文章目录
- 1. Word2Vec
- 1.1 Skip-gram
- 2. Airbnb中的Embedding
- 2.1 用在相似推荐中的List Embedding
- 2.1.1 优化一:Booked Listing as Global Context
- 2.1.2 优化二:Adapting Training for Congregated Search
- 2.1.3 冷启动问题
- 2.1.4 效果评估
- 2.2 用在搜索推荐中的Type Embedding
- 2.2.1 Expllicit Negatives for Host Rejections
- 2.2.2 基于Embedding的实时个性化搜索
- 2.3 论文总结
- 3. 总结
Embedding是一种将离散变量转化为连续向量表示的一种方法,其最开始应用于NLP中用于word embedding,目的在于将原本用one hot表示的word映射到一个多维向量空间中形成一个新的向量表达,并由此产生了可以进行计算和比较的特性。之后也顺势产生了image embedding,graph embedding等技术。在特征工程中embedding也用于构造特征,这篇文章浅谈一下Airbnb在他们的推荐场景中如何使用Embedding技术。
1. Word2Vec
说到Word Embedding肯定是避不开经典的Word2Vec,Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。其通过学习文本来用词向量的方式表征词的语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近。Embedding其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。
如果举例子说明,cat这个单词和kitten属于语义上很相近的词,而dog和kitten则不是那么相近,iphone这个单词和kitten的语义就差的更远了。通过对词汇表中单词进行这种数值表示方式的学习(也就是将单词转换为词向量),能够让我们基于这样的数值进行向量化的操作从而得到一些有趣的结论。比如说,如果我们对词向量kitten、cat以及dog执行这样的操作:kitten - cat + dog,那么最终得到的嵌入向量(embedded vector)将与puppy这个词向量十分相近。
Word2Vec分为Skip-Gram(跳词模型)和CBOW(连续词袋模型),分别的作用是用input word来预测上下文和用上下文来预测input word。其模型构造上是非常类似的。

1.1 Skip-gram
这篇文章主要总结一下Skip-gram模型。其主要分文两部分:建立模型,和通过模型获取embedding。本质上来讲skip-gram和自编码器的思想十分相似,同样也是构造一个神经网络并用数据进行训练,待模型拟合之后,我们真正需要的是模型中间的参数层或者权重矩阵。
skip-gram模型的训练数据是自然语句,也就是像 “The quick brown fox jumps over the lazy dog.”这样的句子。其训练过程如下:
- 首先选定输入词,比如
“fox”; - 在选定输入词之后,要定义
skip_window的参数,表示从当前输入词的一侧选取词的数量。假定为2,则我们的窗口获得的词是['quick','brown','fox','jumps','over']。则我们的整个窗口大小 s p a n = 2 × 2 = 4 span=2 \times2=4 span=2×2=4。另一个参数num_skips表示整个窗口中选取多少个不同的词作为我们的output word,当skip_window=2,num_skips=2时,得到的两组(input word, output word)形式的训练数据就是('fox','brown'),('fox','jumps')。 - 神经网络会基于这些数据输出一个概率分布,这个概率分布代表着我们的词典中的每个词是output word的可能性。

我们的模型会从每对单词出现的次数中学习统计结果。然后再完成训练之后,当给定一个输入输出组合比如(“France”,“Paris”)肯定会比(“France”,“Tokyo”)的概率会更高一些。
当具体到模型训练的细节上,首先要把训练数据中的单词用one hot编码进行表示。根据文章构建词汇表,词汇表的总数就是one hot的维度数目。但是由于整篇文章的词汇表本身就非常巨大,则在one hot编码后每个单词都是非常稀疏的高维向量。然后我们会把这些稀疏向量输入到神经网络中,如下图:

其中的隐藏层不使用任何激活函数,输出层用softmax进行多分类。我们用成对的one hot编码后的单词形式(input word, output word)对神经网络进行训练,最终模型输出的是一个概率分布。
Skip-gram的目标函数是:
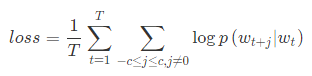
因为每个词wtw_twt都决定了相邻词 w t + j w_{t+j} wt+j,基于极大似然估计,期望所有样本的条件概率 p ( w t + j ∣ w t ) p\left ( w_{t+j}|w_{t} \right ) p(wt+j∣wt) 最大。而输出层softmax的表现形式为:
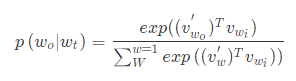
隐藏层
当模型训练完之后,输入数据会从10000维的稀疏向量到隐藏层时变成了300维的稠密向量,然后从300维稠密向量再映射到输出层又变成了10000维。其中间会产生两个权重矩阵,分别乘以10000维的输入向量,和300维的中间向量,我们需要求的就是隐藏层的权重矩阵。如下图我们从两个角度观察权重矩阵,左边表示权重矩阵,每一列是词向量和隐层单个神经元的权重向量,而右边每一行实际代表了每个单词的词向量。也就是说我们只要得到了权重矩阵就可以求word embedding了。

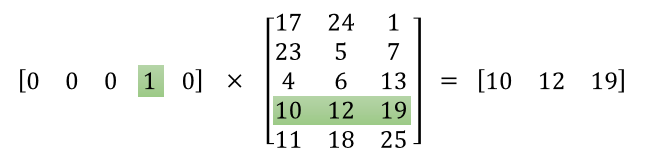
当我们每想得到一个one hot的embedding,就需要用one hot来乘以输入层于隐藏层之间的权重矩阵 W W W。但是由于矩阵相乘的计算量非常大,会降低效率。则从上面观察权重矩阵的另一个角度来看,可以用look up的方法对权重矩阵进行查表,根据向量与矩阵乘法的原则只有向量中非零元素才能对隐藏层产生输入,也就是说输入 x x x 中 x k = 1 x_k=1 xk=1 的第 k k k 位,权重矩阵 W W W的相应第 k k k 行就是embedding的结果,这种查表的办法提高了embedding的效率。
2. Airbnb中的Embedding
在前文中提到了Embedding可以用在特征工程中,全球最大的短租网站Airbnb在KDD2018年论文 Real-time Personalization using Embeddings for Search Ranking at Airbnb 中将这一技术应用在他们的搜索平台上的两个场景中:相似推荐和搜索排序,并成功地提升了原有的两个场景下的推荐效果。
Airbnb主要的使用场景有如下特点:
- 双边的房屋短租平台(顾客,房东)
- 顾客通过搜索或者系统推荐找到房源(99%的订单都是来自于这两个场景)
- 一个顾客很少会预定同一个房源多次
- 一个房源在某时间段内只能被一个顾客租用
- 数据存在严重的稀缺性

而针对其业务执行的个性化推荐也需要考虑到如下情况:
- 针对搜索排序,相似房源推荐进行的实时个性化
- 基于业务需求,考虑搜索的目标
- 点击率(CTR),在一个房屋上停留的时长,提高房屋预定的转化率等等
- 与其他商品不同,不是用户想定就能定上房源
- 对于双边市场,需要同时为市场两端用户买家(guest)和卖家(host)提供服务
- 双边的推荐,既需要考虑用户预订,也需要考虑房东是否接受预订(Host Actions:Reject, Accept, No Response)
- 对于query(带有位置和旅行的时间),同时为host和guest优化搜索结果:
- 顾客角度:需要根据位置,价格,类型,评论等因素排序来获得客户喜欢的listing
- 房东角度:需要过滤掉那些有坏的评论,宠物,停留时间,人数,等其他因素而拒绝guest的listing,将这些listing排列的低一点
- 采用Learnig to rank来做,将问题转换为pairwise regression问题,将预定的listing作为正样本,拒绝的作为负样本。
鉴于如上需要考虑的情况,Airbnb在他们的推荐场景中使用了Embedding技术来提高推荐的质量,而其主要实现的两步是:
-
使用Embedding来学习listing的低维表达,提高相似房源推荐的质量
-
使用Embedding来建模用户long-term偏好,提高搜索推荐的质量
2.1 用在相似推荐中的List Embedding
Listing Embedding是用来做Similar Listing Recommendation。用户点击了搜索页面中的某个短租屋,查看信息之后在页面底部系统会推荐跟点击房源类似的其他短租屋,这就是相似房源推荐。但是如果按照平时的基于用户或者商品的推荐,以订单来作为数据,会发现其实数据非常稀缺。针对这个问题,这篇论文提出的方法是in-session personalization。他会记录最近你点击过的listings,而每个listing会根据房屋不同的特征表现出来。

然后根据你是点击了like,还是放进了心愿单,预定,联系房东等等不同的判别准则,构造一系列click session,每个session都是地应为一个用户点击m个listings组成的不间断序列,如果两次click的间隔时间超过30分钟,就认定为一个session,然后后面的click继续组成下一个session。

如上图中每个session后面都是记录的listing的id,然后每个session就可以组成sequence,输入到我们在第一章节介绍的word2vec中的Skip-Gram模型中,这里每个listing就相当于一个word。原始的Negative sampling Skip-gram模型的目标函数如下:
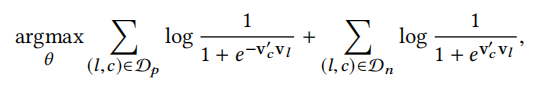

2.1.1 优化一:Booked Listing as Global Context
在click session的场景下,我们将booked listing作为一个正样本,以全局上下文的形式加入到模型训练中,也就是说无论当前训练中心词周围有没有booked listing,我们都认为ubooked listing在他的上下文范围中,则目标函数就修改为如下:
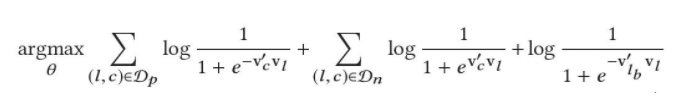
其中 l b l_b lb 表示最后的booked listing。而这个目标函数表达的是:针对当前的center listing, l l l,作为输入,我们期望其上下文中listing D p D_p Dp,以及最终Booked Listing, l b l_b lb出现的概率尽可能的高;希望不是上下文中的listing, D n D_n Dn出现的概率尽可能的低。
则单次的模型训练如下:

2.1.2 优化二:Adapting Training for Congregated Search
Airbnb的用户搜索时多半是在一个固定的地点的,则其对应的负样本也应该是来自同一个地点。而Negative sampling得到的listing会有很多难以满足这个条件,所以第二个优化是在目标函数中加入对同一个地点的负样本采样
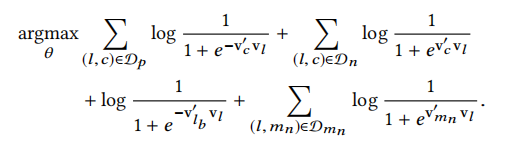
其中 D m n D_{m_n} Dmn 就是同一个地点中采样的负样本。注意只有 l b l_b lb 的前面是没有求和号的,因为每个训练Step都只有一个Booked Listing。
2.1.3 冷启动问题
这对新的listing冷启动问题,Airbnb给出的解决方案非常简单:找到其方圆10英里之内的3个最相似的listing,然后对其Listing Embdding取平均即可。论文提到,利用这一简单的方法,可以解决98%的新listing冷启动问题。
2.1.4 效果评估
在离线状态下对Listing Embedding的效果做了评估,评估标准是测试用户最近的点击推荐的房源,有多大可能最终会产生预订。其对应的步骤如下:
- 获取用户最近点击的房源,以及需要排序的房源候选列表,用户最终预订的房源
- 计算点击房源和候选房源在embedding空间的余弦相似度
- 对候选房源按照相似度进行排序,观察最终预订的房源在排序中的位置

2.2 用在搜索推荐中的Type Embedding
Listing Embedding是用在相似推荐场景的,而对于搜索推荐的这种长期,并且非同一个地点的场景下。比如之前用户session搜索的是成都的房屋,但是之前他也在上海,贵阳,北京住过,同样也会带有他的兴趣偏好。但是Listing Embedding在这里并不适用了,有如下的原因:
- 训练数据集很小
- 很多用户在过去只预定过一次,这些数据是没法用来训练模型(高纬度稀疏问题)
- 需要进一步去掉那些在平台上总共就被预定的次数很少的Listing(比如少于5-10次的Listing)
- 时间跨度太长,可能用户的喜欢偏好已经发生变化
所以在这个问题上,Airbnb将问题的粒度加粗,对user和listing按照规则进行聚合,组成user_type和listing_type。然后根据user_type和listing_type组合成Booked session进行训练。聚合规则也非常简单,先根据listing属性值进行分桶,然后对桶进行组合,如下图所示:

这样原本精细到单个user上面的数据就提升到了同一类型users上,数据也变得稠密了。这样的话,即使对于同一个listing或user,对应的type也可以发生变化(比如用户行为发生变化)。也可以很好地解决冷启动问题,用户层面上的前五个特征是通用的画像特征,对于新用户可以直接通过这五个特征完成映射。

2.2.1 Expllicit Negatives for Host Rejections
在这里因为要考虑房东的拒绝行为,所以在模型的负样本中增加user_id之前被拒绝的那部分listing,告诉模型不要给user推荐这种类型的listing。则对上述的目标函数进行优化:

其训练过程就变成了:

2.2.2 基于Embedding的实时个性化搜索
上面的Embedding构造完之后,就需要在Search Ranking Model中使用新特征。论文中总共构造了这么几个新特征:

上半部分收集的都是用户过去两周的历史数据,并实时更新,是short-term特征。但是long-term特征只用了一个UserTypeListingTypeSim,将当前user_id转换成user_type, 候选listing_id转换成listing_type,利用余弦计算出一个相似度。
特征重要性如下:

可以看到,再加上原本的特征后,新构造的Embedding特征的重要性还是很靠前的。
线上效果如下:

可以看到其主要关注的指标DCU和NDCU的提升度都有明显的上升。
2.3 论文总结
Airbnb提出的这两个Embedding技术将搜索session中数据看作类似序列信息,并通过类似word2vec的方式(进行了改进)学习出每个房源id的embedding值。其中Listing Embeddings粒度最细,将用户的租房点击信息(只有浏览超过30秒才算点击信息分为多个session, 适合于短期实时个性化排序和推荐场景。在更粗的粒度上(User Type Embedding 和 Listing Type Embedding)上进行长期兴趣学习, 更适合于长期个性化场景。并且考虑双边市场的特点,通过加入“booking”、“host rejection”强反馈信号来指导无监督学习。
3. 总结
Embedding技术非常好用,由于其可以将稀疏向量转变为稠密向量,所以其可以用在特征Embedding化中,而Airbnb就是将这个技术用于推荐系统中的一个实例,成功的提高了他们推荐效率。所以在今后的特征工程中也可以考虑用embedding来构造新的特征。
参考资料:
Real-time Personalization using Embeddings for Search Ranking at Airbnb
https://zhuanlan.zhihu.com/p/69153719
https://zhuanlan.zhihu.com/p/27234078