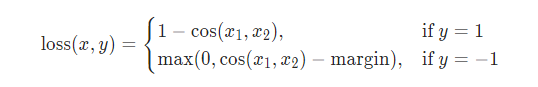综述
从应用的角度来说,对话机器人可以分为三个类别,分别是闲聊机器人,qa机器人以及任务型机器人。本系列主要介绍闲聊机器人。由于本文的内容主要是对对话机器人做一个简单的介绍,所以都是一些简单的介绍,详细的内容后面后有介绍。
目录
检索式对话模型
1. 检索式对话模型(1)
- 主要介绍bm25,LCLR,DSSM模型,deepMatch模型以及cnn-cnt模型。
2. 检索式对话模型(2)
- 主要介绍ARC-I,ARC-II,CDNN模型,BLSTM模型以及CNTN模型。
3. 检索式对话模型(3)
- 主要介绍QA-LSTM以及变种,CLSM模型,Dual Encoder模型,AP-CNN,AP-biLSTM,以及HD-LSTM
4. 检索式对话模型(4)
- 主要介绍HD-LSTM模型,HyperQA模型,BiMPM模型,Compare-aggregate Model,IWAN模型以及MCAN模型。
生成式对话模型及相关技术
1. transformer模型
- 主要介绍了transformer模型的Input,encoder,decoder,位置编码以及attention机制
2. 解码策略介绍
- 主要介绍了greedy,beam search,top-k,top-p以及非自回归解码策略(mask predict等)
3.解码tricks介绍
- 主要介绍了一些解码中使用的技巧,包括了blocking,Prefix Constraints,predictive length等方法介绍。
4.位置编码介绍-系列1
- 主要介绍一些位置编码
5.预训练加速技巧介绍篇(免费)
- 主要介绍一些预训练的相关技巧以及一些框架, 比如说deepspeed, megatron, 以及模型并行, 数据并行和流水线并行, 以及ZeRO的内存优化技术等.
6.强化学习系列之Policy Gradient算法
- 主要介绍一些强化学习中policy gradient算法。
7.强化学习之Q-learning算法
- 主要介绍一些强化学习中Q-learning算法。
预训练模型介绍
一 QA机器人
问答机器人主要功能是在知识库找到用户提问的问题的答案。主要用于智能客服等。一般来说问答机器人是不涉及多轮,主要是针对某一个领域的问答。构建一个问答机器人,第一步是要构架一个高质量的FAQ 语料集,语料集中应该包括大量高质量的Q-A对。第二步,就是做语义匹配的工作,主要有针对用户query与Q的匹配,用户query与A的匹配,或者是融合二者,针对用户query与Q的匹配的同时,也注重用户query与A的匹配。
二 任务型机器人
任务型机器人是针对某类特定任务开发的机器人,主要功能是解决某类问题,比如说订机票,订餐等。
任务型对话主要可以分为五个模块。主要有ASR,NLU,对话管理,NLG,TTS这五个模块,如下图所示:

- ASR主要是将人的语音转化为文本的形式。
- NLU主要是理解用户query的含义。NLU主要分为两个部分,一个是用户的意图或者query的domain区分,另一个是slot filling。
- 对话管理主要包含了两个部分,分别是DST(dialogue state tracking)和policy learning。DST主要作用是跟踪对话的状态,而policy learning作用是根据对话的状态来采取对应的策略。
- NLG主要是回复的生成。可以是模型生成的回复,也可以是固定的回复,或者是根据槽位填充的回复。
- TTS是将文本形式的回复转变为语音的形式。
三 闲聊机器人
3.1 简介
闲聊机器人是在开放域中回答用户没有目的的问题。它的主要功能是同用户进行闲聊对话,一定程度的排解用户的情感需求。因为闲聊本身的属性,所以针对闲聊机器人的回复一般没有明确的评价标准。不过,从整体上看,闲聊对话主要的两个标准是拟人化以及对话参与度[1]。
3.2 方法
闲聊机器人的实现主要有三种方法,分别是基于检索式的方法,基于生成式的方法以及基于检索以及生成的方法。目前来说,基于检索式的方法比较成熟,而基于生成式的方法效果并不是特别好。
3.2.1 基于检索式的方法
基于检索式的闲聊机器人包括了多轮和单轮这两个方向。这里主要介绍单轮的检索式模型,针对单轮的检索式对话机器人,从本质上来说,这是个query和reply的语义匹配问题。所以实现的时候,多数的方法也是从这个角度出发的。
1.方法
基于检索式的对话机器人,顾名思义,是首先通过用户的query在语料库中检索,这里的语料库存储的是<post, response>形式的pair。因此,当用户的query过来后,会利用query检索语料库中的post,然后得到多个<post, response>对。然后利用rank模型(语义匹配模型)对query和response打分。最后利用打分的结果得到相应的回复。
2.语义匹配模型
首先,语义匹配是一个很有挑战性的问题,它不仅仅涉及到word的维度,更是涉及到term,sentence的维度,不仅如此,由于语言的复杂性,语义匹配的复杂度不言而喻。因此目前大部分的语义匹配都是基于特征的维度,不管是character,word,tokens或者sentences的特征。或者是多个特征的融合。所以特征提取器的使用直接影响了语义匹配的效果。目前主流的特征提取器包括了CNN,LSTM以及self-attention。
然后,从模型的角度来说,目前主要的模型有两种,一种是representation learning,一种是match function learning。
- 1) representation learning方法
这类方法的主要思想是首先学习到query和reply的语义表示,然后利用一些度量方法计算二者的相似度,比如说cosine similarity,点乘,NTN,EUCCOS[2]等。

- 2) match function learning方法
这类方法主要是首先融合low level的特征,然后将融合后的特征通过各种match pattern。与representation learning方法的主要区别就是,match function的方法主要是先做特征的组合,然后进行相应的特征提取等操作。

3.优缺点
1)优点:效果好与生成式的方法,基本能够找到好的reply。回复质量比较依赖语料,只要语料质量高,一般都能得到不错的回复。
2)缺点:对话机器人给出的回复只能是语料里面能检索到的回复。整个系统比较复杂,有许多其它的工作,并不是端到端的系统。
3.2.2 基于生成式的方法
1.介绍
基于生成式的对话模型,主要的含义是用户给出一个query,然后通过端到端的方式,让模型生成一个reply。目前这类方法使用的模型基本都是基于seq2seq架构[3]。seq2seq模型输入是一个序列,输出也是一个序列。它的输入和输出的长度是可变的。
2.方法结构
seq2seq模型主要包含了两部分,分别为Encoder和Decoder。其中Encoder的作用主要是将query编码成句向量,而Decoder的作用是根据query编码后的向量,生成reply。除此之外,在seq2seq经常使用的模块还有attention和beam-search等。主要结构如下图所示:

- Encoder:将一个可变程度的序列变为一个固定长度的向量。观察上图的左半部分,Encoder 的输入是各个分割好的token,然后通过LSTM或者self-attention这个结构对各个step的输入进行编码,
- Decoder:将固定长度的向量转变为一个可变长度的序列。同样观察上图,Decoder的输入是 w x y z, 训练的时候输出是w x y z ,在infer的时候主要是使用beam-search得到输出。
3.优缺点
1)优点:生成式的模型能够生成语料里面没有的回复,而且整体的结构比较简单,只要训练好模型后,就能直接得到相应的回复。
2)缺点:生成式模型生成的回复比较偏通用回复,并且生成的回复会有跟query不想关的情况。
3.2.3 基于检索式和生成式的方法
除了上面介绍的两种方法外,最近也有一些工作是将检索式和生成式两种方法融合起来。比如说AliMe chatbot[4],利用seq2seq模型生成回复,检索回来的回复会使用rerank模型进行打分,如果打分低于设定的阈值,就会使用seq2seq生成的回复作为给用户的回复,否则使用检索回来的回复作为用户的回复。
专栏系列介绍
专栏后面的内容主要会围绕检索式对话系统,生成式对话系统以及用到的一些技术。后续分享的内容也会在本文中总结,并会给出相应blog的链接。
引用文献
[1] What makes a good conversation? How controllable attributes affect human judgments, NAACL.2019
[2] A Compare-Aggregate Model for Matching Text Sequences, ICLR.2017
[3] Sequence to Sequence Learning with Neural Networks,NIPS,2014
[4] AliMe Chat: A Sequence to Sequence and Rerank based Chatbot Engine,ACL,2017
[5] A Survey on Dialogue Systems: Recent Advances and New Frontiers.2017