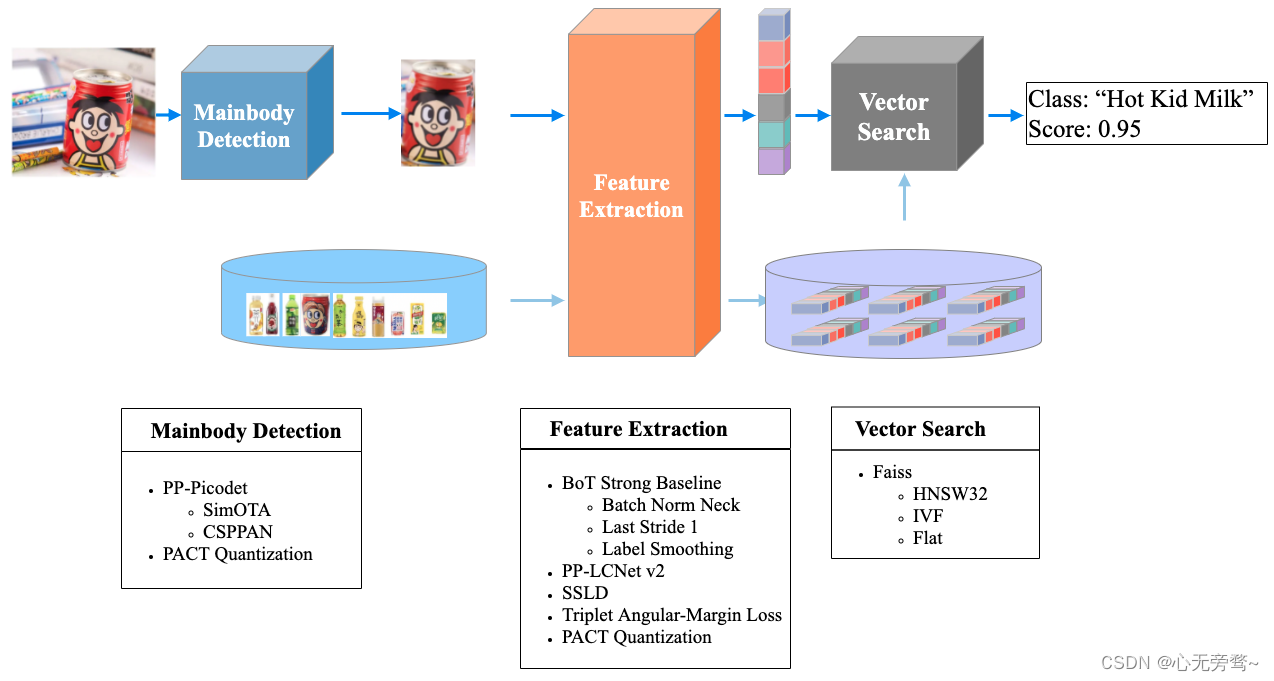
1. PP-ShiTuV2模型介绍
PP-ShiTuV2 是基于 PP-ShiTuV1 改进的一个实用轻量级通用图像识别系统,由主体检测、特征提取、向量检索三个模块构成,相比 PP-ShiTuV1 具有更高的识别精度、更强的泛化能力以及相近的推理速度*。主要针对训练数据集、特征提取两个部分进行优化,使用了更优的骨干网络、损失函数与训练策略,使得 PP-ShiTuV2 在多个实际应用场景上的检索性能有显著提升。
| 模型 | 存储(主体检测+特征提取) | product |
|---|---|---|
| recall@1 | ||
| PP-ShiTuV1 | 64(30+34)MB | 66.8% |
| PP-ShiTuV2 | 49(30+19)MB | 73.8% |
2. 模块介绍与训练
3.1 主体检测
主体检测是目前应用非常广泛的一种检测技术,它指的是检测出图片中一个或者多个主体的坐标位置,然后将图像中的对应区域裁剪下来进行识别。主体检测是识别任务的前序步骤,输入图像经过主体检测后再进行识别,可以过滤复杂背景,有效提升识别精度。
考虑到检测速度、模型大小、检测精度等因素,最终选择 PaddleDetection 自研的轻量级模型 PicoDet-LCNet_x2_5 作为 PP-ShiTuV2 的主体检测模型。
3.2 数据集
在 PaddleClas 的识别任务中,训练主体检测模型时主要用到了以下几个数据集。
| 数据集 | 数据量 | 主体检测任务中使用的数据量 | 场景 | 数据集地址 |
|---|---|---|---|---|
| Objects365 | 170W | 6k | 通用场景 | 地址 |
| COCO2017 | 12W | 5k | 通用场景 | 地址 |
| iCartoonFace | 2k | 2k | 动漫人脸检测 | 地址 |
| LogoDet-3k | 3k | 2k | Logo 检测 | 地址 |
| RPC | 3k | 3k | 商品检测 | 地址 |
在实际训练的过程中,将所有数据集混合在一起。由于是主体检测,这里将所有标注出的检测框对应的类别都修改为 前景 的类别,最终融合的数据集中只包含 1 个类别,即前景。
3.3 模型选择
目标检测方法种类繁多,比较常用的有两阶段检测器(如 FasterRCNN 系列等);单阶段检测器(如 YOLO、SSD 等);anchor-free 检测器(如 PicoDet、FCOS 等)。在主体检测中,我们使用PicoDet系列模型,其在CPU端与移动端,速度较快、精度较好,处于较为领先的业界水平。
基于上述研究,PaddleClas 中提供了 1 个通用主体检测模型,既轻量级主体检测模型,分别适用于端侧场景以及服务端场景。下面的表格中给出了在上述 5 个数据集上的平均 mAP 以及它们的模型大小、预测速度对比信息。
| 模型 | 模型结构 | 预训练模型下载地址 | inference 模型下载地址 | mAP | inference 模型大小(MB) |
|---|---|---|---|---|---|
| 轻量级主体检测模型 | PicoDet | 地址 | tar 格式文件地址 zip 格式文件地址 | 41.5% | 30.1 |
- 注意
- 由于部分解压缩软件在解压上述 tar 格式文件时存在问题,建议非命令行用户下载 zip 格式文件并解压。tar 格式文件建议使用命令 tar xf xxx.tar 解压。
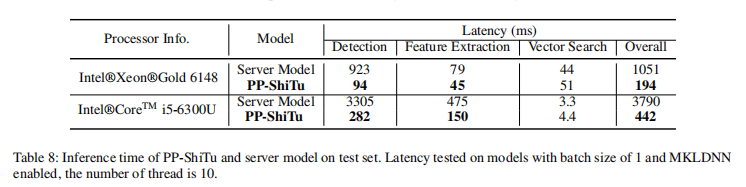
- 速度评测机器的 CPU 具体信息为:Intel® Xeon® Gold 6148 CPU @ 2.40GHz,速度指标为开启 mkldnn,线程数设置为 10 测试得到。
- 主体检测的预处理过程较为耗时,平均每张图在上述机器上的时间在 40~55 ms 左右,没有包含在上述的预测耗时统计中。
3.3.1 轻量级主体检测模型
PicoDet 由 PaddleDetection 提出,是一个适用于 CPU 或者移动端场景的目标检测算法。具体地,它融合了下面一系列优化算法。
- VFL + GFL
- 新的PAN Neck结构
- 余弦学习率策略
- Cycle-EMA
- ATSS及SimOTA 标签分配策略
PP-PicoDet模型有如下特点:
- 🌟 更高的mAP: 第一个在1M参数量之内mAP(0.5:0.95)超越30+(输入416像素时)。
- 🚀 更快的预测速度: 网络预测在ARM CPU下可达150FPS。
- 😊 部署友好: 支持PaddleLite/MNN/NCNN/OpenVINO等预测库,支持转出ONNX,提供了C++/Python/Android的demo。
- 😍 先进的算法: 我们在现有SOTA算法中进行了创新, 包括:ESNet, CSP-PAN, SimOTA等等。
更多关于 PicoDet 的优化细节与 benchmark 可以参考 PicoDet 系列模型介绍。
在轻量级主体检测任务中,为了更好地兼顾检测速度与效果,PP-ShiTuV2使用 PPLCNet_x2_5 作为主体检测模型的骨干网络,同时将训练与预测的图像尺度修改为了 640x640,其余配置与 picodet_l_416_coco.yml 完全一致。将数据集更换为自定义的主体检测数据集,进行训练,最终得到检测模型。
3. 特征提取
特征提取是图像识别中的关键一环,它的作用是将输入的图片转化为固定维度的特征向量,用于后续的 向量检索 。考虑到特征提取模型的速度、模型大小、特征提取性能等因素,最终选择 PaddleClas 自研的 PPLCNetV2_base 作为特征提取网络。相比 PP-ShiTuV1 所使用的 PPLCNet_x2_5,PPLCNetV2_base基本保持了较高的分类精度,并减少了40%的推理时间*。
注: *推理环境基于 Intel® Xeon® Gold 6271C CPU @ 2.60GHz 硬件平台,OpenVINO 推理平台。
在实验过程中发现可以对 PPLCNetV2_base 进行适当的改进,在保持速度基本不变的情况下,让其在识别任务中得到更高的性能,包括:去掉 PPLCNetV2_base 末尾的 ReLU 和 FC、将最后一个 stage(RepDepthwiseSeparable) 的 stride 改为1。
3.1 摘要
特征提取是图像识别中的关键一环,它的作用是将输入的图片转化为固定维度的特征向量,用于后续的向量检索。一个好的特征需要具备“相似度保持性”,即相似度高的图片对,其特征的相似度也比较高(特征空间中的距离比较近),相似度低的图片对,其特征相似度要比较低(特征空间中的距离比较远)。为此Deep Metric Learning领域内提出了不少方法用以研究如何通过深度学习来获得具有强表征能力的特征。
3.2 介绍
为了图像识别任务的灵活定制,我们将整个网络分为 Backbone、 Neck、 Head 以及 Loss 部分,整体结构如下图所示:
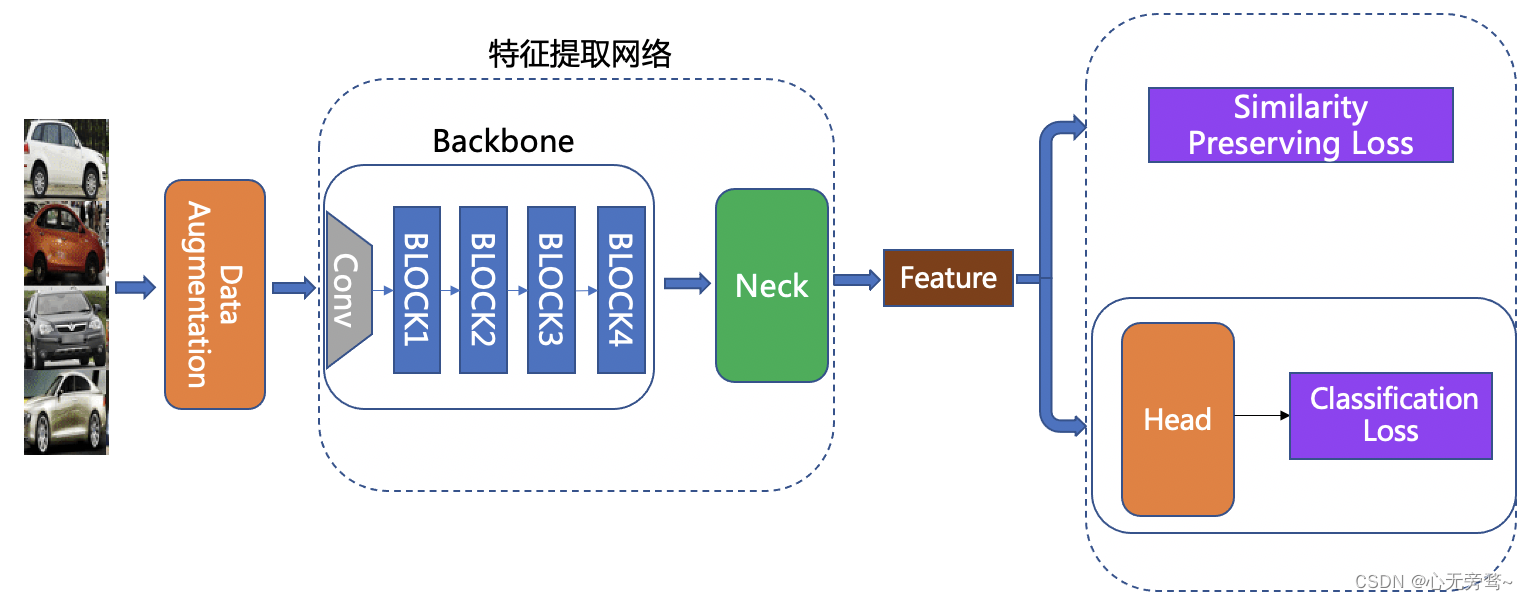
图中各个模块的功能为:
Backbone:用于提取输入图像初步特征的骨干网络,一般由配置文件中的 Backbone 以及 - - BackboneStopLayer 字段共同指定。Neck:用以特征增强及特征维度变换。可以是一个简单的 FC Layer,用来做特征维度变换;也可以是较复杂的 FPN 结构,用以做特征增强,一般由配置文件中的 Neck 字段指定。Head:用来将 Neck 的输出 feature 转化为 logits,让模型在训练阶段能以分类任务的形式进行训练。除了常用的 FC Layer 外,还可以替换为 CosMargin, ArcMargin, CircleMargin 等模块,一般由配置文件中的 Head 字段指定。Loss:指定所使用的 Loss 函数。我们将 Loss 设计为组合 loss 的形式,可以方便地将 Classification Loss 和 Metric learning Loss 组合在一起,一般由配置文件中的 Loss 字段指定。
3.3 方法
3.3.1 Backbone
Backbone 部分采用了 PP-LCNetV2_base,其在 PPLCNet_V1 的基础上,加入了包括Rep 策略、PW 卷积、Shortcut、激活函数改进、SE 模块改进等多个优化点,使得最终分类精度与 PPLCNet_x2_5 相近,且推理延时减少了40%*。在实验过程中我们对 PPLCNetV2_base 进行了适当的改进,在保持速度基本不变的情况下,让其在识别任务中得到更高的性能,包括:去掉 PPLCNetV2_base 末尾的 ReLU 和 FC、将最后一个 stage(RepDepthwiseSeparable) 的 stride 改为1。
注: *推理环境基于 Intel® Xeon® Gold 6271C CPU @ 2.60GHz 硬件平台,OpenVINO 推理平台。
3.3.2 Neck
Neck 部分采用了 BN Neck,对 Backbone 抽取得到的特征的每个维度进行标准化操作,减少了同时优化度量学习损失函数和分类损失函数的难度,加快收敛速度。
3.3.3 Head
Head 部分选用 FC Layer,使用分类头将 feature 转换成 logits 供后续计算分类损失。
3.3.4 Loss
Loss 部分选用 Cross entropy loss 和 TripletAngularMarginLoss,在训练时以分类损失和基于角度的三元组损失来指导网络进行优化。我们基于原始的 TripletLoss (困难三元组损失)进行了改进,将优化目标从 L2 欧几里得空间更换成余弦空间,并加入了 anchor 与 positive/negtive 之间的硬性距离约束,让训练与测试的目标更加接近,提升模型的泛化能力。详细的配置文件见 GeneralRecognitionV2_PPLCNetV2_base.yaml。
3.3.5 Data Augmentation
考虑到实际相机拍摄时目标主体可能出现一定的旋转而不一定能保持正立状态,因此在数据增强中加入了适当的 随机旋转增强,以提升模型在真实场景中的检索能力。
特征提取模型的数据集、训练、评估、推理等详细信息可以参考文档:PPLCNetV2_base_ShiTu。
4. 向量检索
向量检索技术在图像识别、图像检索中应用比较广泛。其主要目标是对于给定的查询向量,在已经建立好的向量库中进行特征向量的相似度或距离计算,返回候选向量的相似度排序结果。
在 PP-ShiTuV2 识别系统中,我们使用了 Faiss 向量检索开源库对此部分进行支持,其具有适配性好、安装方便、算法丰富、同时支持CPU与GPU的优点。
PP-ShiTuV2 系统中关于 Faiss 向量检索库的安装及使用可以参考文档:vector search。
更多细节请参考PP-ShiTuV2详细介绍。
5. PP-LCNetV2介绍
5.1 模型简介
骨干网络对计算机视觉下游任务的影响不言而喻,不仅对下游模型的性能影响很大,而且模型效率也极大地受此影响,但现有的大多骨干网络在真实应用中的效率并不理想,特别是缺乏针对 Intel CPU 平台所优化的骨干网络,我们测试了现有的主流轻量级模型,发现在 Intel CPU 平台上的效率并不理想,然而目前 Intel CPU 平台在工业界仍有大量使用场景,因此我们提出了 PP-LCNet 系列模型,PP-LCNetV2 是在 PP-LCNetV1 基础上所改进的。
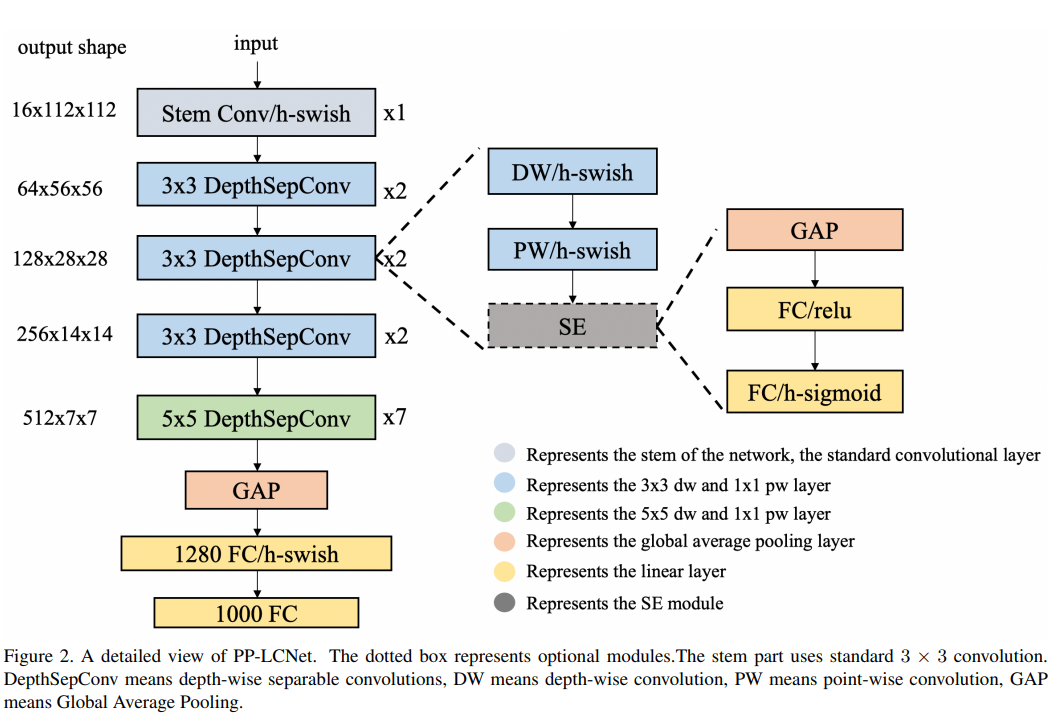
5.2 模型细节

PP-LCNetV2 模型的网络整体结构如上图所示。PP-LCNetV2 模型是在 PP-LCNetV1 的基础上优化而来,主要使用重参数化策略组合了不同大小卷积核的深度卷积,并优化了点卷积、Shortcut等。
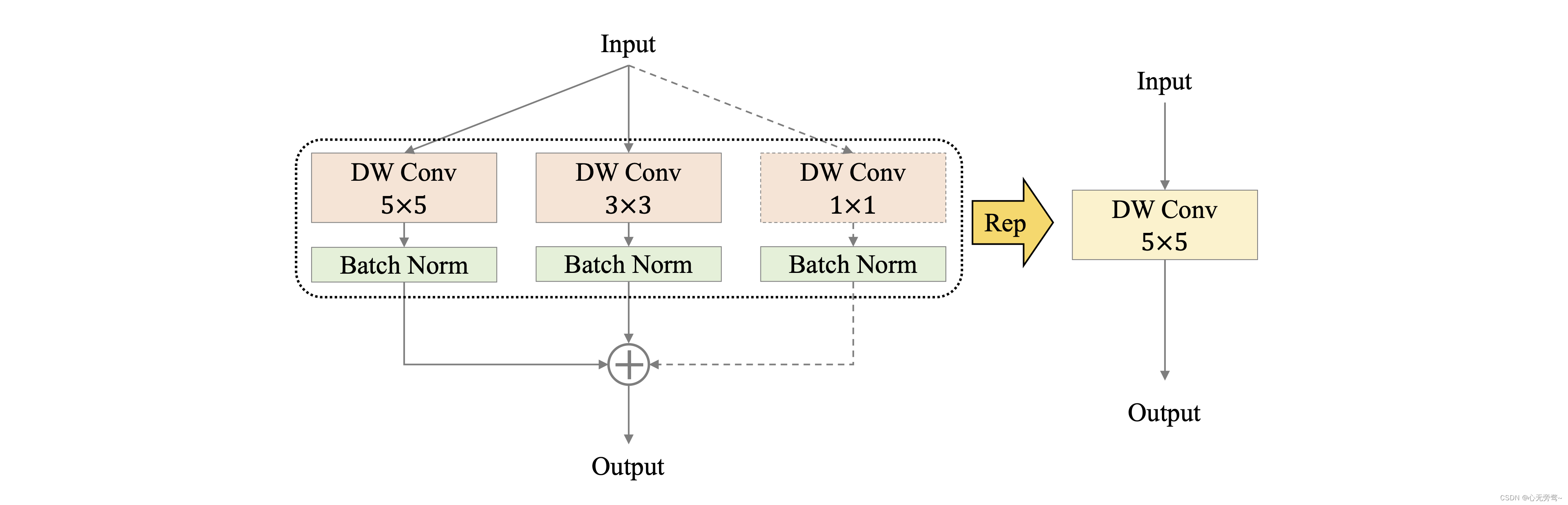
5.2.1 Rep 策略
卷积核的大小决定了卷积层感受野的大小,通过组合使用不同大小的卷积核,能够获取不同尺度的特征,因此 PPLCNetV2 在 Stage4、Stage5 中,在同一层组合使用 kernel size 分别为 5、3、1 的 DW 卷积,同时为了避免对模型效率的影响,使用重参数化(Re parameterization,Rep)策略对同层的 DW 卷积进行融合,如下图所示。
5.2.2 PW 卷积
深度可分离卷积通常由一层 DW 卷积和一层 PW 卷积组成,用以替换标准卷积,为了使深度可分离卷积具有更强的拟合能力,我们尝试使用两层 PW 卷积,同时为了控制模型效率不受影响,两层 PW 卷积设置为:第一个在通道维度对特征图压缩,第二个再通过放大还原特征图通道,如下图所示。通过实验发现,该策略能够显著提高模型性能,同时为了平衡对模型效率带来的影响,PPLCNetV2 仅在 Stage4 中使用了该策略。

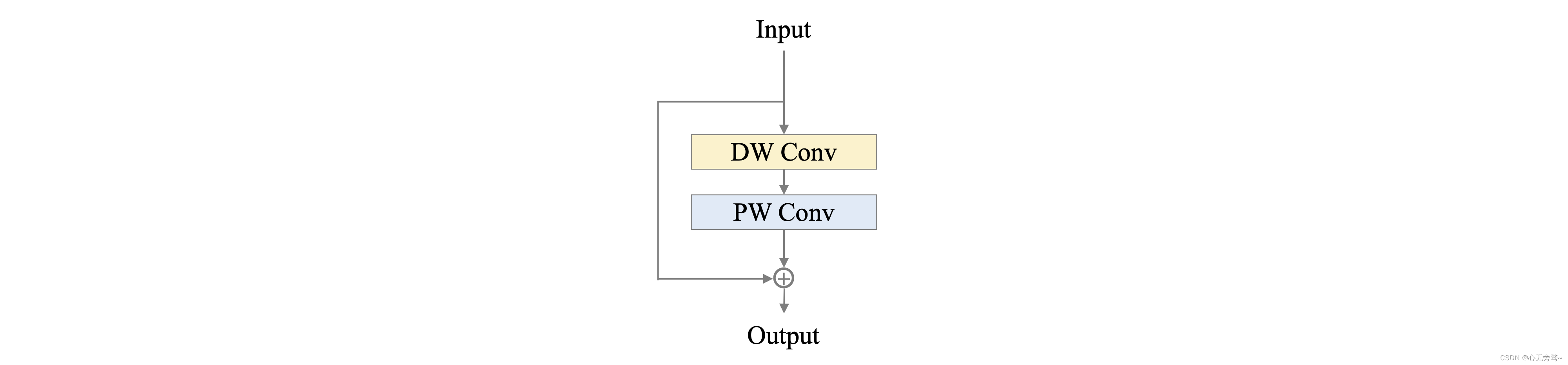
5.2.3 Shortcut
残差结构(residual)自提出以来,被诸多模型广泛使用,但在轻量级卷积神经网络中,由于残差结构所带来的元素级(element-wise)加法操作,会对模型的速度造成影响,我们在 PP-LCNetV2 中,以 Stage 为单位实验了残差结构对模型的影响,发现残差结构的使用并非一定会带来性能的提高,因此 PPLCNetV2 仅在最后一个 Stage 中的使用了残差结构:在 Block 中增加 Shortcut,如下图所示。
5.2.4 激活函数
在目前的轻量级卷积神经网络中,ReLU、Hard-Swish 激活函数最为常用,虽然在模型性能方面,Hard-Swish 通常更为优秀,然而我们发现部分推理平台对于 Hard-Swish 激活函数的效率优化并不理想,因此为了兼顾通用性,PP-LCNetV2 默认使用了 ReLU 激活函数,并且我们测试发现,ReLU 激活函数对于较大模型的性能影响较小。
5.2.5 SE 模块
虽然 SE 模块能够显著提高模型性能,但其对模型速度的影响同样不可忽视,在 PP-LCNetV1 中,我们发现在模型中后部使用 SE 模块能够获得最大化的收益。在 PP-LCNetV2 的优化过程中,我们以 Stage 为单位对 SE 模块的位置做了进一步实验,并发现在 Stage4 中使用能够取得更好的平衡。
更多详细内容请参考PP-LCNetV2
项目实践可参考以下:
- 基于PP-ShiTuV2的珍惜动物识别系统
- 基于PP-ShiTu图像识别系统的商品识别