看了几天的书,终于到这一步了,说实话,用R来做统计,很少有人手动的去输入那些数字,肯定是从别的地方导入的,我们用来处理就可以了,所以到这里才算是真正的入门,前面都是做基础的练手。
我学习R从《R语言与统计分析》入手,第一个例子,从书上的例子,入手,为大家能够快速入门。
在F盘下有个r文件夹,里面有个foo.txt的文件,
文件的内容如下:
treat weight
A 3.4
B NA
C 5.8
操作命令如下:
>foo<-read.table(file="f:/r/foo.txt",header=T)
>foo
输出结果如下:
at weight
1 A 3.4
2 B NA
3 A 5.8当然我们在经过一系列的处理以后,需要将其保存起来,我们接着来看保存的命令。
1:保存为简单的文本
>write.table(name,file="d:/r/foo.txt",row.names=F,quote=F)
这里rownames表示行名为False也就是不写入文件,quote引号的意思,=F也是不写入的意思。
2.保存为csv文件
>write.csv(d,file="c:/data/foo.csv",row.names=F,quote=F)
3.保存为R格式
save(d,file="f:/r/fool.Rdata")
下面是一个非常像详细的解释:
http://www.cnblogs.com/xianghang123/archive/2012/06/06/2538274.html
【R】数据导入读取read.table函数详解,如何读取不规则的数据(fill=T)
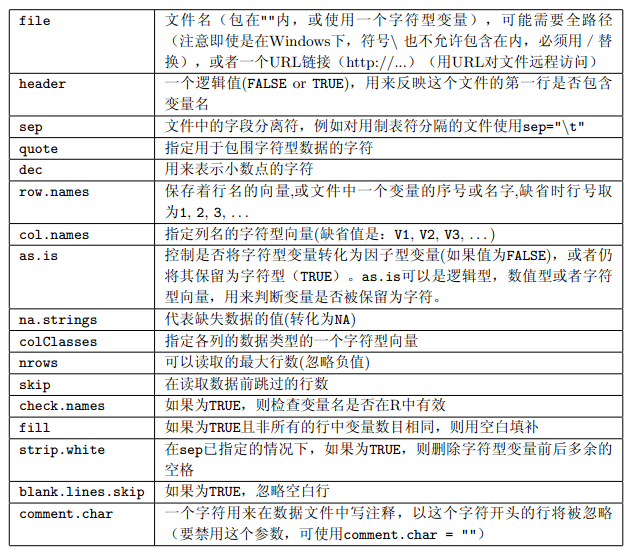
函数 read.table 是读取矩形格子状数据最为便利的方式。因为实际可能遇到的情况比较多,所以预设了一些函数。这些函数调用了 read.table 但改变了它的一些默认参数。
注意,read.table 不是一种有效地读大数值矩阵的方法:见下面的 scan 函数。
一些需要考虑到问题是:
- 编码问题
如果文件中包含非-ASCII字符字段,要确保以正确的编码方式读取。这是在UTF-8的本地系统里面读取Latin-1文件的一个主要问题。此时,可以如下处理
read.table(file("file.dat", encoding="latin1"))注意,这在任何可以呈现Latin-1名字的本地系统里面运行。
- 首行问题
我们建议你明确地设定
header参数。按照惯例,首行只有对应列的字段而没有行标签对应的字段。因此,它会比余下的行少一个字段。(如果需要在 R 里面看到这一行,设置header = TRUE。)如果要读取的文件里面有行标签的头字段(可能是空的),以下面的方式读取read.table("file.dat", header = TRUE, row.names = 1)列名字可以通过
col.names显式地设定;显式设定的名字会替换首行里面的列名字(如果存在的话)。 - 分隔符问题
通常,打开文件看一下就可以确定文件所使用的字段分隔符,但对于空白分割的文件,可以选择默认的
sep = ""(它能使用任何空白符作为分隔符,比如空格,制表符,换行符),sep = " "或者sep = "\t"。注意,分隔符的选择会影响输入的被引用的字符串。如果你有含有空字段的制表符分割的文件,一定要使用
sep = "\t"。 - 引用 默认情况下,字符串可以被 " 或 ' 括起,并且两种情况下,引号内部的字符都作为字符串的一部分。有效的引用字符(可能没有)的设置由参数
quote控制。对于sep = "\n",默认值改为quote = ""。如果没有设定分隔字符,在被引号括起的字符串里面,引号需要用 C格式的逃逸方式逃逸,即在引号前面直接加反斜杠 \。
如果设定了分隔符,在被引号括起的字符串里面,按照电子表格的习惯,把引号重复两次以达到逃逸的效果。例如
'One string isn''t two',"one more"
可以被下面的命令读取
read.table("testfile", sep = ",")这在默认分隔符的文件里面不起作用。
- 缺损值 默认情况下,文件是假定用
NA表示缺损值,但是,这可以通过参数na.strings改变。参数na.strings是一个可以包括一个或多个缺损值得字符描述方式的向量。数值列的空字段也被看作是缺损值。
在数值列,值
NaN,Inf和-Inf都可以被接受的。 - 尾部空字段省略的行
从一个电子表格中导出的文件通常会把拖尾的空字段(包括?堑姆指舴? 忽略掉。为了读取这样的文件,必须设置参数
fill = TRUE。 - 字符字段中的空白
如果设定了分隔符,字符字段起始和收尾处的空白会作为字段一部分看待的。为了去掉这些空白,可以使用参数
strip.white = TRUE。 - 空白行
默认情况下,
read.table忽略空白行。这可以通过设置blank.lines.skip = FALSE来改变。但这个参数只有在和fill = TRUE共同使用时才有效。这时,可能是用空白行表明规则数据中的缺损样本。 - 变量的类型
除非你采取特别的行动,
read.table将会为数据框的每个变量选择一个合适的类型。如果字段没有缺损以及不能直接转换,它会按logical,integer,numeric和complex的顺序依次判断字段类型。如果所有这些类型都失败了,变量会转变成因子。参数
colClasses和as.is提供了很大的控制权。as.is会 抑制字符向量转换成因子(仅仅这个功能)。colClasses运行为输入中的每个列设置需要的类型。注意,
colClasses和as.is对每 列专用,而不是每个变量。因此,它对行标签列也同样适用(如果有的话)。 - 注释
默认情况下,
read.table用 # 作为注释标识字符。如果碰到该字符(除了在被引用的字符串内),该行中随后的内容将会被忽略。只含有空白和注释的行被当作空白行。如果确认数据文件中没有注释内容,用
comment.char = ""会比较安全 (也可能让速度比较快)。 - 逃逸
许多操作系统有在文本文件中用反斜杠作为逃逸标识字符的习惯,但是Windows系统是个例外(在路径名中使用反斜杠)。在 R 里面,用户可以自行设定这种习惯是否用于数据文件。
read.table和scan都有一个逻辑参数allowEscapes。从 R 2.2.0 开始,该参数默认为否,而且反斜杠是唯一被解释为逃逸引用符的字符(在前面描述的环境中)。如果该参数设为是,以C形式的逃逸规则解释,也就是控制符如\a, \b, \f, \n, \r, \t, \v,八进制和十六进制如\040和\0x2A一样描述。任何其它逃逸字符都看着是自己,包括反斜杠。
常用函数 read.csv 和 read.delim 为 read.table 设定参数以符合英语语系本地系统中电子表格导出的CSV和制表符分割的文件。这两个函数对应的变种 read.csv2 和 read.delim2 是针对在逗号作为小数点的国家使用时设计的。
如果 read.table 的可选项设置不正确,错误信息通常以下面的形式显示
Error in scan(file = file, what = what, sep = sep, :line 1 did not have 5 elements
或者
Error in read.table("files.dat", header = TRUE) :more columns than column names
这些信息可能足以找到问题所在,但是辅助函数 count.fields 可以进一步的深入研究问题所在。
读大的数据格子(data grid)时,效率最重要。设定 comment.char = "",以原子向量类型(逻辑型,整型,数值型,复数型,字符型或原味型)设置每列的 colClasses ,给定需要读入的行数 nrows (适当地高估一点比不设置这个参数好)等措施会提高效率。