个网络的权重。虽然相似度低,但是这样初始化权重会加快训练速度,如果使用这种方法并没有生成很好的模型,那么再去选择随机初始化网络,并从头开始训练网络。
参考:
- 迁移学习简明手册
- 迁移学习的使用技巧和在不同数据集上的选择
- 迁移学习有哪些好的调参方法