PP-LCNet: A Lightweight CPU Convolutional Neural Network
🔗 PDF Link 🍺 Github Code
Section 1 介绍
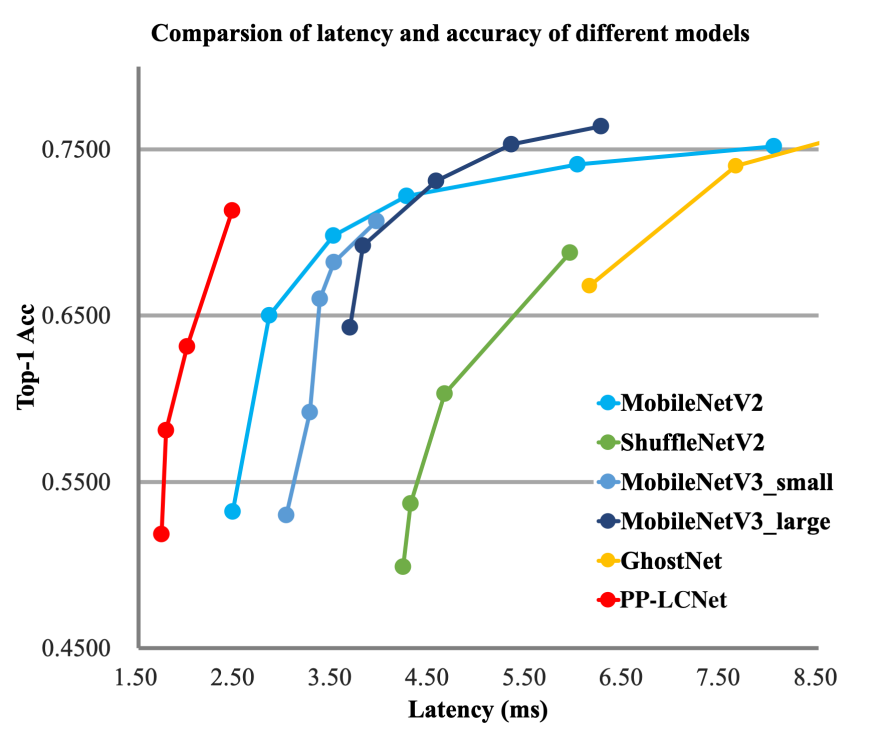
随着模型参数和FLOPs的加大,模型越来越难以在基于ARM架构的移动端设备或者x86架构的CPU上取得较快的推理速度。虽然有许多优秀的移动端网络被设计出来,但是由于MKLDNN的限制,网络的推理加速效果并不理想。本文重新考虑了轻量级模型的构成,尤其是我们考虑了三个基础问题:
- 在不增加网络延时的前提下,如何增强特征的表征能力。
- 在CPU上提升模型精度的关键因素是什么。
- 如何有效地整合不同地策略来在CPU上设计轻量级模型。
我们的主要贡献在于总结了一系列在不提升预测耗时的前提下提升精度的方法从而在速度和精度上取得一个平衡。基于此,我们总结出了了一些设计轻量化CNN的思路并提供了一些想法帮助其他相关研究者来设计CPU模型。
Section 2 相关工作
当前的方向主要有两个,一个是基于手工设计CNN结构另一个是NAS。
2.1 Manually-designed Architecture.
VGG展示了简单但是有效的方法来构建神网络。GooLeNet设计了Inception模块,能使得模型更轻量化。MobileNetV1使用了depthwise以及pointwaise卷积代替了标准的卷积,这显著减少了FLOPs并提升了性能。ShuffleNetV1/V2通过通道随机打乱来增加信息交换,从而减少了无意义的网络结构开销(❓)。GhostNet作者提出了Ghost模块,利用该模块可以利用更少的参数生成更丰富的特征图。
2.2 Manually-designed Architecture.
随着GPU结构、算力的升级,主攻方向逐渐开始向NAS发展,大量的NAS生成的网络尝试使用和MobileNetV2一样的结构空间,生成了例如EfficientNet,MobileNetV3,FBNet,DNANet,OFANet等网络结构。MixNet提出在一层中混合不同卷积核大小的深度卷积。NAS生成的模型也极大程度上依赖着手工结构,例如BottleNeck block,Inverted-block等。我们的工作可以减少搜索空间,从而生成更好更快的模型。
Section 3 方法
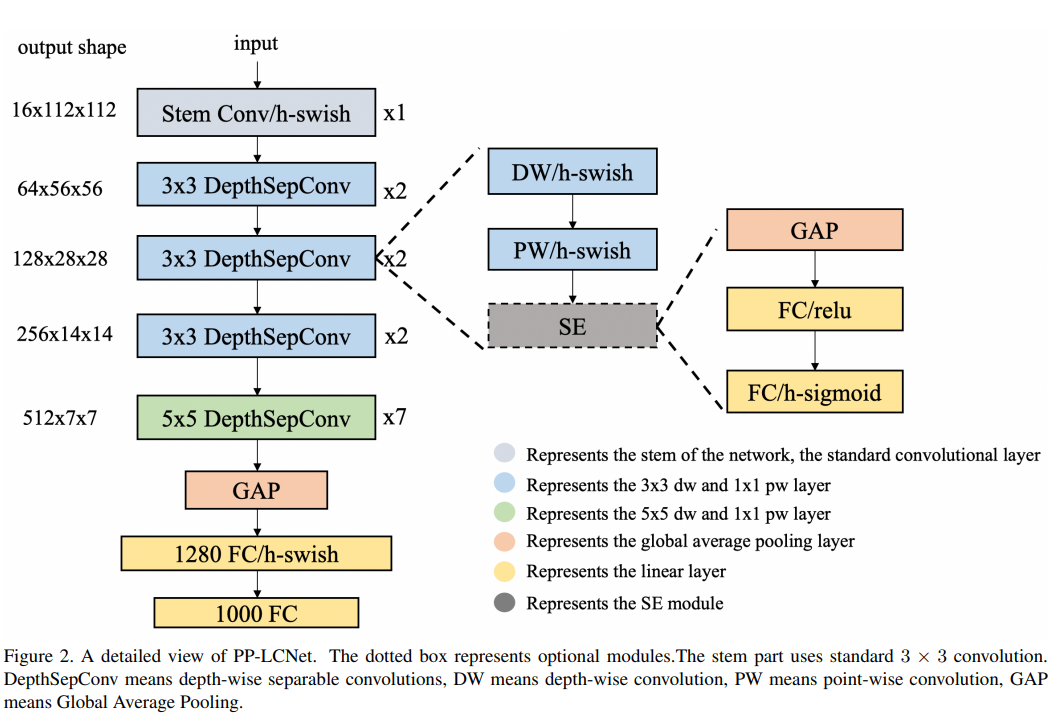
尽管有许多轻量化模型在基于ARM结构的CPU上有着很快的推理速度,但是很少有模型考虑到在Intel CPU上能获得较快速度模型结构设计,尤其是当使用了MKLDNN等加速库的前提。文章在这里总结了而一些方法,将会在后文进行展示。我们使用了MobileNetV1提出的DepthSepConv作为我们的基础block。这个模块没有跳跃连接,因此不需要一些类似concat和elementwise-add之类的操作,上面这类操作会显著性的降低模型的推理速度。更进一步,这个模块已经在Intel CPU上的加速库深度优化过了,因此该模块对比其他类似inverted-block和shuffle-block有着显著的优势。文章通过堆积这个基础模块来搭建了一个类似MobileNetV1的BaseNet。然后而文章通过整合一些其他现有的策略来构建了PP-LCNet。
3.1 Better activation function.
众所周知,激活函数的质量决定了网路的性能。自从激活函数从Sigmoid变换到如今的ReLU,网络的性能得到了显著的提升。近些年来,越来越多的优越的激活激活函数开始超越ReLU。EfficientNet的Swish激活函数展示了更好的更好的性能,MobileNetV3的作者更新到了H-Swish从而避免了指数操作(减少计算量)。因此文章尝试替换了ReLU为H-Swish,从而获得了极大的性能提升,尽管推理速度并没有太大的改变。
3.2 SE modules at appropriate positions
SE模块自从提出就被许多网络模型采纳使用。这个模块能很好的为特征通道进行加权,从而获得更丰富的特征,同时SE模块的加速版本也被很多轻量化模型采纳,例如MobileNetV3。但是,在Intel CPU上使用SE模块会减慢推理时间。因此,我们不能在整个网络上使用该模块。事实上,文章做了许多实验发现SE模块在网络结构的末尾能取得最好的效果。因此,只在最后一层加SE模块能取得更好的性能-速度平衡。于MobileNetV3一样,最后两层的SE模块的激活函数分别使用ReLu和H-Swish。
3.3 Larger convolution kernels
卷积核的尺寸通常来说会影响最终的模型性能。MixNet的作者分析了不同尺寸的卷积核对网络模型的性能的影响,最终决定在同一层中使用混合尺寸的卷积核。但是这种混合会减慢推理速度,因此依旧尝试在一层中使用单一尺寸的卷积核,并确保卷积核的尺寸稍大从而满足延时和精度需要。文章通过实验发现类似于SE模块的放置位置,在模型的尾部利用5x5卷积来替代原来的3x3卷积能获得几乎一致的模型性能。Larger dimensional 1 × 1 conv layer after GAP
3.4 Larger dimensional 1 × 1 conv layer after GAP
在PP-LCNet中,GAP输出的维度通常来说是很小,直接将这个数据送到分类层,将会非常多的特征组合。为了给模型提供一个更强的你和能力,文章在GAP的输出后面增加了一个1280维的1x1卷积(类似于全连接层)。
有了以上四个改进,文章提出的模型能够在ImageNet-1k数据集上取得很好的性能,如表3所示。
表3. 与其他SOTA的轻量化模型在分类任务上精度对比,延迟测试使用的是Intel Xeon Gold 6148 处理器(batch size 1)并开启了 MKLDNN,使用10线程.
| Model | Params (M) | FLOPs (M) | Top-1 Acc.(%) | Top-5 Acc.(%) | Latency (ms) |
|---|---|---|---|---|---|
| MobileNetV2-0.25x | 1.5 | 34 | 53.21 | 76.52 | 2.47 |
| MobileNetV3-small-0.35x | 1.7 | 15 | 53.03 | 76.37 | 3.02 |
| ShuffleNetV2-0.33x | 0.6 | 24 | 53.73 | 77.05 | 4.30 |
| PP-LCNet-0.25x | 1.5 | 18 | 51.86 | 75.65 | 1.74 |
| MobileNetV2-0.5x | 2 | 99 | 65.03 | 85.72 | 2.85 |
| MobileNetV3-large-0.35x | 2.1 | 41 | 64.32 | 85.46 | 3.68 |
| ShuffleNetV2-0.5x | 1.4 | 43 | 60.32 | 82.26 | 4.65 |
| PP-LCNet-0.5x | 1.9 | 47 | 63.14 | 84.66 | 2.05 |
| MobileNetV1-1x | 4.3 | 578 | 70.99 | 89.68 | 3.38 |
| MobileNetV2-1x | 3.5 | 327 | 72.15 | 90.65 | 4.26 |
| MobileNetV3-small-1.25x | 3.6 | 100 | 70.67 | 89.51 | 3.95 |
| ShuffleNetV2-1.5x | 3.5 | 301 | 71.63 | 90.15 | - |
| PP-LCNet-1x | 3 | 161 | 71.32 | 90.03 | 2.46 |
Section 4 实验
4.1 Implementation Details
为了公平对比,我们用PaddlePaddle重新实现了MobileNetV1-V3,ShuffleNetV2,PicoDet以及DeeplabV3+。使用4块V100 GPUs上训练并在 Intel Xeon Glod 6148开启MKLDNN使用10线程进行单batchsize的情况下进行测试。
4.2 Image Classification
对于图像分类任务,我们在ImageNet-1k上进行训练,包含了128万图像的训练数据和5万张验证数据,包含了1000个类别。使用了SGD,权重衰减3e-5,对于大模型设置了4e-5,动量设置为0.9,batchsize2048,学习率根据cosine策略调整,一共训练了360个epochs并使用了5个epochs的线性预热,初始学习率为0.8。在训练阶段,每一张图像数据都被随即裁剪到了224x224,并设置了随机的水平翻转,在验证阶段,对所有的图像依照短边自适应resize到256,然后使用了中心裁剪。表2给出了PP-LCNet的不同变体的准确率和推理时间。特别注意的是,当使用SSLD进行知识蒸馏后,模型的精度有着显著的提升,上面的表3给出了详细的结果。
表2. 不同的PP-LCNet的尺度,*表示使用了SSLD蒸馏进行训练,延迟测试使用的是Intel Xeon Gold 6148 处理器(batch size 1)并开启了 MKLDNN,使用10线程.
| Model | Params (M) | FLOPs (M) | Top-1 Acc.(%) | Top-5 Acc.(%) | Latency (ms) |
|---|---|---|---|---|---|
| PP-LCNet0.25x | 1.5 | 18 | 51.86 | 75.65 | 1.74 |
| PP-LCNet-0.35x | 1.6 | 29 | 58.09 | 80.83 | 1.92 |
| PP-LCNet-0.5x | 1.9 | 47 | 63.14 | 84.66 | 2.05 |
| PP-LCNet-0.75x | 2.4 | 99 | 68.18 | 88.3 | 2.29 |
| PP-LCNet-1x | 3 | 161 | 71.32 | 90.03 | 2.46 |
| PP-LCNet-1.5x | 4.5 | 342 | 73.71 | 91.53 | 3.19 |
| PP-LCNet-2x | 6.5 | 590 | 75.18 | 92.27 | 4.27 |
| PP-LCNet-2.5x | 9 | 906 | 76.6 | 93 | 5.39 |
| PP-LCNet-0.5x* | 1.9 | 47 | 66.1 | 86.46 | 2.05 |
| PP-LCNet-1x* | 3 | 161 | 74.39 | 92.09 | 2.46 |
| PP-LCNet-2.5x* | 9 | 906 | 80.82 | 95.33 | 5.39 |
4.3 Object Detection
对于目标检测任务,所有的模型都在COCO-2017数据集上进行训练。一共80类,11.8万张图像数据,验证集有5000张数据。评估方式在单尺度上使用COCO AP策略。文章使用了轻量化的PicoDet作为基线模型。表4给出了使用PP-LCNet和MobileNetV3作为骨架的检测模型的检测效果。模型使用了SGD训练了14.6万次迭代,在4卡上分布式训练的batchsize为224,学习率的衰减使用了cosine从0.3开始,一共训练了280个epochs。权重衰减为1e-4,动量为0.9。让人形象深刻的是PP-LCNet对比MobileNetV3在COCO上显著提升了mAP性能以及推理速度。
表4. 检测模型结果
| Method | Backbone | mIoU (%) | Latency (ms) |
|---|---|---|---|
| PicoDet | MobileNetV3-large-0.5x | 55.42 | 135 |
| PP-LCNet-0.5x | 58.36 | 82 | |
| PicoDet | MobileNetV3-large-0.75x[20] | 64.53 | 151 |
| PP-LCNet-1x | 66.03 | 96 |
4.4 Semantic Segmentation
在CityCaps数据上进行验证,一共包含了5000张高质量的标签数据,使用的基准模型为DeepLabV3+,并设置了输出的尺度为32。数据增强策略使用了随机水平翻转,随机缩放(缩放系数为{0.5, 0.75, 1.0, 1.25, 1.5, 1.75, 2.0})和随机裁剪(裁剪分辨率为1024x512)。使用SGD优化器,初始学习率为0.01,动量为0.9,权重衰减为4e-5。使用了多项式学习率衰减策略,衰减系数为0.9。一共训练了8万次迭代,batchsize在4卡上分布式batchsize为32。
文章同样对比了MobileNetV3作为骨架时候的情况,详见表5。
表5. 语义分割模型结果
| Method | Backbone | mIoU (%) | Latency (ms) |
|---|---|---|---|
| Deeplabv3+ | MobileNetV3-large-0.5x | 55.42 | 135 |
| PP-LCNet-0.5x | 58.36 | 82 | |
| MobileNetV3-large-0.75x | 64.53 | 151 | |
| PP-LCNet-1x | 66.03 | 96 |
4.5 Ablation Study
The impact of SE module[26] in different positions
不同位置的SE模块对模型性能的影响,详见表6。
表6
| Network | SELocation | Top-1Acc(%) | Latency(ms) |
|---|---|---|---|
| PP-LCNet-0.5x | 1100000000000 | 61.73 | 2.06 |
| 0000001100000 | 62.17 | 2.03 | |
| 0000000000011 | 63.14 | 2.05 | |
| 1111111111111 | 64.27 | 3.8 |
The impact of large-kernel in different locations.
大卷积核在不同位置对性能的影响,详见表7。
表7
| Network | 大卷积核位置 | Top-1Acc (%) | Latency (ms) |
|---|---|---|---|
| PP-LCNet-0.5x | 1111111111111 | 63.22 | 2.08 |
| 1111111000000 | 62.7 | 2.07 | |
| 0000001111111 | 63.14 | 2.05 |
The impact of different techniques.
丢掉一些策略对模型性能的延迟造成的影响,见表8。
表8
| Activation | SEblock | large-kernel | last-1x1conv | Top-1Acc(%) | Latency(ms) |
|---|---|---|---|---|---|
| √ | ╳ | ╳ | ╳ | 61.93 | 1.94 |
| ╳ | √ | ╳ | ╳ | 62.51 | 1.87 |
| ╳ | ╳ | √ | ╳ | 62.44 | 2.01 |
| ╳ | ╳ | ╳ | √ | 59.91 | 1.85 |
| ╳ | ╳ | ╳ | ╳ | 63.14 | 2.05 |
不同策略对模型性能和延迟造成的影响,见表9。
表9
| Strategy | Top-1Acc.(%) | Latency(ms) |
|---|---|---|
| BaseNet | 55.58 | 1.61 |
| +h-swish | 58.18 | 1.66 |
| +large-kernel | 59.09 | 1.7 |
| +SE | 59.91 | 1.85 |
| +last-1x1convw/odropout | 62.5 | 2.05 |
| +last-1x1convw/dropout | 63.14 | 2.05 |
Section 5 总结和未来的工作
模型很好,后面会用这个经验去做一些NAS。