论文: PP-OCR: A Practical Ultra Lightweight OCR System
Github:https://github.com/PaddlePaddle/PaddleOCR
百度开源的ocr检测+识别系统,称为PP-OCR。PP-OCR的中文字符识别模型仅3.5M,支持识别6622个中文字符。英文字符识别模型2.8M,支持识别63个英文字符。并且PP-OCR还支持识别法语,韩语,日语,德语等多国语言。
整体流程:

首先输入待检测图片,然后进行文本行的检测。对检测出来的每一个文本行进行方向检测。对进行方向矫正后的文本行进行文本识别,得到最终的结果。
文本检测:
文本检测使用了 Differentiable Binarization (DB)算法,模型大小仅仅1.4M。

整个网络结构的基本思想还是基于特征融合FPN的思想。红色的框,表示模型的主干网络结构,使用了 MobileNetV3 large x0.5。灰色的框表示头部预测分支。使用该方法可以实现横,纵,曲形,文本的检测。
主要使用的核心技术,
Light Backbone:

基于MobileNetV3拥有比MobileNetV1,MobileNetV2, ShuffleNetV2 在同等参数量下更好的精度,同时基于速度的考虑,使用了MobileNetV3 large x0.5网络结构。
Light Head:
这里基于FPN思想,使用了轻量化的头部预测分支。在FPN特征融合这一步,一般使用1*1的卷积实现将通道数对齐。实验证明,当内部通道数从256变为96,模型大小将会从7M变为4.1M,但是准确性下降很少。
Remove SE:

squeeze-and-excitation模块在SENet中提出,本质是一种通道attention的机制,取得了不错的效果。
但是,当输入图片分辨率较大的时候,比如640*640,这时SE模块的效果带来的精度提升就比较有限,反而造成了较大的推理时间开销。
因此,这里去掉了SE模块。
Cosine Learning Rate Decay:

cos形式的学习策略,可以使得训练得到更佳的训练模型。
Learning Rate Warm-up:
训练过程使用学习率热启动策略,可以使得训练结果更好。
FPGM Pruner:

使用FPGM方法进行减枝。
方向分类:
对于每一行的文本,使用了文本方向分类模型进行分类。
主要使用的核心技术,
Light Backbone :
使用轻量化的网络结构MobileNetV3 small x0.35。
Data Augmentation :
使用的数据增强包括,旋转变换,反射变换,运动模糊,高斯噪声,随机数据增强 RandAugmen。其中,RandAugmen取得了最好的效果。
Input Resolution :
在 PP-OCR中,输入图片的高度为48,宽度为192。
PACT Quantization :
量化包含离线量化(offline quantization ),在线量化(online quantization)两种方法。在线量化可以获得比离线量化更好的精度。这里使用了PACT在线量化方法,该方法基于 PaddleSlim实现。
原始的PACT量化方法,
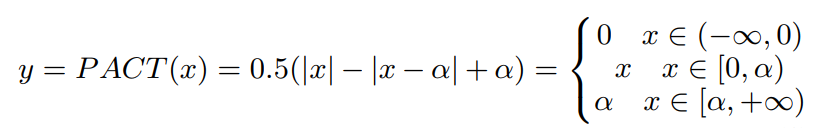
改进后的PACT量化,
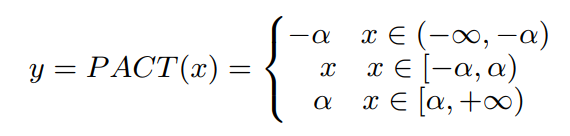
文本识别:

文本识别采用了CRNN这种基于ctc解码的方法。
主要使用的核心技术,
Light Backbone:
这里使用了轻量化网络结构 MobileNetV3 small x0.5。
Data Augmentation:

基于TIA方法的数据增强。
Cosine Learning Rate Decay:
cos形式的学习策略,可以使得训练得到更佳的训练模型。
Feature Map Resolution :
CRNN输入图片的高度为32,宽度为320。
Regularization Parameters:
这里使用了权值衰减 weight decay来防止过拟合。使用了L2正则化 L2 regularization使得模型学习的参数都更加接近于0。
Learning Rate Warm-up:
训练过程使用学习率热启动策略,可以使得训练结果更好。
Light Head:
轻量化的头部结构,这里将CRNN的全连接层的特征大小设置为48。
Pre-trained Model :
使用 ImageNet预训练模型,可以使得模型的精度更高。
PACT Quantization:
除去CRNN模型中的LSTM模块,其他部门都进行PACT量化。
实验结果:

模型对比:
| 模型介绍 | 模型名字 | 推荐场景 | 检测模型 | 方向模型 | 识别模型 | gpu允许速度(2080ti) | gpu允许显存 |
| Chinese and English ultra-lightweight OCR model (9.4M) | ch_ppocr_mobile_v2.0_xx | Mobile & server | 3.1M | 1.4M | 5.0M | 70ms | 10G |
| Chinese and English general OCR model (143.4M) | ch_ppocr_server_v2.0_xx | Server | 48M | 1.4M | 108M | 130ms | 8.4G |
检测模型,修改ppocr/data/imaug/operators.py,保证对输入图片进行resize 操作,保证输入网络图片的最长边不超过960像素,从而保证显存够用。否则遇到大图片可能32G显存都不够。
class DetResizeForTest(object):def __init__(self, **kwargs):super(DetResizeForTest, self).__init__()self.resize_type = 0if 'image_shape' in kwargs:self.image_shape = kwargs['image_shape']self.resize_type = 1elif 'limit_side_len' in kwargs:self.limit_side_len = kwargs['limit_side_len']self.limit_type = kwargs.get('limit_type', 'min')elif 'resize_long' in kwargs:self.resize_type = 2self.resize_long = kwargs.get('resize_long', 960)else:#self.limit_side_len = 736#self.limit_type = 'min'self.limit_side_len = 960self.limit_type = 'max'方向分类模型,即使按照默认设置"cls_batch_num",30个batch,所占用的显存也非常少,也就增加100M显存的样子。
识别模型,1个batch 和30batch的显存占用是有很大区别的,大概4个G的差别。所以可以根据显卡显存大小,合理设置"rec_batch_num".
经过测试,最小的情况下,大概需要2个G(3个G以内稳妥),才可以跑起来整个流程。
安装:
python3 -m pip install paddlepaddle-gpu==2.0.0 -i https://mirror.baidu.com/pypi/simple
pip3 install -r requirements.txt
实际测试:
import os
import cv2
import numpy as np
from paddleocr import PaddleOCR
# Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换
# 参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。def draw_ocr(img, boxes, txts, scores):import randomfrom PIL import Imagefrom PIL import ImageFont,ImageDrawbg = np.ones_like(img)*255fg = np.zeros_like(img)img_PIL_bg = Image.fromarray(cv2.cvtColor(bg,cv2.COLOR_BGR2RGB))img_PIL_fg = Image.fromarray(cv2.cvtColor(fg,cv2.COLOR_BGR2RGB))font = ImageFont.truetype('StyleText/fonts/ch_standard.ttf',10)fillColor = (0,0,0)#if not isinstance(chinese,unicode):#chinese = chinese.decode('utf-8')draw_bg = ImageDraw.Draw(img_PIL_bg)draw_fg = ImageDraw.Draw(img_PIL_fg)for box, txt , score in zip(boxes, txts, scores):tuple_polygon = (box[0][0], box[0][1], box[1][0],box[1][1], box[2][0],box[2][1], box[3][0],box[3][1])color = (random.randint(0,255),random.randint(0,255),random.randint(0,255))draw_bg.polygon(tuple_polygon, fill = color)draw_fg.polygon(tuple_polygon, fill = color)draw_bg.text(box[0] , " ".join([txt,str(float(score))]),font=font,fill=fillColor)img_bg = cv2.cvtColor(np.asarray(img_PIL_bg),cv2.COLOR_RGB2BGR)img_fg = cv2.cvtColor(np.asarray(img_PIL_fg),cv2.COLOR_RGB2BGR)return np.hstack([cv2.addWeighted(img, 0.5, img_fg, 0.5, gamma=0), img_bg])def test_one_image():# smallocr = PaddleOCR(det_model_dir="models/ultra-lightweight_2.0/det/",rec_model_dir="models/ultra-lightweight_2.0/rec/ch/",rec_char_dict_path="ppocr/utils/ppocr_keys_v1.txt",cls_model_dir="models/ultra-lightweight_2.0/cls/",use_angle_cls=True,lang="ch") # need to run only once to download and load model into memory# bigocr = PaddleOCR(det_model_dir="models/general_2.0/det/",rec_model_dir="models/general_2.0/rec/ch/",rec_char_dict_path="ppocr/utils/ppocr_keys_v1.txt",cls_model_dir="models/general_2.0/cls/",use_angle_cls=True,lang="ch") # need to run only once to download and load model into memoryimg_path = 'doc/imgs/11.jpg'img = cv2.imread(img_path)result = ocr.ocr(img, cls=True)boxes = [line[0] for line in result]txts = [line[1][0] for line in result]scores = [line[1][1] for line in result]for box, txt , score in zip(boxes, txts, scores):print(box, txt, score)draw_out = draw_ocr(img, boxes, txts, scores)cv2.imwrite(img_path.split("/")[-1],draw_out)def test_images():# small"""ocr = PaddleOCR(det_model_dir="models/ultra-lightweight_2.0/det/",rec_model_dir="models/ultra-lightweight_2.0/rec/ch/",rec_char_dict_path="ppocr/utils/ppocr_keys_v1.txt",cls_model_dir="models/ultra-lightweight_2.0/cls/",use_angle_cls=True,lang="ch") # need to run only once to download and load model into memory"""# bigocr = PaddleOCR(det_model_dir="models/general_2.0/det/",rec_model_dir="models/general_2.0/rec/ch/",rec_char_dict_path="ppocr/utils/ppocr_keys_v1.txt",cls_model_dir="models/general_2.0/cls/",use_angle_cls=True,lang="ch") # need to run only once to download and load model into memorydata_dir= "test_images/"out_dir = "out_images/"for name in os.listdir(data_dir):print(name)img_path = os.path.join(data_dir, name)img = cv2.imread(img_path)result = ocr.ocr(img, cls=True)boxes = [line[0] for line in result]txts = [line[1][0] for line in result]scores = [line[1][1] for line in result]for box, txt , score in zip(boxes, txts, scores):print(box, txt, score)draw_out = draw_ocr(img, boxes, txts, scores)cv2.imwrite(os.path.join(out_dir, name),draw_out)if __name__=="__main__":#test_one_image()test_images()

总结:
(1)开源的非常不错的ocr代码,精度挺高。