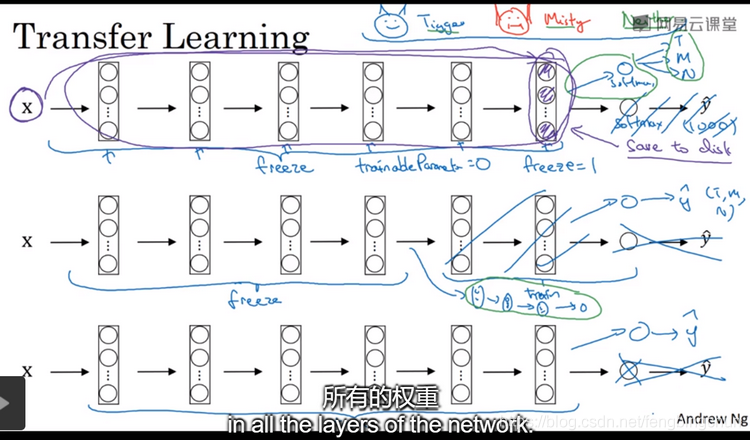
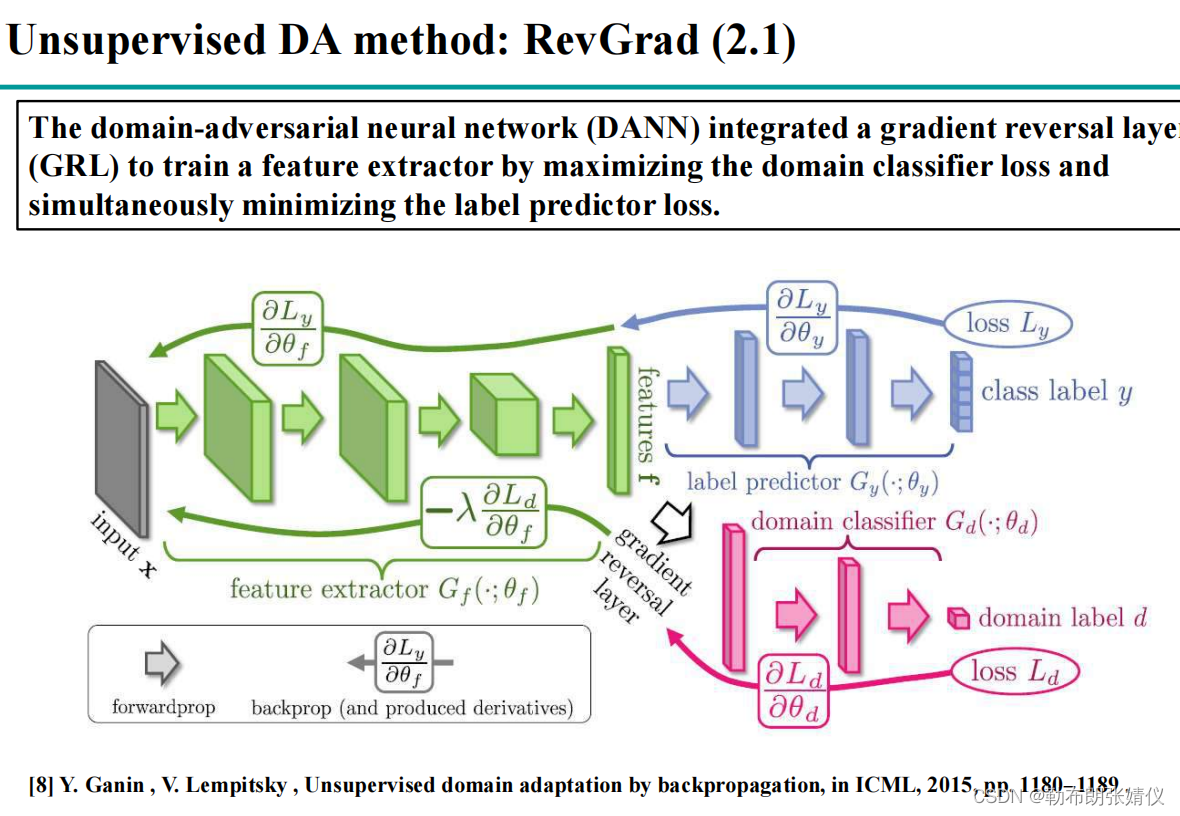
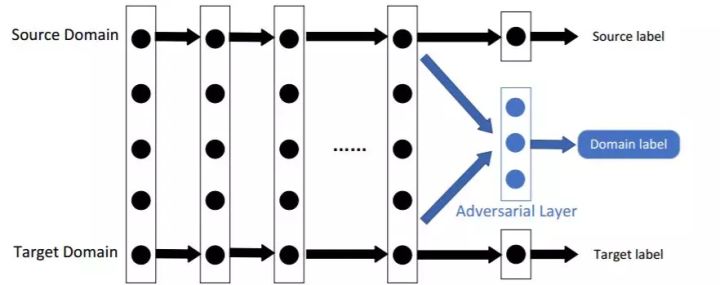
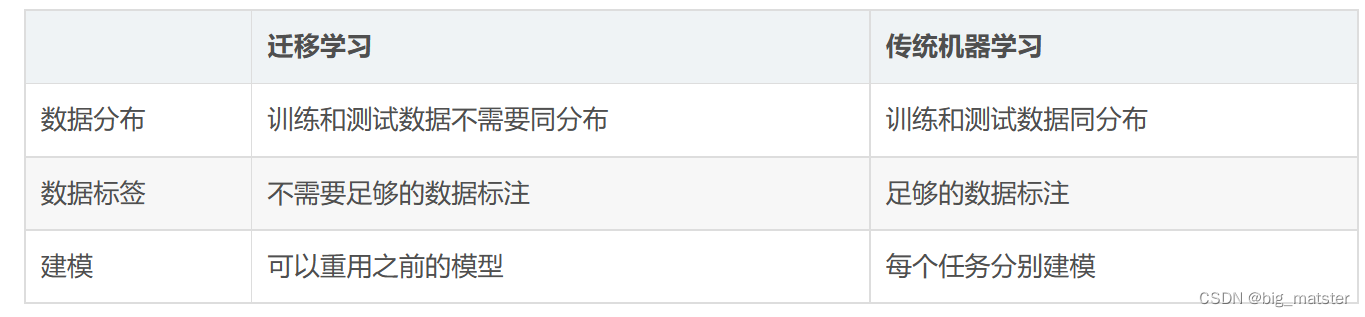
学习迁移学习
一、相关背景
随着机器学习和数据挖掘不断发展,一个愈加明显的问题出现在人们面前:要想机器学习能够正常运转必须要保证训练集和测试集有相同的特征空间并且同分布。一旦分布改变,大多数模型往往要根据数据重建,这样的代价是很高的,而迁移学习正是解决这样一个问题。
举个栗子,我们要训练一个评价分类器,他可以对一个产品的评价进行分类(好评或差评)。为了实现这个功能,我们首先要收集这个产品的许多评价然后标注他们,然后用这些相关的标签来训练这个分类器,但是这个分类器只是针对于当前这个产品,换一种产品就需要重新采集标注数据来训练另一个分类模型,这样的消耗是很大的。为了避免这种情况的发生,我们希望那个已经训练好的分类器可以泛化到其他分类模型上,这时候迁移学习便发挥它的作用。

如图所示,传统的机器学习方法尝试去学习每一种任务,而迁移学习则根据已经学习处理过的任务推广到有较少训练数据的新任务上。
迁移学习较为数学化的定义是这样的:给定一个源域D(s),一个学习任务T(s),一个目标域D(t)和学习任务T(t).迁移学习旨在通过运用D(s)和T(s)的知识帮助提高D(t)中目标预测的学习。其中D(s) ≠ D(t),T(s) ≠ T(t).
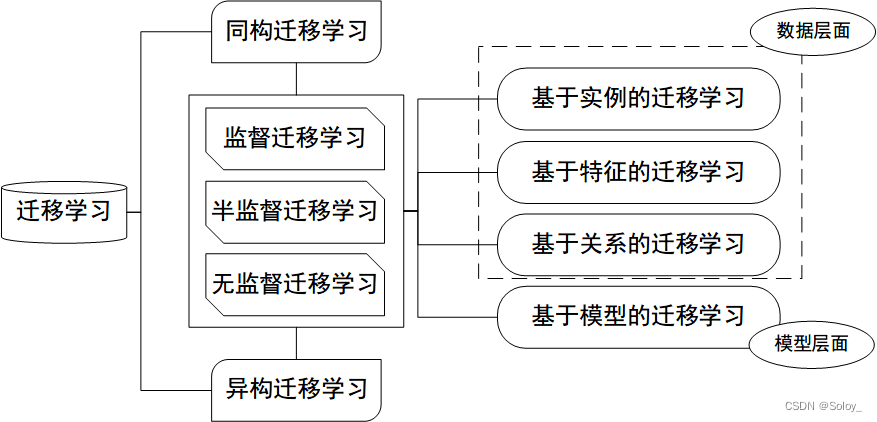
对于不同类型的迁移学习有如下的比较:
1、inductive transfer learning
inductive transfer learning 中原任务和目标的任务是不同的,无论源域和目标域相同与否
对于 inductive transfer learning 又可以分为如下两类:(1)源域中有大量标注数据可用(2)源域中没有可用的标注数据。
在第(1)种情况下,这和多任务学习很类似,但是, inductive transfer learning 旨在在目标任务中通过迁移从源域中学到的知识来达到较好的表现,而多任务学习则尝试同时学习源域和目标域的任务。
对于第(2)种情况,由于此时源域和目标域的标签空间可能不同,这意味着源域中学到的信息不能直接使用。
2、 transductive transfer learning
在transductive transfer learning 中,源域和目标域中学习的任务是相同的,但是源域和目标域不同。此时,在目标域中没有可用的标注数据,然而在源域中仍有大量标注数据可用,由此,对于transductive transfer learning 我们也可以进一步分为两种情况:(1)源域和目标域的特征空间不同(2)源域和目标域的特征空间相同,但是输入图片的边缘分布概率不同。
**3、**unsupervised transfer learning
对于非监督的迁移学习,目标任务虽然和源任务不同但是有相关性。然而,非监督迁移学习主要解决目标域中的非监督学习任务。

下面我们详细看一下这三种迁移学习:
**
1、inductive transfer learning
**
定义:给出一个源域D(s)和一个学习任务T(s),一个目标域D(t)和一个学习任务T(t),inductive transfer learning 旨在通过运用D(s)和T(s)中学到的信息来提高对目标域D(t)中目标预测功能的学习。T(s) ≠ T(t)。
- 特征表示法( feature-representation)
所谓特征表示法就是找到那些比较有代表性的特征,从而最小化域之间的差异和回归模型错误。如果在源域中有大量标注数据可用,那么监督学习方法就可以用来构建特征表示的模型,反之,则采用无监督方法。 - 监督特征结构
这和多任务学习过程相类似,基础思想是学习相关任务共享的低维表示。由Argyriou et al提出的对于多任务的低维特征学习方法如下: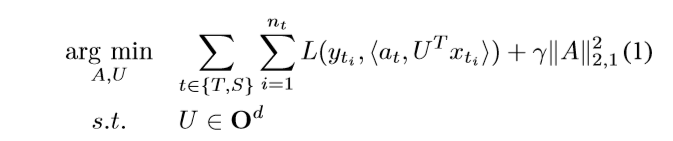
公式中S/T分别表示源域中任务和目标域中的任务。A是一个参数矩阵,U是一个d*d的正交矩阵,把高维数据映射为低维表示。其中,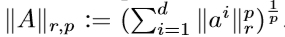
- 无监督特征结构
无监督方法主要包含两个步骤:第一步是通过解决优化问题,偏差向量b从源域数据中学习到。第二步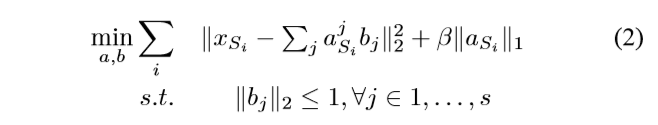
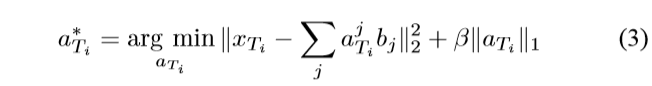
- 参数迁移( parameter-transfer )
首先来讲,多任务学习尝试同时完美地学习源任务和目标任务,而迁移学习旨在通过利用源域数据来促进在目标域中的表现。因此,在多任务学习中,源数据和目标数据的损失函数权重是相同的,而与此相反,在迁移学习中不同域的损失函数权重可以不同。直观来讲,我们要为目标域的损失函数设定更大的权重值从而确保在目标域中实现的更好。
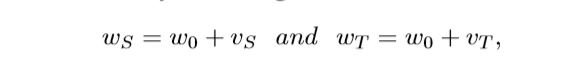
对于一个参数,可以把它分为两个部分,一部分是公共的(适用于所有任务);另一部分是特有的(只针对当前任务)。
- 相关知识迁移( relational-knowledge transfer)
该方法尝试从源域到目标域在数据间迁移相关项。
比如说,一个教授在学术领域所扮演的角色是和一个经理在行业管理领域所扮演的角色是相似的。而且,教授和他的学生的关系同经理和他的工人的关系也是很相似。因此,可能存在一种从教授到经理、从学生到工人的映射。在这样的情况下,TAMAR尝试采用从源域中学到的MLN来帮助目标域中MLN的学习。准确来说,TAMAR是一个二阶算法,第一步是一个基于WPLL从源域MLN到目标域的映射,第二步是在目标域中对映射结构的修正,修正过后的MLN可以在目标域中作为推断的相关模型。
2、Transductive transfer learning
在传统的机器学习中, transductive learning指所有测试数据在训练时被要求看到的情况,并且对于新的数据当前模型不能重复利用。因此,一旦再有新的测试数据产生,此模型就会招架不住。
数学定义:给定一个源域D(s)和一个相关的学习任务T(s),一个目标域D(t)和相关学习任务T(t)。transductive transfer learning旨在通过使用D(s)和T(s)中学到的知识来提高在目标域中目标预测函数的学习,此处D(s)≠ D(t)T(s) = T(t).此外,一些未标注的目标域数据必须在训练时可用。
从此定义中我们可以解读出以下两种信息:(a)源域和目标域的特征空间不同(b)源域和目标域的特征空间相同,但是输入数据的边缘概率分布不同。
以下是transductive transfer learning中的解决方法:
- Transferring the Knowledge of Instances
首先来看一下ERM(empirical risk minimization)问题:通常我们想要通过最小化风险来学习优化模型参数θ。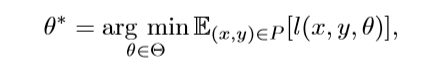
此处l是一个取决于参数θ的损失函数。然而由于很难去估计P的概率分布,所以我们选择最小化ERM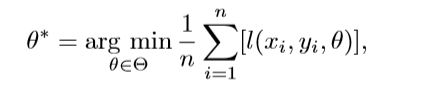
n表示训练数据的多少。在传输式迁移学习中,我们想要通过最小化风险来学得一个针对目标域的优化模型。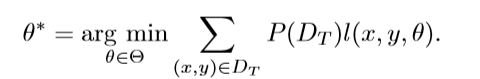
然而因为在目标域中,训练数据中没有标注数据可用,我们必须要从源域数据中学得一个模型。如果P(D(s))= P(D(t)),这样我们就可以通过解决目标域中的使用问题来学习这个模型。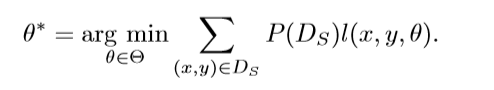
但如果二者不等,我们就必须要提高模型对于目标域的泛化能力。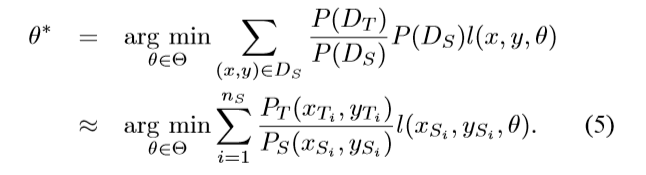
- Transferring Knowledge of Feature Representations
大多数特征表示迁移方法都是在无监督学习框架下进行的。Blitzer 提出了一个结构相关的学习算法(SCL),可以利用目标域中未标注的数据来提取一些相关特征以减少域之间的差异性。下面来看一下这个算法:
第一步:在两个域之中基于未标注的数据定义一组核心特征(数量用m表示)
第二步:SCL从数据中移除这些核心特征并且把每一个核心特征看做成一个新的标签向量。这样m个分类问题即可构建起来。通过假设每个问题可以通过线性分类器来解决: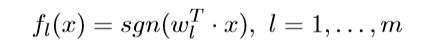
SCL可以学得一个矩阵:W = [w1 w2 w3…wm]
第三步:将奇异值分解方法用到矩阵W中。
第四步:将标准判别算法应用到扩容的特征向量中来建立模型。
3、Unsupervised Transfer Learning
定义:给定一个带有学习任务T(s)的源域D(s),一个带有相关学习任务T(s)的目标域D(t)。无监督迁移学习旨在通过运用D(s)和T(s)的知识来帮助提高D(t)中的目标预测功能,其中T(s)≠ T(t)。
由定义可知,训练时源域和目标域中没有标注数据可见。
- Transferring Knowledge of Feature Representations
关于特征表示知识迁移,一般采用 self-taught clustering(STC)方法解决。STC是无监督迁移学习的例子,旨在通过源域中大量未标注数据的帮助来聚集一小部分目标域中的未标注数据。目标功能如下: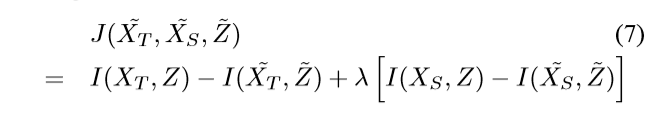
其中Z是X(s)和X(t)的共享特征空间,I(,)表示两个随机变量的共有信息。~表示相应的聚类。