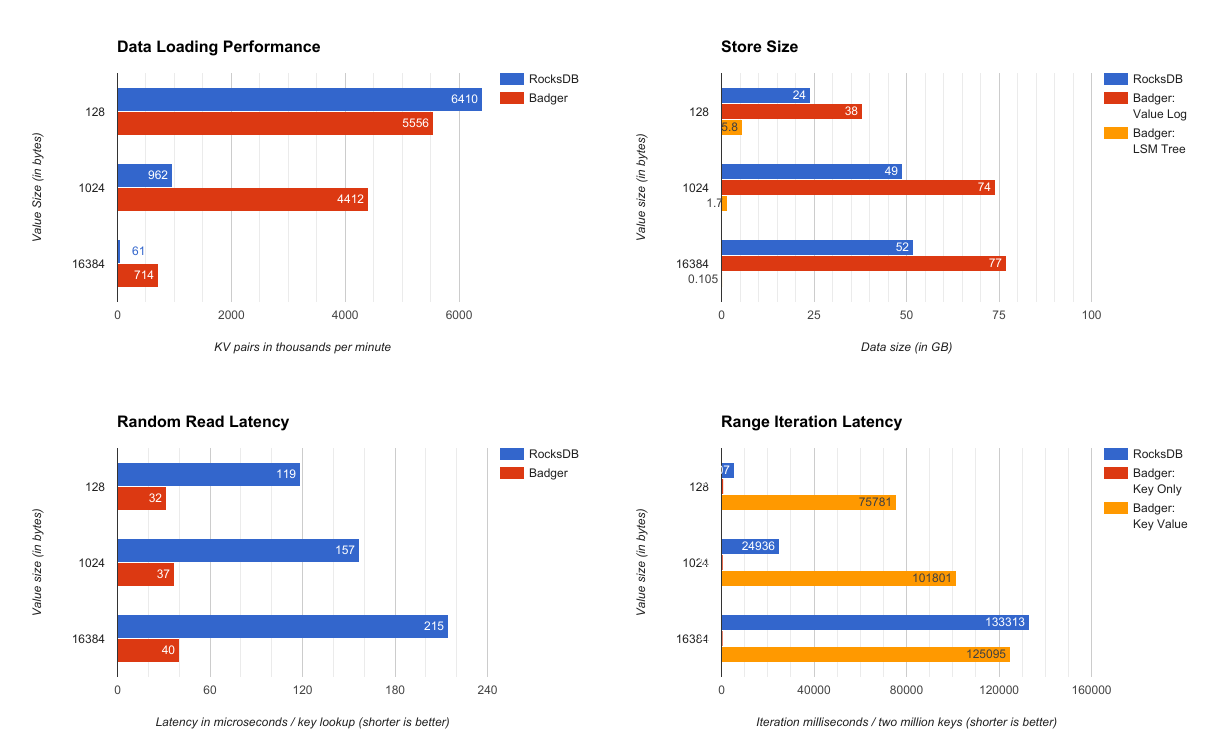
迁移学习(Transfer Learning)通俗来讲就是学会举一反三的能力,通过运用已有的知识来学习新的知识,其核心是找到已有知识和新知识之间的相似性,通过这种相似性的迁移达到迁移学习的目的。世间万事万物皆有共性,如何合理地找寻它们之间的相似性,进而利用这个桥梁来帮助学习新知识,是迁移学习的核心问题。
迁移学习小故事
有一个商人以卖猫的玩偶为生,他是一个分辨高手,擅长区分不同的猫,如果有人拿猫想要坑他,基本是不可能的。名贵的猫的玩偶也就卖的贵一些。突然有一天,他不想卖猫了,想要卖老虎和狗的玩偶。
本以为老虎和猫长的比较像,区分种间不同的种类的时候,也是比较容易的。可是事实没有他想象的那么容易。这突然间一下子的转行,却使他的生意远不如从前了,因为他经常会对不同的种类的老虎和狗的玩偶种类做出错误的判断,会误以为名贵的为廉价的,而卖出的时候以一个低价卖出,导致自己的利润大大降低。
这时候,他只能重新开始学习大量的不同的种类的狗和老虎的细节特征,来尽量提升自己的利润。
模型
商人:不管他是叫是CNN,还是RNN,还是GAN,商人是迁移学习中需要用到的模型
源域
猫咪
源域:具体地,在迁移学习中,我们已有的知识叫做源域(source domain)
目标域
狗和老虎的玩偶
目标域:要学习的新知识叫目标域(target domain)。
多任务学习
同时学习不同种类的狗和老虎的玩偶的特点。
负迁移
从猫迁移到狗,它们之间的相似度不高,即同一模型,对于数据的相似度不高的情况下,迁移的效果会出现副作用的情况,为负迁移。
产生负迁移的原因主要有:
1、源域和目标域压根不相似,谈何迁移?——数据问题(猫和狗的玩偶)
2、源域和目标域是相似的,但是,迁移学习方法不够好,没找到可迁移的成分。——方法问题(猫和老虎的玩偶)
A Survey on Deep Transfer Learning
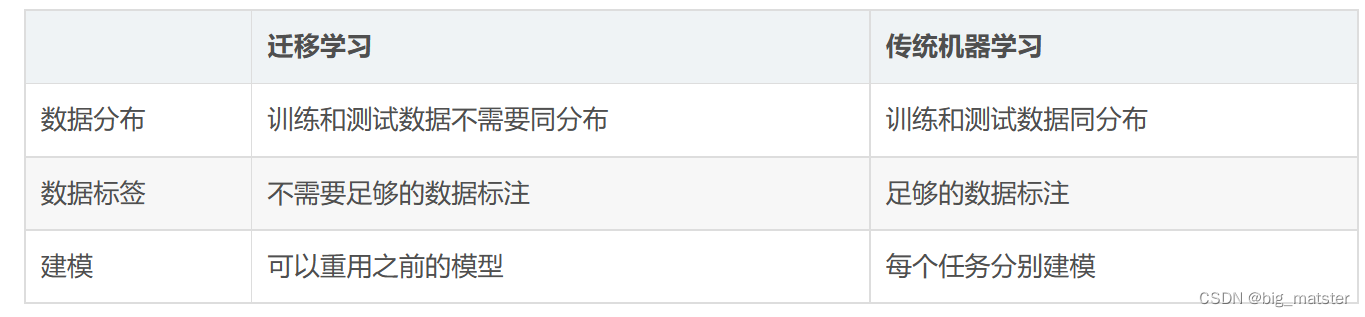
迁移学习放宽了训练数据必须与测试数据独立同分布(i.i.d.)的假设,这启发我们使用迁移学习来解决训练数据不足的问题。
根据深度迁移学习中使用的技术,给出了深度迁移学习的定义、类别并回顾了最近的研究工作。
1.引言
深度学习是机器学习中一种基于大规模数据的表征学习算法。
数据依赖是深度学习中最严峻的问题之一。与传统的机器学习方法相比,深度学习极其依赖大规模训练数据,因为它需要大量数据去理解潜在的数据模式。我们可以发现一个有趣的现象,模型的规模和所需数据量的大小几乎呈线性关系。
对于特定问题,模型的表达空间必须大到足以发现数据的模式。模型中的较底层可以识别训练数据的高级特征,之后的较高层可以识别帮助做出最终决策所需的信息。
迁移学习放宽了训练数据必须与测试数据独立同分布(i.i.d.)这样的假设,这启发我们使用迁移学习来解决训练数据不足的问题。在迁移学习中,训练数据和测试数据不需要是 i.i.d.,目标域中的模型也不需要从头开始训练,这可以显著降低目标域对训练数据和训练时间的需求。
2.深度迁移学习
迁移学习是机器学习中解决训练数据不足问题的重要工具。它试图通过放宽训练数据和测试数据必须为 i.i.d 的假设,将知识从源域迁移到目标域。
我们已有的知识叫做源域(source domain)
要学习的新知识叫目标域(target domain)
符号定义:
域可以 用 D = {χ, P(X)} 表示,其包含两部分:特征空间 χ 和边缘概率分布 P(X) 其中 X = {x1, …, xn} ∈ χ。
任务可以用 T = {y, f(x)} 表示。它由两部分组成:标签空间 y 和目标预测函数 f(x)。f(x) 也可看作条件概率函数 P(y|x)。
定义 1:(迁移学习)。给定一个基于数据 Dt 的学习任务 Tt,我们可以从 Ds 中获取对任务 Ts 有用的知识。迁移学习旨在通过发现并转换 Ds 和 Ts 中的隐知识来提高任务 Tt 的预测函数 fT(.) 的表现,其中 Ds ≠ Dt 且/或 Ts ≠ Tt。此外,大多数情况下,Ds 的规模远大于 Dt 的规模。
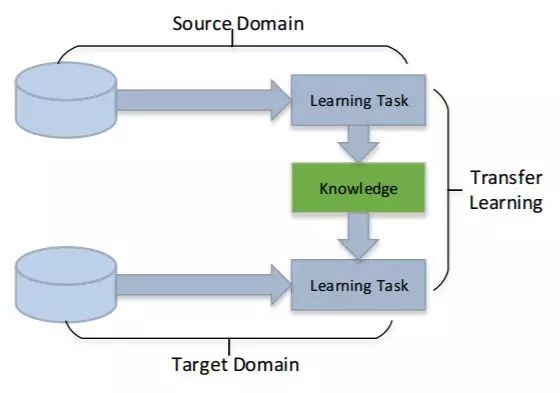
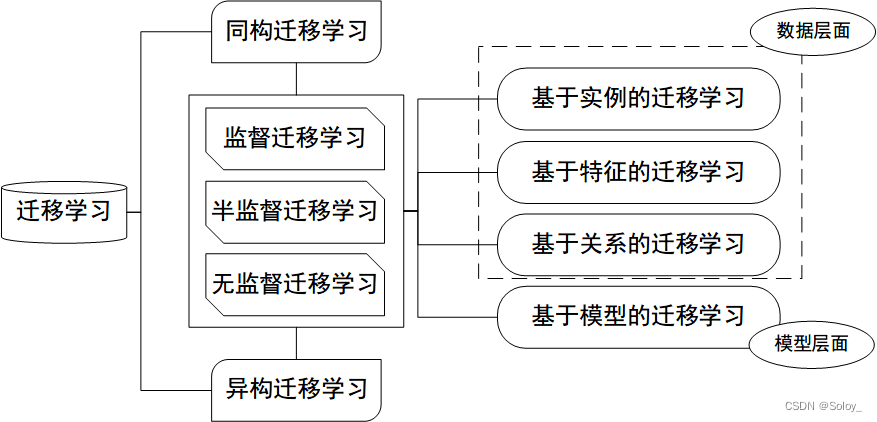
迁移学习就源域和目标域之间的关系分为三个主要类别,这已被广泛接受。这些综述是对过去迁移学习工作的总结,它介绍了许多经典的迁移学习方法。

此外,人们最近提出了许多更新和更好的方法。近年来,迁移学习研究界主要关注以下两个方面:域适应和多源域迁移。
在迁移学习中, 当源域和目标的数据分布不同 ,但两个任务相同时,这种特殊的迁移学习叫做域适应 (Domain Adaptation,DA> )。
多源迁移学习涉及多于一个的源域,同时将多个源域的知识迁移到目标域中辅助目标域的学习。
如今,深度学习近年来在许多研究领域取得了主导地位。重要的是要找到如何通过深度神经网络有效地传递知识,深度神经网络其定义如下:
定义 2:(深度迁移学习)。给定一个由 <Ds, Ts, Dt, Tt, fT(.)>定义的迁移学习任务。这就是一个深度迁移学习任务,其中 fT(.) 是一个表示深度神经网络的非线性函数。
3 类别
深度迁移学习研究如何通过深度神经网络利用其他领域的知识。由于深度神经网络在各个领域都很受欢迎,人们已经提出了相当多的深度迁移学习方法,对它们进行分类和总结非常重要。
基于深度迁移学习中使用的技术,本文将深度迁移学习分为四类:基于实例的深度迁移学习,基于映射的深度迁移学习,基于网络的深度迁移学习和基于对抗的深度迁移学习

3.1 基于实例的深度迁移学习
基于实例的深度迁移学习是指使用特定的权重调整策略,通过为那些选中的实例分配适当的权重,从源域中选择部分实例作为目标域训练集的补充。
它基于这个假设:「尽管两个域之间存在差异,但源域中的部分实例可以分配适当权重供目标域使用。」
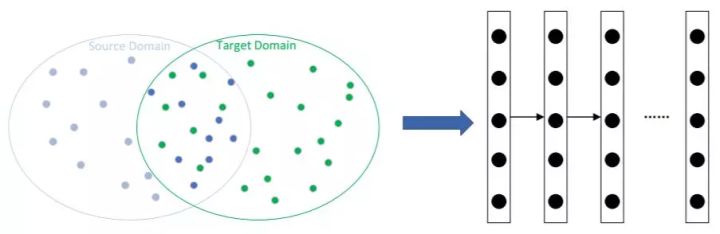
源域中的与目标域不相似的浅蓝色实例被排除在训练数据集之外;源域中与目标域类似的深蓝色实例以适当权重包括在训练数据集中。
3.2 基于映射的深度迁移学习
基于映射的深度迁移学习是指**将源域和目标域中的实例映射到新的数据空间。**在这个新的数据空间中,来自两个域的实例都相似且适用于联合深度神经网络。
它基于假设:「尽管两个原始域之间存在差异,但它们在精心设计的新数据空间中可能更为相似。」
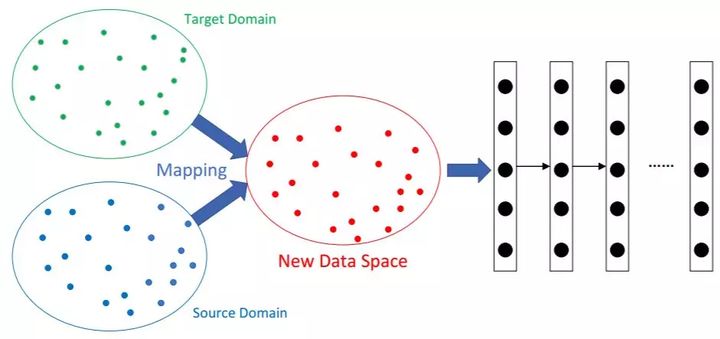
来自源域和目标域的实例同时以更相似的方式映射到新数据空间。将新数据空间中的所有实例视为神经网络的训练集。
3.3 基于网络的深度迁移学习
基于网络的深度迁移学习是指复用在源域中预先训练好的部分网络,包括其网络结构和连接参数,将其迁移到目标域中使用的深度神经网络的一部分。
它基于这个假设:「神经网络类似于人类大脑的处理机制,它是一个迭代且连续的抽象过程。网络的前面层可被视为特征提取器,提取的特征是通用的。」
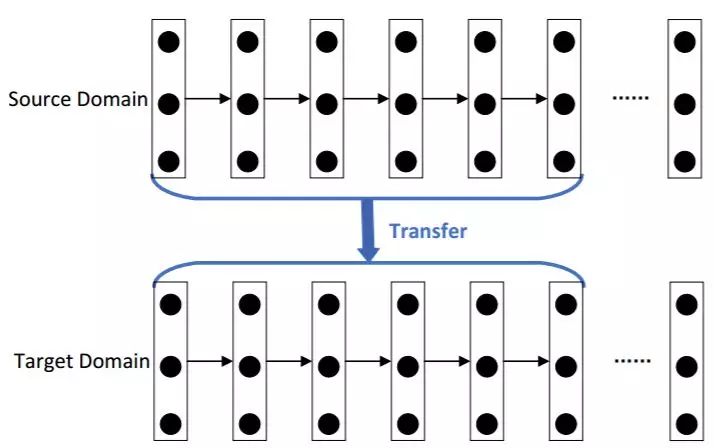
首先,在源域中使用大规模训练数据集训练网络。然后,基于源域预训练的部分网络被迁移到为目标域设计的新网络的一部分。最后,它就成了在微调策略中更新的子网络。
3.4 基于对抗的深度迁移学习
生成对抗网络(GANs)由2个重要的部分构成:
- 生成器(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器
- 判别器(Discriminator):判断这张图像是真实的还是机器生成的,目的是找出生成器做的“假数据”
第一阶段:固定「判别器D」,训练「生成器G」
我们使用一个还 OK 的判别器,让一个「生成器G」不断生成“假数据”,然后给这个「判别器D」去判断。
一开始,「生成器G」还很弱,所以很容易被揪出来。
但是随着不断的训练,「生成器G」技能不断提升,最终骗过了「判别器D」。
到了这个时候,「判别器D」基本属于瞎猜的状态,判断是否为假数据的概率为50%。
第二阶段:固定「生成器G」,训练「判别器D」
当通过了第一阶段,继续训练「生成器G」就没有意义了。这个时候我们固定「生成器G」,然后开始训练「判别器D」。
「判别器D」通过不断训练,提高了自己的鉴别能力,最终他可以准确的判断出所有的假图片。
到了这个时候,「生成器G」已经无法骗过「判别器D」。
循环阶段一和阶段二
通过不断的循环,「生成器G」和「判别器D」的能力都越来越强。
最终我们得到了一个效果非常好的「生成器G」,我们就可以用它来生成我们想要的图片了。
基于对抗的深度迁移学习是指引入受生成对抗网络(GAN)[7] 启发的对抗技术,以找到适用于源域和目标域的可迁移表征。
它基于这个假设:「为了有效迁移,良好的表征应该为主要学习任务提供辨判别力,并且在源域和目标域之间不可区分。」
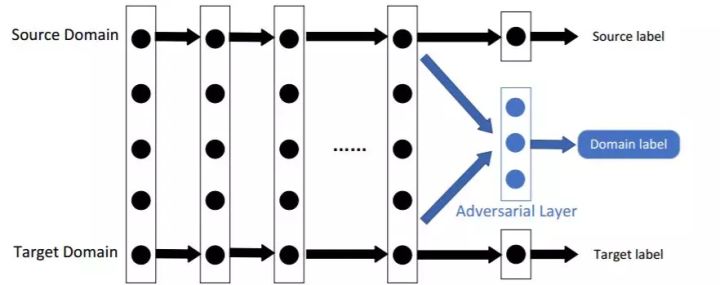
基于对抗的深度迁移学习的示意图。在源域大规模数据集的训练过程中,网络的前面层被视为特征提取器。它从两个域中提取特征并将它们输入到对抗层。
对抗层试图区分特征的来源。如果对抗网络的表现很差,则意味着两种类型的特征之间存在细微差别,可迁移性更好,反之亦然。在以下训练过程中,将考虑对抗层的性能以迫使迁移网络发现更多具有可迁移性的通用特征。
基于对抗的深度迁移学习由于其良好的效果和较强的实用性,近年来取得了快速发展。
4 结论
在本篇综述论文中,我们对深度迁移学习的当前研究进行了回顾和分类。并首次将深度迁移学习分为四类:基于实例的深度迁移学习,基于映射的深度迁移学习,基于网络的深度迁移学习和基于对抗的深度迁移学习。在大多数实际应用中,通常混合使用上述多种技术以获得更好的结果。
目前大多数研究都集中在监督学习上,如何通过深度神经网络在无监督或半监督学习中迁移知识,可能会在未来引发越来越多的关注。负迁移和可迁移性衡量标准是传统迁移学习的重要问题。这两个问题对深度迁移学习的影响也要求我们进行进一步的研究。
此外,为深层神经网络中的迁移知识找到更强大的物理支持是一个非常有吸引力的研究领域,但这需要物理学家、神经学家和计算机科学家的合作。可以预见,随着深度神经网络的发展,深度迁移学习将被广泛应用于解决许多具有挑战性的问题。
内容参考:
https://zhuanlan.zhihu.com/p/44654536?utm_source=wechat_session&utm_medium=social&utm_oi=1125847523901984769&utm_campaign=shareopn
https://blog.csdn.net/SuperYR_210/article/details/78952292
https://blog.csdn.net/qq_40360172/article/details/105232126
https://zhuanlan.zhihu.com/p/438117211