读取文件路径:一层目录(“示例”)、二层目录(“数据1”、“数据2”)下的表格数据。
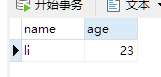
“示例”文件下:
“数据1”文件下:

“数据2”文件下:

读取文件夹
rm(list=ls()) #清除变量
# getwd() #获取当前的工作目录
setwd("D:/data_r") #指定工作目录
first_file_name <- list.files("示例") #使用list.files得到“示例”文件夹的所有文件夹的名称
dir <- paste("./示例/",first_file_name,sep = "") #用paste命令构建路径变量dir
n <- length(dir) #读取dir长度(“示例”文件下的文件个数)n_sub <- rep(0,n) #生成n个0向量
n_sub <- as.data.frame(n_sub) #转换成数据框
n_sub <- t(n_sub) #转置
读取数据时先读取一个表的数据保存在data中,后续读取的表格数据使用cbind函数依次添加到data中。
data <- readxl::read_excel("D:/data_r/示例/数据1/表一.xlsx")
for (i in 1:n) { b=list.files(dir[i]) #读取“示例”下各个文件夹的表print(b)n_sub[i]=length(b) #把“示例”下各个文件夹的表的个数存在n_sub中for (j in 1:n_sub[i]) {file=paste(dir[i],"/",b[j],sep = "")new_data <- readxl::read_excel(file)print(dim(new_data))# new_data <- new_data[-1,] #删除第一行# names(new_data) <- NULL #会报错if(i==1&j==2){ #读到表一的数据跳过next} else{data <- rbind(data,new_data) #rbind合并两个数据框,不用担心行名的问题}}
}
输出:

数据处理
data1 <- data[nchar(data$联系方式)==11,] # 筛选出电话号码是11位
dim(data1)data2 <- data1[!duplicated(data1$联系方式),] # 电话号码去重后的数据
dim(data2)write.table(data2,"去重数据.csv",sep=",",row.names = FALSE) # 写入数据
可参考链接:https://www.cnblogs.com/lzllovesyl/p/5170032.html