首先准备测试数据*(mtcars)分别为CSV. TXT
**2018博客之星评选,如果喜欢我的文章,请投我一票,编号:No.009** [支持连接](https://blog.csdn.net/HHTNAN/article/details/85330758) ,万分感谢!!!
R语言数据分析案例:直通车
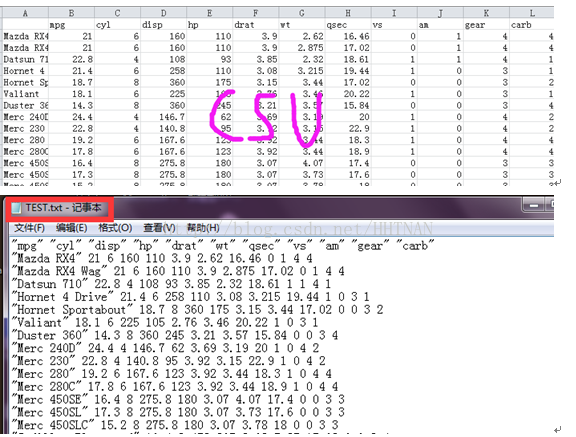
read.table 默认形式读取CSV(×)与TXT(效果理想)
①
> test<-read.table("C:/Users/admin/Desktop/test.txt",header = F)
Error in scan(file = file, what = what, sep = sep, quote = quote, dec = dec, : line 1 did not have 12 elements
> test<-read.table("C:/Users/admin/Desktop/test.txt")
> str(test)
'data.frame': 32 obs. of 11 variables:$ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...$ cyl : int 6 6 4 6 8 6 8 4 4 6 ...$ disp: num 160 160 108 258 360 ...$ hp : int 110 110 93 110 175 105 245 62 95 123 ...$ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...$ wt : num 2.62 2.88 2.32 3.21 3.44 ...$ qsec: num 16.5 17 18.6 19.4 17 ...$ vs : int 0 0 1 1 0 1 0 1 1 1 ...$ am : int 1 1 1 0 0 0 0 0 0 0 ...$ gear: int 4 4 4 3 3 3 3 4 4 4 ...$ carb: int 4 4 1 1 2 1 4 2 2 4 ...
> attributes(test)
$names[1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb"$class
[1] "data.frame"$row.names[1] "Mazda RX4" "Mazda RX4 Wag" "Datsun 710" "Hornet 4 Drive" [5] "Hornet Sportabout" "Valiant" "Duster 360" "Merc 240D" [9] "Merc 230" "Merc 280" "Merc 280C" "Merc 450SE"
[13] "Merc 450SL" "Merc 450SLC" "Cadillac Fleetwood" "Lincoln Continental"
[17] "Chrysler Imperial" "Fiat 128" "Honda Civic" "Toyota Corolla"
[21] "Toyota Corona" "Dodge Challenger" "AMC Javelin" "Camaro Z28"
[25] "Pontiac Firebird" "Fiat X1-9" "Porsche 914-2" "Lotus Europa"
[29] "Ford Pantera L" "Ferrari Dino" "Maserati Bora" "Volvo 142E"
②效果不理想,没有data.frame
> test<-read.table("C:/Users/admin/Desktop/test.csv")
#变量类型识别遗漏
> str(test)
'data.frame': 33 obs. of 2 variables:$ V1: Factor w/ 33 levels "","AMC Javelin",..: 1 19 20 6 14 15 32 8 22 21 ...$ V2: Factor w/ 33 levels ",\"mpg\",\"cyl\",\"disp\",\"hp\",\"drat\",\"wt\",\"qsec\",\"vs\",\"am\",\"gear\",\"carb\"",..: 1 20 21 25 23 16 15 5 27 26 ...
> attributes(test)
$names
[1] "V1" "V2"$class
[1] "data.frame"$row.names[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
> test<-read.table("C:/Users/admin/Desktop/test.csv")
#变量类型识别遗漏
> str(test)
'data.frame': 33 obs. of 2 variables:$ V1: Factor w/ 33 levels "","AMC Javelin",..: 1 19 20 6 14 15 32 8 22 21 ...$ V2: Factor w/ 33 levels ",\"mpg\",\"cyl\",\"disp\",\"hp\",\"drat\",\"wt\",\"qsec\",\"vs\",\"am\",\"gear\",\"carb\"",..: 1 20 21 25 23 16 15 5 27 26 ...
> attributes(test)
$names
[1] "V1" "V2"$class
[1] "data.frame"$row.names[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33修改后:还可以具体根据自己需要
③
> test<-read.table("C:/Users/admin/Desktop/test.csv",header = T,sep=",")
> str(test)
'data.frame': 32 obs. of 12 variables:$ X : Factor w/ 32 levels "AMC Javelin",..: 18 19 5 13 14 31 7 21 20 22 ...$ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...$ cyl : int 6 6 4 6 8 6 8 4 4 6 ...$ disp: num 160 160 108 258 360 ...$ hp : int 110 110 93 110 175 105 245 62 95 123 ...$ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...$ wt : num 2.62 2.88 2.32 3.21 3.44 ...$ qsec: num 16.5 17 18.6 19.4 17 ...$ vs : int 0 0 1 1 0 1 0 1 1 1 ...$ am : int 1 1 1 0 0 0 0 0 0 0 ...$ gear: int 4 4 4 3 3 3 3 4 4 4 ...$ carb: int 4 4 1 1 2 1 4 2 2 4 ...
> attributes(test)
$names[1] "X" "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb"$class
[1] "data.frame"$row.names[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
④效果同③ read.table 是读取矩形格子状数据最为便利的方式
> test<-read.csv("C:/Users/admin/Desktop/test.csv",head=T,sep=",")
> str(test)
'data.frame': 32 obs. of 12 variables:$ X : Factor w/ 32 levels "AMC Javelin",..: 18 19 5 13 14 31 7 21 20 22 ...$ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...$ cyl : int 6 6 4 6 8 6 8 4 4 6 ...$ disp: num 160 160 108 258 360 ...$ hp : int 110 110 93 110 175 105 245 62 95 123 ...$ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...$ wt : num 2.62 2.88 2.32 3.21 3.44 ...$ qsec: num 16.5 17 18.6 19.4 17 ...$ vs : int 0 0 1 1 0 1 0 1 1 1 ...$ am : int 1 1 1 0 0 0 0 0 0 0 ...$ gear: int 4 4 4 3 3 3 3 4 4 4 ...$ carb: int 4 4 1 1 2 1 4 2 2 4 ...
> attributes(test)
$names[1] "X" "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb"$class
[1] "data.frame"$row.names[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
⑤:read.csv读txt。丢失数据结构,1 variable
> test<-read.csv("C:/Users/admin/Desktop/test.txt",head=T,sep=",")
> str(test)
'data.frame': 32 obs. of 1 variable:$ mpg.cyl.disp.hp.drat.wt.qsec.vs.am.gear.carb: Factor w/ 32 levels "AMC Javelin 15.2 8 304 150 3.15 3.435 17.3 0 0 3 2",..: 18 19 5 13 14 31 7 21 20 22 ...
> attributes(text)
NULL
> attributes(test)
$names
[1] "mpg.cyl.disp.hp.drat.wt.qsec.vs.am.gear.carb"$class
[1] "data.frame"$row.names[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
⑥使用readr包中read_csv读取情况,其适合
> test<-read_csv("C:/Users/admin/Desktop/test.csv")
Parsed with column specification:
cols(X1 = col_character(),mpg = col_double(),cyl = col_integer(),disp = col_double(),hp = col_integer(),drat = col_double(),wt = col_double(),qsec = col_double(),vs = col_integer(),am = col_integer(),gear = col_integer(),carb = col_integer()
)
Warning message:
Missing column names filled in: 'X1' [1]
> test
# A tibble: 32 × 12X1 mpg cyl disp hp drat wt qsec vs am gear carb<chr> <dbl> <int> <dbl> <int> <dbl> <dbl> <dbl> <int> <int> <int> <int>
1 Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
2 Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
3 Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
4 Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
5 Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
6 Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
7 Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
8 Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
9 Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
10 Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
# ... with 22 more rows> str(test)
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 32 obs. of 12 variables:$ X1 : chr "Mazda RX4" "Mazda RX4 Wag" "Datsun 710" "Hornet 4 Drive" ...$ mpg : num 21 21 22.8 21.4 18.7 18.1 14.3 24.4 22.8 19.2 ...$ cyl : int 6 6 4 6 8 6 8 4 4 6 ...$ disp: num 160 160 108 258 360 ...$ hp : int 110 110 93 110 175 105 245 62 95 123 ...$ drat: num 3.9 3.9 3.85 3.08 3.15 2.76 3.21 3.69 3.92 3.92 ...$ wt : num 2.62 2.88 2.32 3.21 3.44 ...$ qsec: num 16.5 17 18.6 19.4 17 ...$ vs : int 0 0 1 1 0 1 0 1 1 1 ...$ am : int 1 1 1 0 0 0 0 0 0 0 ...$ gear: int 4 4 4 3 3 3 3 4 4 4 ...$ carb: int 4 4 1 1 2 1 4 2 2 4 ...- attr(*, "spec")=List of 2..$ cols :List of 12.. ..$ X1 : list().. .. ..- attr(*, "class")= chr "collector_character" "collector"
c"
> attributes(test)
$class
[1] "tbl_df" "tbl" "data.frame"$row.names[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32$names[1] "X1" "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb"$spec
cols(X1 = col_character(),mpg = col_double(),cyl = col_integer(),disp = col_double(),hp = col_integer(),drat = col_double(),wt = col_double(),qsec = col_double(),vs = col_integer(),am = col_integer(),gear = col_integer(),carb = col_integer()
)⑦read_csv对于test.txt ×
> test<-read_csv("C:/Users/admin/Desktop/test.txt")
Parsed with column specification:
cols(`mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb` = col_character()
)
Warning: 64 parsing failures.
row col expected actual1 mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb delimiter or quote 1 mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb delimiter or quote M1 mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb delimiter or quote 1 mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb delimiter or quote D1 mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb delimiter or quote
... ................................................................ .................. ......
See problems(...) for more details.> test
# A tibble: 1 × 1`mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb`<chr>
1 Mazda RX4" 21 6 160 110 3.9 2.62 16.46 0 1 4 4\r\n"Mazda RX4 Wag" 21 6 160 110 3.9 2.875 17.02 0 1 4 4\r\n"Datsun 710" 22.8 4
> str(test)
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 1 obs. of 1 variable:$ mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb: chr "Mazda RX4\" 21 6 160 110 3.9 2.62 16.46 0 1 4 4\r\n\"Mazda RX4 Wag\" 21 6 160 110 3.9 2.875 17.02 0 1 4 4\r\n\"Datsun 710\" 22."| __truncated__- attr(*, "problems")=Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 64 obs. of 4 variables:..$ row : int 1 1 1 1 1 1 1 1 1 1 .....$ col : chr "mpg\" \"cyl\" \"disp\" \"hp\" \"drat\" \"wt\" \"qsec\" \"vs\" \"am\" \"gear\" \"carb" "mpg\" \"cyl\" \"disp\" \"hp\" \"drat\" \"wt\" \"qsec\" \"vs\" \"am\" \"gear\" \"carb" "mpg\" \"cyl\" \"disp\" \"hp\" \"drat\" \"wt\" \"qsec\" \"vs\" \"am\" \"gear\" \"carb" "mpg\" \"cyl\" \"disp\" \"hp\" \"drat\" \"wt\" \"qsec\" \"vs\" \"am\" \"gear\" \"carb" .....$ expected: chr "delimiter or quote" "delimiter or quote" "delimiter or quote" "delimiter or quote" .....$ actual : chr " " "M" " " "D" ...- attr(*, "spec")=List of 2..$ cols :List of 1.. ..$ mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear" "carb: list().. .. ..- attr(*, "class")= chr "collector_character" "collector"..$ default: list().. ..- attr(*, "class")= chr "collector_guess" "collector"..- attr(*, "class")= chr "col_spec"
其他复杂参数解读:
"相关更多参数read.table(file, header = FALSE, sep = "", quote = "\"'",dec = ".", numerals = c("allow.loss", "warn.loss", "no.loss"),row.names, col.names, as.is = !stringsAsFactors,na.strings = "NA", colClasses = NA, nrows = -1,skip = 0, check.names = TRUE, fill = !blank.lines.skip,strip.white = FALSE, blank.lines.skip = TRUE,comment.char = "#",allowEscapes = FALSE, flush = FALSE,stringsAsFactors = default.stringsAsFactors(),fileEncoding = "", encoding = "unknown", text, skipNul = FALSE)
常用参数解读:
file表示要读取的文件。file可以是
①绝对路径或者相对路径,但是一定要注意,因为在R语言中\是转义符,所以路径分隔符必须写成\\,比如“C:\\myfile\\myfile.txt”或者
Sys.setenv(JAVA_HOME='C://Program Files/Java/jdk1.6.0_21/jre')②可以使剪切板的内容。③使用file.choose(),弹出对话框,让你选择文件位置。
header来确定数据文件中第一行是不是标题。默认F,即认为数据文件没有标题
参数----------Arguments----------参数:sep
字段分隔符。文件的每一行的值是通过这个角色分离。如果sep = ""(默认read.table)分隔符是“白色空间”,这是一个或多个空格,制表符,换行符或回车。
参数:quote引用字符集。完全禁用引用,使用quote = ""。看到scan引号中嵌入引号的行为。只考虑读的性格,这是所有这些,除非colClasses指定的列引用。参数:dec字符用于在小数点文件。
参数:row.names向量的行名。这可以是一个向量,给予实际的行名,或一个号码表,其中包含的行名,或字符串,包含行名称表列的名称列。如果有一个头的第一行包含列数少一个领域,在输入的第一列用于行名称。否则,如果row.names丢失,行编号。使用row.names = NULL部队排编号。失踪或NULLrow.names,生成的行被认为是“自动”(而不是由as.matrix保存)的名称。
参数:col.names可选名称为变量的向量。默认是使用列数"V"其次。
参数:as.isread.table的默认行为转换成字符变量(而不是转换为逻辑,数字或复杂的)因素。变量as.is控制转换colClasses没有其他指定的列。它的值是一个逻辑值向量(如果有必要回收价值),或数字或字符索引指定的列不应该被转换为因素的向量。注:禁止所有的转换,包括那些数字列,设置colClasses = "character"。请注意,as.is指定每列(而不是每个变量)等行名称的列(如有)及任何要跳过的列。参数:na.stringsNA值作为解释的字符串的字符向量。空白领域也被认为是缺少逻辑,整数,数字和复杂的领域中的价值。
参数:colClasses字符。须承担一个班的向量为列。必要时,回收或如果被命名为特征向量,未指定的值是NA。可能的值是NA(默认情况下,当type.convert)"NULL"(列时跳过),一个原子的向量类(逻辑,整数,数字,复杂的,性格,原材料),或"factor","Date"或"POSIXct"。否则需要有一个as从methods转换到指定的正规类的方法(包"character")。请注意,colClasses指定每列(而不是每个变量)等行名称(如有)列。
参数:nrows整数:最大数量的行读入负和其他无效值将被忽略。
参数:skip整数:开始读取数据前跳过的数据文件的行数。
参数:check.names
l
逻辑。如果TRUE然后检查数据框中的变量的名称,以确保它们是语法上有效的变量名。如果有必要,他们调整(make.names),使他们,同时也确保没有重复。
参数:fill逻辑。如果TRUE然后在情况下,行有长度不等的空白领域隐式添加。见“详细资料”。
参数:strip.white逻辑。只用当sep已指定,并允许剥离的非上市character(numeric领域总是剥离领域)的开头和结尾的空白。看到scan进一步详情(包括“白色空间”的确切含义),记住,列可能包含的行名。
参数:blank.lines.skip逻辑:如果TRUE在输入空行被忽略。
参数:comment.char性格:特征向量的长度包含单个字符或一个空字符串之一。使用""完全关闭评论的解释。
参数:allowEscapes逻辑。如\n处理或逐字读(默认)C风格逃逸?请注意,如果不是引号内的这些都可以解释为分隔符(而不是作为一个注释字符)。详细内容见scan。
参数:flush逻辑:如果TRUE,scan将刷新行结束后阅读领域的最后要求。这允许把意见后,最后一个字段。
参数:stringsAsFactors逻辑:特征向量转换的因素?请注意,这是由as.is和colClasses,这两者可以更好地控制覆盖。参数:fileEncoding字符串:如果非空的声明文件(未连接)上使用这样的字符数据可以被重新编码的编码。看到“编码”部分,帮助file“R数据导入/导出手册”和“注意”。
参数:encoding假设输入字符串编码。它是用来作为已知的Latin-1或UTF-8(见标记字符串Encoding):不使用它来重新编码输入,但允许R在他们的本地编码处理编码的字符串(如果这两个标准之一)。看到“价值”。参数:text参数:text字符串:file如果不提供的,这是,那么数据是从text值读通过的文本连接。请注意,一个文字字符串,可用于包括(小)R代码集内的数据。和read.table有所不同的,是read.csv的默认参数有别。注意看,header和sep的默认值。read.csv(file, header = TRUE, sep = ",", quote = "\"",dec = ".", fill = TRUE, comment.char = "", ...