上午翻源码,翻到了原来学习数据结构时自己实现的链表源码,特此总结一下。源码可能有很多不完善的地方,请多谅解。
按照惯例,还是先来介绍下什么是链表。
链表是一种数据结构,在内存中通过节点记录内存地址而相互链接形成一条链的储存方式。相比数组而言,链表在内存中不需要连续的区域,只需要每一个节点都能够记录下一个节点的内存地址,通过引用进行查找,这样的特点也就造就了链表增删操作时间消耗很小,而查找遍历时间消耗很大的特点。
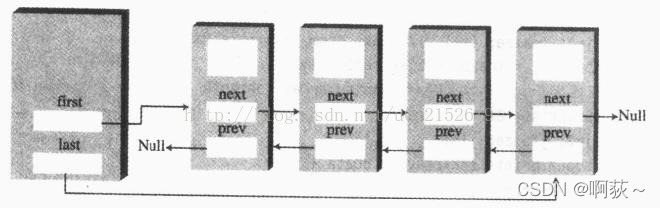
我们日常在Java中使用的LinkedList即为双向链表。而在链表是由其基本组成单元节点(Node)来实现的。我们在日常中见到的链表大部分都是单链表和双链表,在我前面文章中《数据机构——栈的基本总结》中,其中一个栈便是用单链表进行实现。这两种链表在实现思维上基本一致,只不过在插入、删除等操作实现上有所区别。
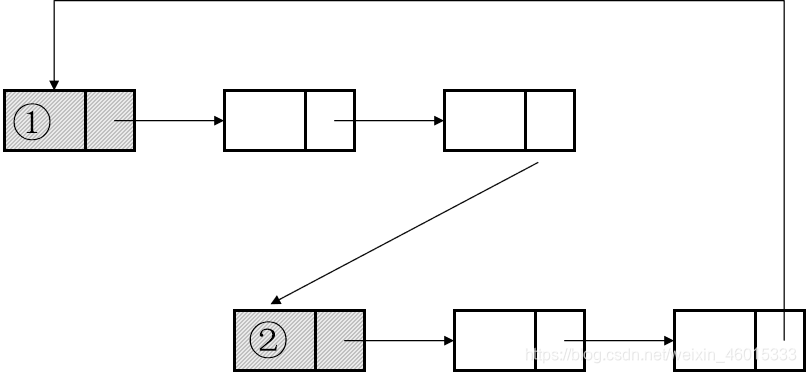
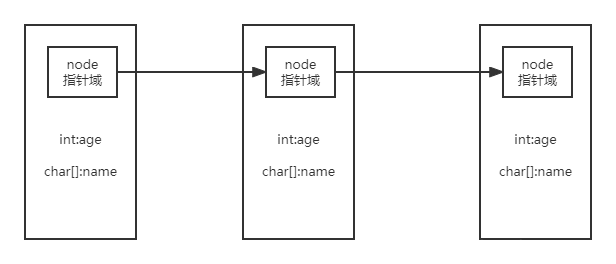
两种链表结构如图所示:

从图中可以看出,二者主要差别在于内部的Node类。单链表只需要一个指向下一个节点的引用Next,而双向链表则需要指向前一个Node的prev和下一个Node的Next。
单链表
在我们实现一个链表时,一定要主要引用的使用,如果一旦引用指向空,很可能再也取不到这些数据。因此,如果不缺的自己到底需要几个引用来指向不同的节点来实现不同的需求,可以多创建几个节点。
按照我的习惯,我一般会创建三个引用用于链表的各项操作。
- theHeadPointer 头引用,始终指向链表头部,用于遍历链表,在头部增删数据等操作。
- theLastPointer 尾引用,始终指向链表尾部,用于在尾部新增数据,同时可以用于删除数据。
- theCurrentPointer 当前引用(也称哨兵引用),使用较为灵活,可以在操作数据时作为保险。
下图为单链表的数据操作步骤。

单链表的实现在这里就不详细用代码描述了,相信看完双链表再操作单链表会很熟练。
双向链表
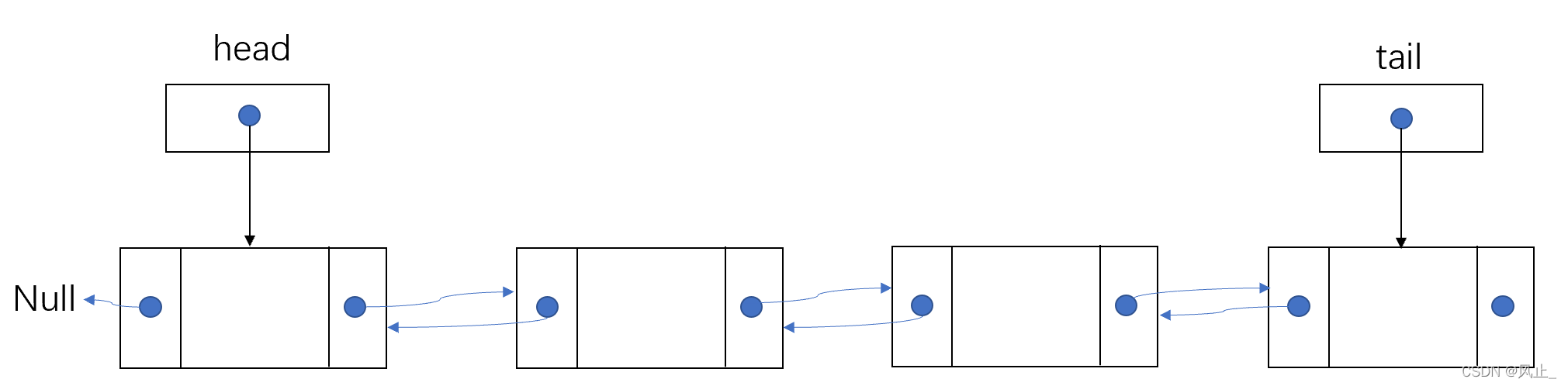
在开头已经指出,二者最大的不同就是引用指向不同。实际上,在日常中,双向链表应用更加广泛,相比单链表,双向链表可从头尾两端进行遍历的特点非常具有优势,当我们需要查找最新的数据时,我们可从尾部开始遍历,需要查找旧数据时,从头部开始遍历,这样能大大减少遍历链表所需要的昂贵的花费。而单链表则只能从头部开始遍历。
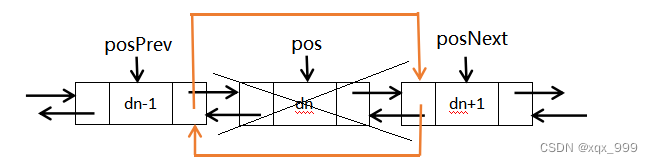
下图为双向链表的操作.

双向链表的添加删除操作实现原理基本相同,只是在我们删除前,一定要保证删除节点的后一个节点有引用,否则很容易再也无法获得后面数据,为了防止这种情况,可以多创建几个引用,以防万一。下面就是自己实现双链表的代码。
为了节省空间,没有将Node类中Get和Set方法写出,大家理解一下。
public class DoubleLinkedListNode {//数据 private Object element;// 前指针private DoubleLinkedListNode pre;// 后指针private DoubleLinkedListNode next;public DoubleLinkedListNode(DoubleLinkedListNode pre, Object element, DoubleLinkedListNode next) {this.element = element;this.pre = pre;this.next = next;}
}下面就是链表实现
package MyLinkedList;public class DoubleLinkedList {/** 双向链表中我们要实现插入,删除,查找等操作*///头节点private DoubleLinkedListNode theHeadNode = null;//头引用,用于获得内存中的数据private DoubleLinkedListNode theHeadPointer;//当前节点引用private DoubleLinkedListNode currentPointer;//新建节点引用private DoubleLinkedListNode newPointer;//删除节点引用private DoubleLinkedListNode removePointer;//查找节点引用private DoubleLinkedListNode selectPointer;//节点计数器private int size = 0;public DoubleLinkedListNode remove(Object element) {//删除操作,删除特定数据while(element.equals(removePointer.getElement()) == false) {removePointer = removePointer.getNext(); }removePointer.getPre().setNext(removePointer.getNext());removePointer.getNext().setPre(removePointer.getPre());return removePointer;}public int insert(Object element) {//插入操作if(theHeadNode == null && size == 0) {//将头节点实例化,并将头指针指向头节点,节点计数器自增theHeadNode = new DoubleLinkedListNode(null, element, null);theHeadPointer = theHeadNode;size++;return 1;}else if(theHeadNode != null) {//创建的新节点,该节点前引用指向currentPointernewPointer = new DoubleLinkedListNode(currentPointer, element, null);currentPointer.setNext(newPointer);//将当前节点设置为新建的节点currentPointer = newPointer;size++;return 1;}else {return 0;}}public boolean select(Object element) {//查找操作while(element.equals(selectPointer.getElement()) == false) {selectPointer = selectPointer.getNext();if(element.equals(selectPointer.getElement()) == true) {return true;}}return false;}public int size() {//判断链表内元素个数return size;}public boolean isEmpty() {//判断链表是否为空if(theHeadNode == null) {return true;}else {return false;}}}
从代码中可见,我用了非常多的引用,因为当时在写的时候,逻辑还是不是很清晰,这样起码能保证数据不会丢失,当然一定会有更简单多的方法,大家可以分享出来。
请大家多多指出错误,共同进步!








![[数据结构]链表之单链表(详解)](https://img-blog.csdnimg.cn/img_convert/f6ed3314eddf8402f6ee6b39edb0f283.png)