引言
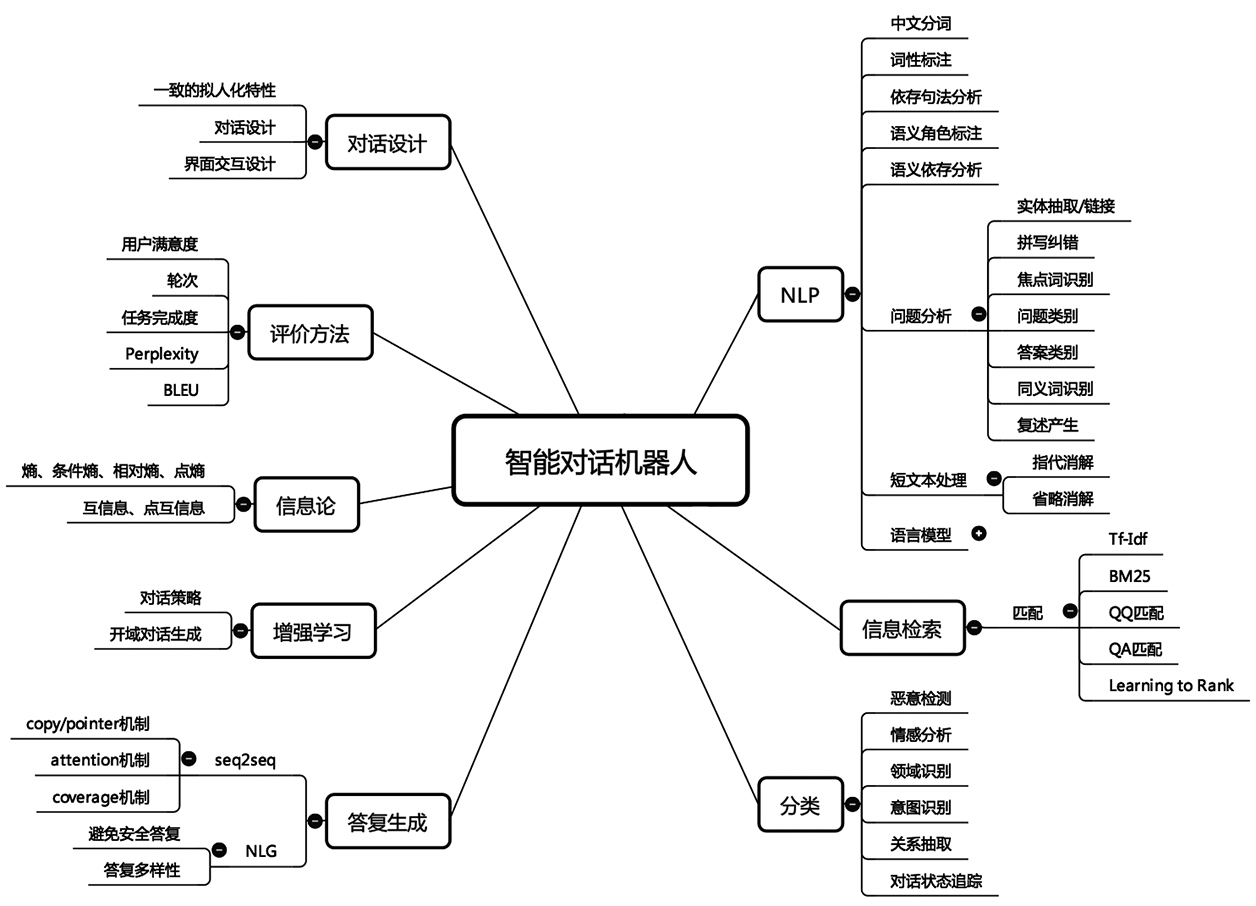
本文是七月在线《NLP中的对话机器人》的视频笔记,主要介绍FAQ问答型聊天机器人的实现。
FAQ问答机器人
FAQ就是一些常见问题与回答,比如https://letsencrypt.org/docs/faq/。
但是我们要做的不是一问一答形式的,而是类似stackoverflow那种一问多答,即包括用户提问、网友回答和最佳答案。有人提问,然后会有人在上面回复,每个问题可能有多个回答。
数据集仓库地址 : https://github.com/SophonPlus/ChineseNlpCorpus
数据集
我们先来了解下数据集。
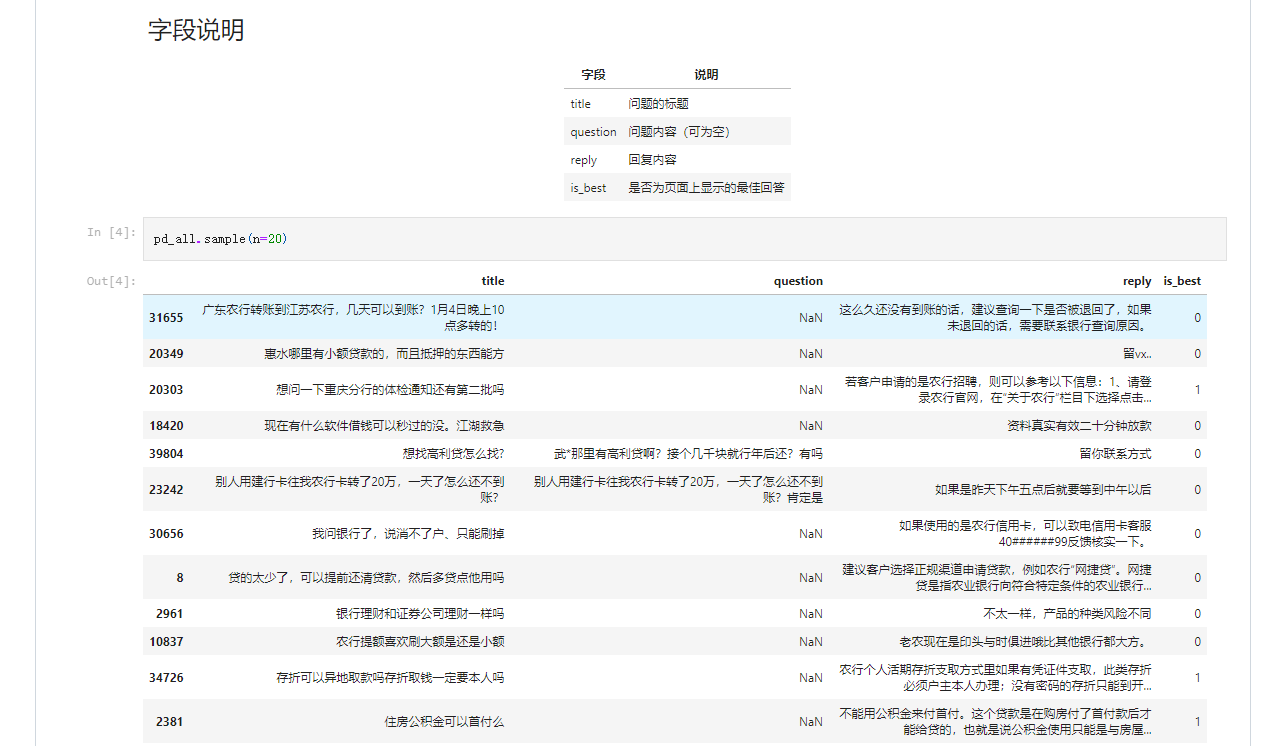
可以看到,有4个字段,其中标题和问题类似发帖时的标题和正文,问题可以为空。
剩下的是reply和is_best分别代表回复和是否为最佳答案。
从这种数据集我们可以想一下它的应用场景。
场景一
假设在提问者手动选择最佳答案之前,我们可以
- 对多个回答进行排序,最相关的、最好的排在前面,不好的排在后面
- 从这些回答中找出最佳回答。二分类任务
数据
我们这里用的数据是农行问答数据,下载地址: https://pan.baidu.com/s/1n-jT9SKkt6cwI_PjCd7i_g
模型
关于这种类似的任务,我们应该得到句子的向量表示,即句向量。可能说到句向量,大家第一时间想到的都是BERT来实现,但这里我们先用简单的模型来实现,简单的模型速度快,可以快速验证我们的思路。
关于问题和回答我们都需要一个句向量编码,我们可以采用Dual Encoder的架构,训练两个编码器,一个用于问题的编码,另一个用于回答的编码。这两个编码器是独立的。我们知道,编码器的选择一般有RNN、CNN和Transformer等。得到了问题和回答的句向量编码后,我们可以使用余弦相似度来计算问题和回答的匹配程度,也可以使用一个复杂一点的神经网络来计算匹配度。
每当拿到一个新的问题和数据,建议从最简单的模型开始,搭建出一个baseline,然后以这个baseline为基础开始调试自己的模型。因为简单的模型往往表现不会太差,容易调试,且模型的可解释性好。当我们确定自己的baseline没有问题之后可以开始尝试更复杂的模型,通过循序渐进地尝试。一般从一些简单的模型开始一步步叠加新的组件,直到效果令人满意位置。如果一开始就采用太复杂的模型,很多情况下我们就无法理解究竟模型中的哪些组件时重要的,哪些是不重要的。
实现
本节包含完整的代码,首先是需要引入的依赖:
from collections import Counter
import pickle
import osimport torch
import torch.nn as nn
import torch.nn.functional as Fimport numpy as np
import pandas as pdfrom tqdm import tqdm
DualEncoder
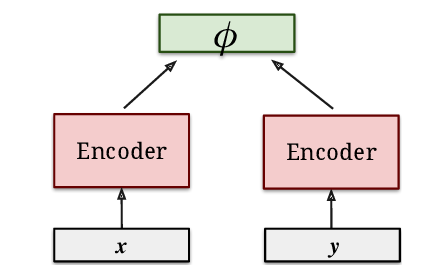
Dual Encoder即两个独立的Encoder,这里分别计算问题和回答的句向量,最后通过余弦相似度计算它们之间的关联程度。
# DualEncoder
class DualEncoder(nn.Module):def __init__(self, encoder1, encoder2, type="cosine"):super(DualEncoder, self).__init__()self.encoder1 = encoder1self.encoder2 = encoder2if type != 'cosine':# 训练一个简单的神经网络来计算相似度self.linear = nn.Sequential(# 拼接encoder1和encoder2的输出(向量),转换成100维的表示nn.Linear(self.encoder1.hidden_size + self.encoder2.hidden_size, 100),# 经过ReLU激活nn.ReLU(),# 再转换成一个数值,表示相似程度nn.Linear(100, 1))def forward(self, x, x_mask, y, y_mask):x_rep = self.encoder1(x, x_mask)y_rep = self.encoder2(y, y_mask)return x_rep, y_rep主要实现了前向传播方法。
Encoder
# GRUEncoder
class GRUEncoder(nn.Module):def __init__(self, vocab_size, embed_size, hidden_size, dropout_p=0.1, avg_hidden=True, n_layers=1, bidirectional=True):super(GRUEncoder, self).__init__()self.hidden_size = hidden_sizeself.embed = nn.Embedding(vocab_size, embed_size)if bidirectional:# 大小除以2,使得拼接两个方向后大小不变hidden_size //= 2# 这种生成句子表征的建议使用bidirectional=Trueself.rnn = nn.GRU(embed_size, hidden_size, num_layers=n_layers, bidirectional=bidirectional,dropout=dropout_p)self.dropout = nn.Dropout(dropout_p)self.bidirectional = bidirectionalself.avg_hidden = avg_hiddendef forward(self, x, mask):x_embed = self.embed(x) # 先得到嵌入表示x_embed = self.dropout(x_embed) # 再经过dropoutseq_len = mask.sum(1) # 计算有效长度# 压缩批次内填充数据# 通过压缩填充加快训练效率,具体可参考文章: https://blog.csdn.net/yjw123456/article/details/118855324x_embed = torch.nn.utils.rnn.pack_padded_sequence(input=x_embed,lengths=seq_len.cpu(),batch_first=True,enforce_sorted=False)output, hidden = self.rnn(x_embed)# output (batch_size, seq_len, hidden_size)# hidden (num_directions * num_layers, batch_size, hidden_size)output, seq_len = torch.nn.utils.rnn.pad_packed_sequence(sequence=output,batch_first=True,padding_value=0,total_length=mask.shape[1])if self.avg_hidden:# 对RNN输出每个时刻的输出求均值# mask.unsqueeze(2) 使维度个数和output一致# hiden (batch_size, hidden_size)hidden = torch.sum(output * mask.unsqueeze(2), 1) / torch.sum(mask, 1, keepdim=True)else:if self.bidirectional:# 拼接两个方向上的输出# hidden[-2,:,:] (batch_size, hidden_size / 2)# hidden[-1,:,:] (batch_size, hidden_size / 2)# hidden (batch_size, hidden_size)hidden = torch.cat((hidden[-2,:,:], hidden[-1,:,:]),dim=1)else:# 取出最顶层(若num_layers > 1)的hiddenhidden = hidden[-1,:,:]# 需要保证各种情况下的hidden大小都是一致的# 经过一层dropouthidden = self.dropout(hidden)return hidden这里采用GRU作为Encoder的实现,支持多种表征的获取,默认是平均每个时刻的输出。
词典
处理NLP任务基本上都需要一个词典:
# 构建分词器
class Tokenizer:def __init__(self, vocab):self.id2word = ["UNK"] + vocab # 保证未知词UNK的id为0self.word2id = {w:i for i,w in enumerate(vocab)}def text2id(self, text):# 对中文简单的按字拆分return [self.word2id.get(w, 0) for w in str(text)]def id2text(self, ids):return "".join([self.id2word[id] for id in ids])def __len__(self):return len(self.id2word)def create_tokenizer(texts, vocab_size):"""创建分词器,输入文本列表和词典大小"""all_vocab = ""for text in texts:all_vocab += str(text)vocab_count = Counter(all_vocab) # 按字拆分# 最频繁的vocab_size个单词vocab = vocab_count.most_common(vocab_size)# (char, count) 从中取出charvocab = [w[0] for w in vocab]return Tokenizer(vocab)def list2tensor(sents, tokenizer):"""将文本列表结合分词器转换为tensor"""res = []mask = []for sent in sents:res.append(tokenizer.text2id(sent))max_len = max([len(sent) for sent in res])# 按最大长度进行填充for i in range(len(res)):_mask = np.zeros((1, max_len)) # 中的元素0表示填充词,1表示非填充_mask[:,:len(res[i])] = 1 # 有效位元素置1res[i] = np.expand_dims(np.array(res[i] + [0] * (max_len - len(res[i]))), 0) # 增加一个维度mask.append(_mask)res = np.concatenate(res, axis=0) # 按维度0进行拼接mask = np.concatenate(mask, axis=0)# 分别转换为long类型和float类型的tensorres = torch.tensor(res).long()mask = torch.tensor(mask).float()return res, mask这里的分词器结合了词典的功能,代码如上,我们可以通过text2id方法获取文本中每个字的ID。
加载数据集
数据集下载地址: https://pan.baidu.com/s/1n-jT9SKkt6cwI_PjCd7i_g
# 数据集位置
file_path = '../dataset/nonghangzhidao_filter.csv'
df = pd.read_csv(file_path)[["title", "reply", "is_best"]] # 只需要这三个字段
df.head()
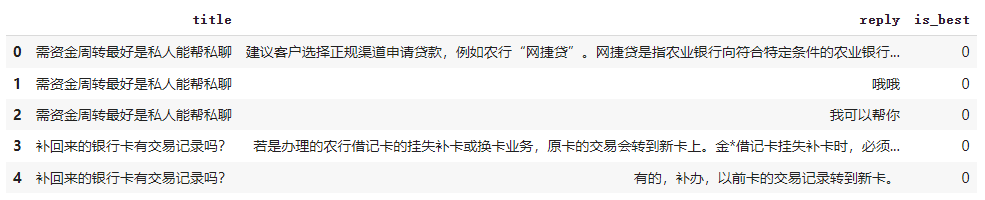
看一下开头那么几条数据,对数据长什么样的有一个基本的了解。
拆分数据集
由于数据集本身没有进行拆分,因此我们这里实现拆分数据集的代码:
np.random.seed(42) # 设定随机种子可以防止每次的训练/测试集数据不一样
# 拆分训练/测试集
def shuffle_and_split_data(data, test_ratio):shuffled_indices = np.random.permutation(len(data))test_set_size = int(len(data) * test_ratio)test_indices = shuffled_indices[:test_set_size] # 前test_set_size作为测试集train_indices = shuffled_indices[test_set_size:] # 剩下的作为训练集return data.iloc[train_indices], data.iloc[test_indices]# 20%的数据作为测试集
train_set, test_set = shuffle_and_split_data(df, 0.2)print(len(train_set), len(test_set))
(31876, 7968)
在拆分数据集的同时进行了洗牌操作,打散数据。
这里设置了随机种子,方式每次运行的训练集、测试集中的数据都不一样。
将文本转换为张量
首先我们取出文本内容:
texts = list(train_set["title"]) + list(train_set["reply"]) # 取出文本内容
查看前10条:
print(texts[:10])
['有没有什么借款的口子?','农行信用卡办哪一张好','窝的银行卡必须要办理转账才能收到钱吗?','请问成都兴百惠公司贷款不成功不收费是真的吗?','得到死者老婆的身份证,还得到死者的户口本和火化证能取走死者银行卡里的钱吗','借个爱奇艺vip会员,只用1天','微信怎么能有微','农村60岁拿钱的,在外地农行能交钱吗','信而富为什么不下款了','大众金融为什么还完贷款,不给办解压绿本']
下面我们创建词典,并基于词典将文本转换为张量:
tokenizer = create_tokenizer(texts, 5000)
print(len(tokenizer))
3383
词典中的单词(字)个数为3383。调用上面实现的list2tensor函数:
sents = list(train_set["title"][:3])
print(list2tensor(sents, tokenizer))
(tensor([[ 15, 211, 15, 238, 97, 52, 4, 2, 488, 233, 125, 0,0, 0, 0, 0, 0, 0, 0],[ 9, 1, 12, 13, 18, 62, 248, 39, 379, 178, 0, 0,0, 0, 0, 0, 0, 0, 0],[2231, 2, 7, 1, 18, 373, 442, 71, 62, 34, 64, 21,493, 63, 81, 41, 206, 100, 125]]),tensor([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0.,0.],[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0.,0.],[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.,1.]]))
可以看到,同时返回了两个tensor,一个是文本对应的ID列表,另一个是mask,表示对应位置的单词是否为填充单词。填充单词用0表示,非填充单词用1表示。
这样做的好处是,可以在计算损失时乘以这个mask,就可以忽略0处(填充词)的损失;通过mask.sum()就可以知道句子的有效长度。
编写训练代码
数据和模型都准备好了,下一步是编写训练代码:
# 编写训练代码
def train(df, model, loss_fn, optimizer, device, tokenizer, loss_function, batch_size):# 设成训练模型,让dropout生效model.train() df = df.sample(frac=1) # 每次训练时shuffle数据# 分批处理for i in range(0, df.shape[0], batch_size): # 得到批次数据batch_df = df.iloc[i:i+batch_size]title = list(batch_df["title"])reply = list(batch_df["reply"])# 构建目标tensor(1或0)target = torch.tensor(batch_df["is_best"].to_numpy()).float()if loss_function == "cosine":# 为了符合CosineEmbeddingLoss的要求,将0替换成-1target[target == 0] = -1 x, x_mask = list2tensor(title, tokenizer)y, y_mask = list2tensor(reply, tokenizer)# 都切换到同一设备(cpu/gpu)x, x_mask, y, y_mask, target = x.to(device), x_mask.to(device), y.to(device), y_mask.to(device), target.to(device)# 计算x和y的表征x_rep, y_rep = model(x, x_mask, y, y_mask)# 根据需要使用不同的损失if loss_function == "cosine":loss = loss_fn(x_rep, y_rep, target)else:# 拼接x_pre和y_rep,并传入linearlogits = model.linear(torch.cat([x_rep, y_rep], 1)) loss = loss_fn(logits, target)optimizer.zero_grad()loss.backward()# 梯度裁剪nn.utils.clip_grad_norm_(model.parameters(), 1.0)optimizer.step()if loss_function == "cosine":sim = F.cosine_similarity(x_rep, y_rep)# 余弦相似度范围在[-1,1]之间,因此这里使用0作为分界sim[sim < 0] = -1sim[sim >= 0] = 1else:sim = model.linear(torch.cat([x_rep, y_rep], 1))# sim = torch.sigmoid(logits) 可以不用sigmoidsim[sim < 0] = 0sim[sim >= 0] = 1sim = sim.view(-1)target = target.view(-1)# 计算准确率num_corrects = torch.sum(sim == target).item()total_counts = target.shape[0]print(f"accuracy:{num_corrects / total_counts}")return num_corrects / total_counts
这里根据不同的设置使用了不同的损失函数,我们后面介绍。
定义参数
# 定义参数loss_function = "cosine"
batch_size = 64
output_dir = "./models"
num_epochs = 10
vocab_size = 5000
hidden_size = 300
embed_size = 600
我们可以根据需要调整这里的参数。
开始训练
# 构建两个Encoder
title_encoder = GRUEncoder(len(tokenizer), embed_size, hidden_size)
reply_encoder = GRUEncoder(len(tokenizer), embed_size, hidden_size)
# 传入DualEncoder模型
model = DualEncoder(title_encoder, reply_encoder, type=loss_function)
# 设置特定的损失函数
if loss_function == "cosine":loss_fn = nn.CosineEmbeddingLoss()
else:loss_fn = nn.BCEWithLogitsLoss()
# Adam优化器
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# 有GPU就用GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)if not os.path.exists(output_dir):os.makedirs(output_dir)# 分词器(词典)可以重复使用,为了不出问题,在推理时要使用和训练时同样的分词器(词典)
pickle.dump(tokenizer, open(os.path.join(output_dir,"tokenizer.pickle"), "wb"))
for epoch in tqdm(range(num_epochs)):train(train_set, model, loss_fn, optimizer, device, tokenizer, loss_function, batch_size)
可以看到,这里有两种损失函数,分别是CosineEmbeddingLoss和BCEWithLogitsLoss。
我们分别来看看。
CosineEmbeddingLoss
官方文档: https://pytorch.org/docs/stable/generated/torch.nn.CosineEmbeddingLoss.html
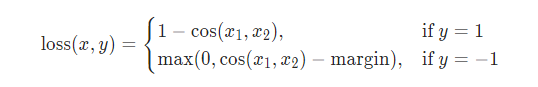
用于衡量两个向量是相似还是不相似的。输入主要为input1( x 1 x_1 x1)、input2( x 2 x_2 x2)、target( y y y)。
这里要求target也就是 y y y取值-1或1,取值1代表正例。
对于正例来说,我们希望它们的余弦距离(1-cosine相似度)尽可能小,余弦相似度取值范围是[-1,1],越接近1表示越相似,在向量中余弦相似度-1表示两个向量方向相反。所以 1 − cos ( x 1 , x 2 ) 1-\cos(x_1,x_2) 1−cos(x1,x2)当相似度为 1 1 1时,损失为 0 0 0,否则相似度越小损失越大;
对于负例来说,我们希望它们的cosine相似度(1-余弦距离)尽可能小,这里让损失最小为 0 0 0,所以取了一个max,由于余弦相似度取值的限制,margin也只能取[-1,1]之间。文档建议使用 0.5 0.5 0.5,默认为零。当为 0.5 0.5 0.5时,实际上余弦相似度表示没有很相似,减去这个值,可以认为损失为 0 0 0。这个取值也可以尝试设置一下,看看会带来怎样的影响。
BCEWithLogitsLoss
因为我们要判断是否为最佳答案,这可以看成是一个二分类问题,正例为 1 1 1,负例为 0 0 0,因此也可以使用交叉熵来作为损失函数。
这里不再赘述,感兴趣都可以参考https://blog.csdn.net/yjw123456/article/details/121734499
了解完损失函数之后,我们来看下模型的表现:
10%|█ | 1/10 [00:56<08:28, 56.52s/it]accuracy:0.7520%|██ | 2/10 [01:54<07:37, 57.19s/it]accuracy:0.7530%|███ | 3/10 [02:50<06:37, 56.74s/it]accuracy:1.040%|████ | 4/10 [03:45<05:36, 56.08s/it]accuracy:1.050%|█████ | 5/10 [04:41<04:40, 56.03s/it]accuracy:1.060%|██████ | 6/10 [05:37<03:43, 55.93s/it]accuracy:0.7570%|███████ | 7/10 [06:32<02:47, 55.77s/it]accuracy:0.580%|████████ | 8/10 [07:30<01:52, 56.41s/it]accuracy:1.090%|█████████ | 9/10 [08:26<00:56, 56.22s/it]accuracy:1.0
100%|██████████| 10/10 [09:22<00:00, 56.21s/it]accuracy:1.0
可以看到,后面的几次准确率为1,但是要注意,这仅仅是在训练集上的结果,准确率为1,也有可能是过拟合了。因此,我们需要在测试集上进行验证。下面添加相关代码。
# 编写在测试集上评估的代码
# 编写训练代码
def evaluate(df, model, loss_fn, device, tokenizer, loss_function, batch_size):# 设成训练模型,让dropout失效model.eval() df = df.sample(frac=1) # 每次shuffle数据# 分批处理for i in range(0, df.shape[0], batch_size): batch_df = df.iloc[i:i+batch_size]title = list(batch_df["title"])reply = list(batch_df["reply"])# 构建目标tensortarget = torch.tensor(batch_df["is_best"].to_numpy()).float()if loss_function == "cosine":target[target == 0] = -1 # 符合CosineEmbeddingLoss的要求x, x_mask = list2tensor(title, tokenizer)y, y_mask = list2tensor(reply, tokenizer)# 都切换到同一设备(cpu/gpu)x, x_mask, y, y_mask, target = x.to(device), x_mask.to(device), y.to(device), y_mask.to(device), target.to(device)# 不需要计算梯度with torch.no_grad():# 计算x和y的表征x_rep, y_rep = model(x, x_mask, y, y_mask)if loss_function == "cosine":loss = loss_fn(x_rep, y_rep, target)sim = F.cosine_similarity(x_rep, y_rep)# 余弦相似度范围在[-1,1]之间,因此这里使用0作为分界sim[sim < 0] = -1sim[sim >= 0] = 1else:logits = model.linear(torch.cat([x_rep, y_rep], 1))loss = loss_fn(logits, target)# sim = torch.sigmoid(logits) 可以不用sigmoidsim = logitssim[sim < 0] = 0sim[sim >= 0] = 1sim = sim.view(-1)target = target.view(-1)# 计算准确率num_corrects = torch.sum(sim == target).item()total_counts = target.shape[0]print(f"test accuracy:{num_corrects / total_counts}, loss:{loss.item()}")return num_corrects / total_counts
和训练时差不多,但有几点要注意,首先model.eval() 让dropout失效,其次torch.no_grad()让推理时不计算梯度。
最后,改写下训练时的代码,每轮训练完成后在测试集上进行评估,保存测试集上准确率最好的模型。
# 构建两个Encoder
title_encoder = GRUEncoder(len(tokenizer), embed_size, hidden_size)
reply_encoder = GRUEncoder(len(tokenizer), embed_size, hidden_size)
# 传入DualEncoder模型
model = DualEncoder(title_encoder, reply_encoder, type=loss_function)
# 设置特定的损失函数
if loss_function == "cosine":loss_fn = nn.CosineEmbeddingLoss()
else:loss_fn = nn.BCEWithLogitsLoss()
# Adam优化器
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
# 有GPU就用GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)if not os.path.exists(output_dir):os.makedirs(output_dir)# 分词器(词典)可以重复使用,为了不出问题,在推理时要使用和训练时同样的分词器(词典)best_acc = 0pickle.dump(tokenizer, open(os.path.join(output_dir,"tokenizer.pickle"), "wb"))
for epoch in tqdm(range(num_epochs)):train(train_set, model, loss_fn, optimizer, device, tokenizer, loss_function, batch_size)acc = evaluate(test_set, model, loss_fn, device, tokenizer, loss_function, batch_size)if acc > best_acc:best_acc = accprint("saving best model")torch.save(model.state_dict(), os.path.join(output_dir, "model.pth"))
0%| | 0/10 [00:00<?, ?it/s]train accuracy:0.75, loss:0.2164661139249801610%|█ | 1/10 [01:02<09:23, 62.66s/it]test accuracy:0.84375, loss:0.13674256205558777
saving best model
train accuracy:0.75, loss:0.2725315690040588420%|██ | 2/10 [02:01<08:04, 60.60s/it]test accuracy:0.78125, loss:0.11578086018562317
train accuracy:1.0, loss:0.0731103867292404230%|███ | 3/10 [03:00<06:57, 59.59s/it]test accuracy:0.84375, loss:0.15137901902198792
train accuracy:0.75, loss:0.2228523194789886540%|████ | 4/10 [03:59<05:55, 59.31s/it]test accuracy:0.75, loss:0.252815842628479
train accuracy:1.0, loss:0.2226412743330001850%|█████ | 5/10 [04:58<04:57, 59.43s/it]test accuracy:0.75, loss:0.21923129260540009
train accuracy:1.0, loss:0.0572931915521621760%|██████ | 6/10 [05:57<03:56, 59.14s/it]test accuracy:0.9375, loss:0.09478427469730377
saving best model
train accuracy:0.75, loss:0.3161787092685699570%|███████ | 7/10 [06:56<02:57, 59.01s/it]test accuracy:0.9375, loss:0.07146801054477692
train accuracy:1.0, loss:0.04639099538326263480%|████████ | 8/10 [07:55<01:58, 59.01s/it]test accuracy:0.71875, loss:0.26382946968078613
train accuracy:1.0, loss:0.02517604827880859490%|█████████ | 9/10 [08:54<00:59, 59.23s/it]test accuracy:0.6875, loss:0.22439222037792206
train accuracy:0.75, loss:0.39026355743408203
100%|██████████| 10/10 [09:53<00:00, 59.37s/it]test accuracy:0.8125, loss:0.20696812868118286
看起来还不错,最好的时候在测试集上的准确率为93.75%
参考
- 七月在线《NLP中的对话机器人》
- PyTorch官网