目录
- 单链表
- 双链表
- 数组结构和链式结构的对比
线性表中,除了顺序表这一重要的结构,还有链式结构,而这也是我们常说的链表。

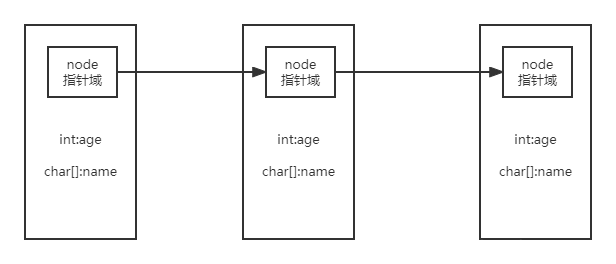
一般是通过定义结构体(类)的方式来表示链表的每一个结点。一般而言,链表的结点都会有数据域和地址域。数据域是用来存放数据的,而地址域是用来链接结点的。
常用的链表结构分为:
- 带头节点的和不带头结点的
- 单指针的和双指针的
- 循环的和不循环的
本次的链表结构的实现用C语言来实现。
代码也上传到Gitee
单链表
这次是实现的单链表是无头节点不循环的链表。
分文件实现:.h文件放的是相关函数的声明,.c文件是函数的定义。
.h文件
//无哨兵位结点单向不循环链表的实现#include<stdio.h>
#include<stdlib.h>
#include<assert.h>//定义链表的数据类型
typedef int SLListDataType;//定义结构体的结点
typedef struct SLListNode {SLListDataType data;struct SLListNode* next;}SLLN;//动态申请一个结点
SLLN* BuySLListNode(SLListDataType x);//单链表的销毁
void SLListDestory(SLLN* plist);//单链表打印
void SLListPrint(SLLN* plist);//单链表尾插
void SLListPushBack(SLLN** plist, SLListDataType x);//单链表尾删
void SLListPopBack(SLLN** plist);//单链表头插
void SLListPushFront(SLLN** plist, SLListDataType x);//单链表头删
void SLListPopFront(SLLN** plist);//单链表查找某个数据
SLLN* SLListFind(SLLN* plist, SLListDataType x);//单链表在pos位置之前插入x,传入的pos应为结构体地址
void SLListInsert(SLLN** plist, SLLN* pos, SLListDataType x);//单链表在pos位置之后插入x
void SLListInsertAfter(SLLN* plist, SLLN* pos, SLListDataType x);//单链表删除在pos位置的值
//删除pos的位置,需要先得到该位置的上一个结点的位置
//这样我们才能把上一个结点和下一个结点连在一起
//所以一般是删除pos后面的那个结点
void SLListErase(SLLN** plist, SLLN* pos);void SLListEraseAfter(SLLN* plist, SLLN* pos);
typedef结点的数据类型,后续修改,函数中的实现不需要更改
定义结构体类型,包含数据域和指针域
结点需要动态申请,所以使用malloc函数
实现一个打印的函数,是为了方便检验函数是否实现正确
尾插函数是再链表的最后添加一个结点
尾删是把链表最后的结点删除
头插是在链表的头部加入一个新的结点,并且头指针指向新的结点
头删是把链表头部的结点删除,头指针指向下一个结点
查找数据是根据数据域的值来查找,当然也可以设计成根据具体的下标来查找
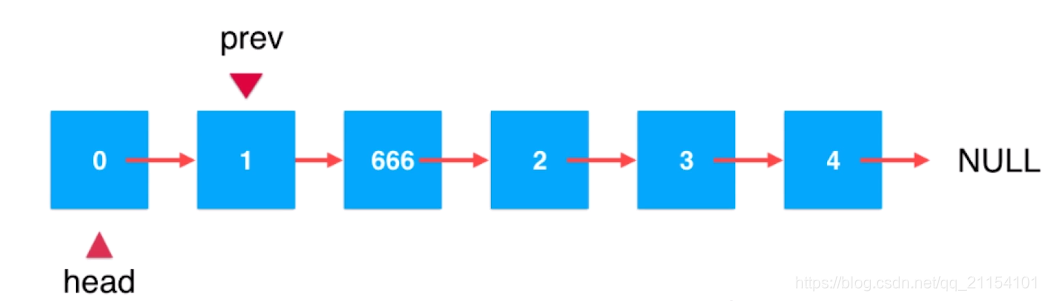
单链表在某一个位置插入一个结点,不需要想数组一样需要移动数据
.c文件
//无哨兵位头节点单向不循环链表的实现#include"SingleLinkedList.h"//动态申请一个结点并赋值
SLLN* BuySLListNode(SLListDataType x) {//开辟一个结点的空间SLLN* tmp = (SLLN*)malloc(sizeof(SLLN));//判断返回的指针是否为空if (tmp == NULL) {exit(-1);}else {//每次申请一个结点,该结点的放入需要存储的数据,next指针为空tmp->next = NULL;tmp->data = x;}return tmp;}//单链表的销毁
void SLListDestory(SLLN** plist) {assert(*plist && plist);SLLN* p = *plist;while (*plist != NULL) {p = *plist;*plist = p->next;free(p);}}//单链表打印
void SLListPrint(SLLN* plist) {//判断传入的指针是否为空//assert(plist);while (plist != NULL) {//打印格式要根据SLListDataType的类型来确定printf("%d->", plist->data);plist = plist->next;}printf("NULL\n");
}//单链表尾插
//这里传入的是结构体的二级指针,目的是为了修改外面的结构体指针,使其指向动态开辟的空间
void SLListPushBack(SLLN** plist, SLListDataType x) {//判断传入的二级指针是否为空assert(plist);SLLN* newnode = BuySLListNode(x);SLLN* p = *plist;if (*plist == NULL) {*plist = newnode;}else {while (p->next != NULL) {p = p->next;}p->next = newnode;}}//单链表尾删
//如果单链表只有一个结点,那么尾删后就没有结点了,我们就需要把plist置空
void SLListPopBack(SLLN** plist) {//判断传入的结构体指针是否为空,若为空则表示一个节点都没有,不需要再删除assert(*plist);//定义两个指针,用于记录最后的结点和倒数第二个的结点SLLN* tail = *plist;SLLN* prev = NULL;while (tail->next != NULL) {prev = tail;tail = tail->next;}//如果单链表中只有一个结点,那么我们直接free就可以了if (prev == NULL) {free(tail);*plist = NULL;}else {free(tail);prev->next = NULL;}}//单链表头插
//同理,这里也需要传入二级指针
void SLListPushFront(SLLN** plist, SLListDataType x) {SLLN* newnode = BuySLListNode(x);SLLN* p = *plist;if (*plist == NULL) {*plist = newnode;}else{newnode->next = p;*plist = newnode;}}//单链表头删
//需要改变头指针的指向,所以也需要传入二级指针
void SLListPopFront(SLLN** plist) {//判断是否至少有一个结点assert(*plist);SLLN* p = *plist;*plist = (*plist)->next;free(p);}//单链表查找某个数据
//如果找到了,返回指向该节点的地址
SLLN* SLListFind(SLLN* plist, SLListDataType x) {//判断传入的指针是否为空assert(plist);SLLN* p = plist;//当p为空指针时退出循环while (p) {if (p->data == x) {return p;}p = p->next;}return NULL;}//单链表在pos位置之后插入x
void SLListInsertAfter(SLLN* plist, SLLN* pos, SLListDataType x) {//判断传入的两个指针是否为空assert(plist && pos);SLLN* p = plist;while (p != pos) {//如果p为NULL,说明已经遍历完整个链表了,但是并没有找到合适的posif (p == NULL) {printf("输入的pos不存在\n");return;}p = p->next;}SLLN* newnode = BuySLListNode(x);newnode->next = p->next;p->next = newnode;}//单链表在pos位置之前插入x
//可能会出现头插的情况,因此这里也需要传入一个二级结构体指针
//此时需要定义两个结构体指针,一个指向pos另外一个指向pos前面的一个结点
void SLListInsert(SLLN** plist, SLLN* pos, SLListDataType x) {assert(plist && pos);SLLN* prev = NULL;SLLN* tail = *plist;SLLN* newnode = BuySLListNode(x);if (tail == pos) {//此时相当于头插,可以直接调用头插的接口newnode->next = *plist;*plist = newnode;}else {//这里tail != NULL 是防止遍历完链表后还没有找到pos 的情况//此处设计为如果遍历完链表后还没有找到pos那么就在最后插入该数据while (tail != pos && tail != NULL) {prev = tail;tail = tail->next;}prev->next = newnode;newnode->next = tail;}}//单链表删除在pos位置的值
//有可能出现头删的情况,因此也需要传入二级指针来改变头指针指向的头结点
void SLListErase(SLLN** plist, SLLN* pos) {assert(plist && pos);SLLN* prev = NULL;SLLN* tail = *plist;if (tail == pos) {*plist = tail->next;free(tail);}else {while (tail != pos) {//防止pos无效,使得遍历完整个链表后都没有找到posassert(tail);prev = tail;tail = tail->next;}prev->next = tail->next;free(tail);}}void SLListEraseAfter(SLLN* plist, SLLN* pos) {SLLN* p = plist;SLLN* tmp = NULL;while (p != pos) {//不允许传入无效的pos和删除最后一个结点之后的数据assert(p);p = p->next;}//不允许删除最后一个结点的后一个结点assert(p->next);tmp = p->next;p->next = tmp->next;free(tmp);}
需要注意的点:
- 尾删的时候,需要先遍历链表找到最后一个结点和最后一个结点的前一个位置,让前一个位置的结点指向NULL,然后释放最后一个结点
- 头插和头删的时候,会使链表第一个结点的地址发生改变,我们需要让外面的头指针相应的改变,要么使用传入二级指针的方式来进行修改,要么使用返回新的头节点的方式让外面的头指针接收
- 在链表中间插入一个结点的时候,注意断开旧的结点的顺序和链接新的结点的顺序,一定不可以让旧的结点先断开,不然的话就找不到被断开的后半部分了
- 单链表的增删改查不是很方便,所以一般不用作存储数据的结构,但是一般的题目考察的就是单链表,所以也是需要了解的
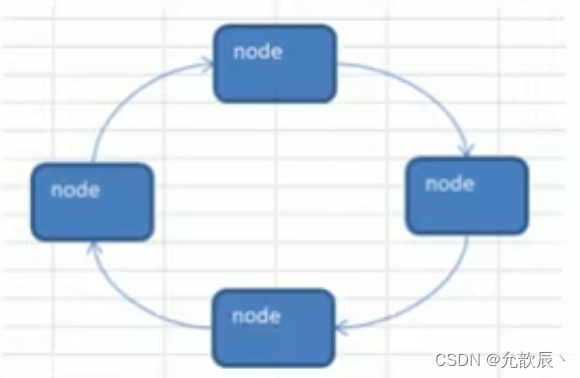
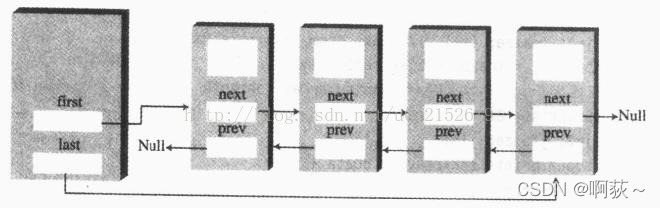
双链表

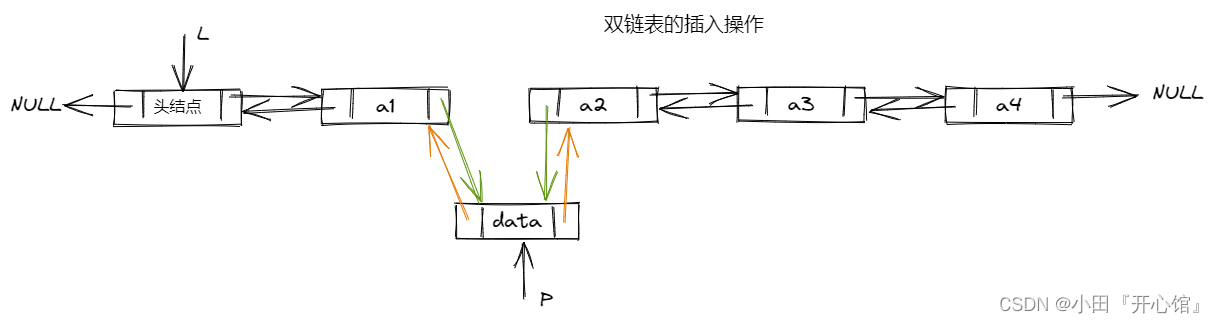
双链表指的是每一个结点都有两个指针,一个是后继指针用来指向下一个结点,一个是前驱指针用来指向前一个结点。
这里还是带有哨兵位的头结点的循环链表,头节点不用来存储数据,唯一作用就是next指针永远指向链表的真正的第一个结点。
.h文件
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>typedef int DataType;typedef struct ListNode {struct ListNode* prev;struct ListNode* next;DataType data;}ListNode;//创建头节点,并返回
ListNode* ListCreat();//链表节点的创建
ListNode* ListNodeBuy(DataType x);//链表的销毁
void ListDestroy(ListNode* pHead);//链表的打印
void ListPrint(ListNode* pHead);//链表的头插
void ListPushFront(ListNode* pHead, DataType x);//链表的头删
void ListPopFront(ListNode* pHead);//链表的尾插
void ListPushBack(ListNode* pHead,DataType x);//链表的尾删
void ListPopBack(ListNode* pHead);//链表的查找
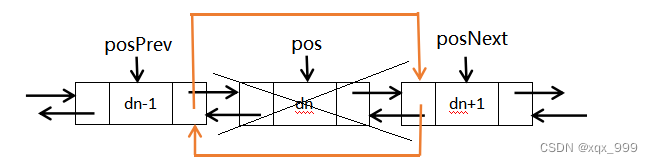
ListNode* ListFind(ListNode* pHead, DataType);//在链表pos位置前面插入一个结点
void ListInsert(ListNode* pos, DataType x);//删除在pos位置上面的结点
void ListErase(ListNode* pos);
双链表的相关的函数定义在.h文件中,大概的功能跟单链表差不多
.c文件
//带头双向循环链表的实现
#include"List.h"//创建头节点,并返回
ListNode* ListCreat() {ListNode* pHead = (ListNode*)malloc(sizeof(ListNode));if (pHead == NULL) {exit(-1);}pHead->next = pHead;pHead->prev = pHead;return pHead;
}//链表节点的创建
ListNode* ListNodeBuy(DataType x) {ListNode* plist = malloc(sizeof(ListNode));if (plist == NULL) {exit(-1);}else {plist->data = x;plist->next = NULL;plist->prev = NULL;return plist;}}//链表的销毁
void ListDestroy(ListNode* pHead) {assert(pHead);assert(pHead->next);ListNode* cur = pHead->next;while (cur != pHead) {ListNode* next = cur->next;free(cur);cur = next;}free(pHead);}//链表的打印
void ListPrint(ListNode* pHead) {assert(pHead);ListNode* cur = pHead->next;while (cur != pHead) {printf("%d ", cur->data);cur = cur->next;}printf("NULL");printf("\n");
}//链表的头插
void ListPushFront(ListNode* pHead, DataType x) {ListNode* newnode = ListNodeBuy(x);pHead->next->prev = newnode;newnode->next = pHead->next;newnode->prev = pHead;pHead->next = newnode;}//链表的头删
void ListPopFront(ListNode* pHead) {assert(pHead->next != pHead);ListNode* tmp = pHead->next;ListNode* Nexttmp = tmp->next;pHead->next = tmp->next;Nexttmp->prev = pHead;free(tmp);
}//链表的尾插
void ListPushBack(ListNode* pHead,DataType x) {ListNode* newnode = ListNodeBuy(x);ListNode* tail = pHead->prev;newnode->next = pHead;newnode->prev = tail;tail->next = newnode;pHead->prev = newnode;}//链表的尾删
void ListPopBack(ListNode* pHead) {assert(pHead->prev != pHead);ListNode* tmp = pHead->prev;ListNode* Prevtmp = tmp->prev;
}//链表的查找
ListNode* ListFind(ListNode* pHead, DataType x) {ListNode* cur = pHead->next;while (cur != pHead) {if (cur->data == x) {return cur;}else {cur = cur->next;}}return NULL;
}//在链表pos位置前面插入一个结点
void ListInsert(ListNode* pos, DataType x) {assert(pos);ListNode* newnode = ListNodeBuy(x);ListNode* posPrev = pos->prev;posPrev->next = newnode;newnode->prev = posPrev;newnode->next = pos;pos->prev = newnode;}//删除在pos位置上面的结点
void ListErase(ListNode* pos) {assert(pos);//不允许删除哨兵位的头节点assert(pos != pos->next);ListNode* Next = pos->next;ListNode* Prev = pos->prev;Prev->next = Next;Next->prev = Prev;free(pos);
}
需要注意的是:
- 由于该双链表能够找到前一个结点和后一个结点,在删除某一个结点的时候,不需要时刻记录着上一个结点
- 因为是循环链表,所以在删除最后的结点的时候,不需要遍历整个链表才能找到尾结点,只需要利用头节点的前驱指针就可以了
- 双向循环的链表一般用于存储数据
数组结构和链式结构的对比
数据结构和链式结构在逻辑结构上都是线性的
但是由于各自的特点,使用的场景也不同
数组的缺点:
- 空间不够了就需要扩容,扩容的消耗挺大的
- 在中间或者头部删除数据或者插入数据,需要移动数据,消耗大
- 一般为了避免频繁的扩容,每次扩容都是扩大为原来的2倍,但是这也可能造成空间的浪费
数组的优点:
- 支持随机访问,可以支持一些需要有序或者随机来访问的算法,如二分查找、快速排序等
- 相对于单链表,尾部删除数据和插入数据不需要遍历,效率较高
链表的缺点:
- 每一个结点除了存储数据还要存储指针,空间消耗较数组大
- 不支持随机访问,寻找某个数据需要遍历
链表的优点:
- 更合理的使用空间,需要存储的时候再申请空间,不会造成空间浪费
- 头部和中间删除数据不需要挪动数据



![[数据结构]链表之单链表(详解)](https://img-blog.csdnimg.cn/img_convert/f6ed3314eddf8402f6ee6b39edb0f283.png)


![[数据结构] 链表(图文超详解讲解)](https://img-blog.csdnimg.cn/1dce295c1ee04702a5a3fb9bbe74a7ce.png)