说明:
1.准备三台虚拟机,参考:CentOS7集群环境搭建(以3台为例)
2.配置虚拟机间免密登陆:参考:CentOS7集群配置免密登录
3.虚拟机分别安装jdk:参考:CentOS7集群安装JDK1.8
4.hadoop安装包下载,下载地址
准备开始搭建hadoop集群,以下操作在第一台机器node1执行:
1.上传并解压hadoop安装包
1.1上传安装包到/develop/software
mkdir -p /develop/software
mkdir -p /develop/server
cd /develop/software
rz
1.2解压安装包到/develop/server
tar -zxvf hadoop-2.7.5.tar.gz -C /develop/server/
1.3切换到解压目录,查看解压后的文件
cd /develop/server/hadoop-2.7.5
ll
2.修改hadoop配置文件
2.1切换到hadoop的etc/hadopp目录,修改hadoop-env.sh
cd /develop/server/hadoop-2.7.5/etc/hadoop/
ll
vim hadoop-env.sh
2.2配置hadoop-env.sh文件,修改jdk路径
export JAVA_HOME=/develop/server/jdk1.8.0_241
2.3配置core-site.xml(hadoop的核心配置文件)在<configuration></configuration>中配置以下内容
<!-- 设置Hadoop的文件系统 -->
<property><name>fs.defaultFS</name><value>hdfs://node1:8020</value></property>
<!-- 配置Hadoop数据存储目录 --><property><name>hadoop.tmp.dir</name><value>/develop/server/hadoop-2.7.5/data/tempdata</value>
</property>
<!-- 缓冲区大小 --><property><name>io.file.buffer.size</name><value>4096</value></property>
<!-- hdfs的垃圾桶机制,单位分钟 --><property><name>fs.trash.interval</name><value>10080</value></property>
2.4配置hdfs-site.xml(hdfs的核心配置文件),在<configuration></configuration>中配置以下内容,注意secondaryNameNode和Namenode不要放在同一台机器上
<!-- SecondaryNameNode的主机和端口 -->
<property><name>dfs.namenode.secondary.http-address</name><value>node2:50090</value>
</property>
<!-- namenode的页面访问地址和端口 -->
<property><name>dfs.namenode.http-address</name><value>node1:50070</value>
</property>
<!-- namenode元数据的存放位置 -->
<property><name>dfs.namenode.name.dir</name><value>file:///develop/server/hadoop-2.7.5/data/nndata</value>
</property>
<!-- 定义datanode数据存储的节点位置 -->
<property><name>dfs.datanode.data.dir</name><value>file:///develop/server/hadoop-2.7.5/data/dndata</value>
</property>
<!-- namenode的edits文件存放路径 -->
<property><name>dfs.namenode.edits.dir</name><value>file:///develop/server/hadoop-2.7.5/data/nn/edits</value>
</property>
<!-- 检查点目录 -->
<property><name>dfs.namenode.checkpoint.dir</name><value>file:///develop/server/hadoop-2.7.5/data/snn/name</value>
</property><property><name>dfs.namenode.checkpoint.edits.dir</name><value>file:///develop/server/hadoop-2.7.5/data/dfs/snn/edits</value>
</property>
<!-- 文件切片的副本个数-->
<property><name>dfs.replication</name><value>3</value>
</property>
<!-- HDFS的文件权限-->
<property><name>dfs.permissions</name><value>true</value>
</property>
<!-- 设置一个文件切片的大小:128M-->
<property><name>dfs.blocksize</name><value>134217728</value>
</property>

2.5复制mapred-site.xml.template,并更改名称为mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
ll
2.6配置mapred-site.xml(MapReduce的核心配置文件),在<configuration></configuration>中配置以下内容
<!-- 分布式计算使用的框架 -->
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
<!-- 开启MapReduce小任务模式 -->
<property><name>mapreduce.job.ubertask.enable</name><value>true</value>
</property>
<!-- 历史任务的主机和端口 -->
<property><name>mapreduce.jobhistory.address</name><value>node1:10020</value>
</property>
<!-- 网页访问历史任务的主机和端口 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value>
</property>
2.7配置mapred-env.sh,指定JAVA_HOME
export JAVA_HOME=/develop/server/jdk1.8.0_241
2.8配置yarn-site.xml(YARN的核心配置文件) ,在<configuration></configuration>中配置以下内容
<!-- yarn主节点的位置 -->
<property><name>yarn.resourcemanager.hostname</name><value>node1</value>
</property>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<!-- 开启日志聚合功能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<!-- 设置聚合日志在hdfs上的保存时间 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
<!-- 设置yarn集群的内存分配方案 -->
<property> <name>yarn.nodemanager.resource.memory-mb</name> <value>2048</value>
</property>
<property> <name>yarn.scheduler.minimum-allocation-mb</name><value>2048</value>
</property>
<property><name>yarn.nodemanager.vmem-pmem-ratio</name><value>2.1</value>
</property>
2.9配置slaves,slaves文件里面记录的是集群主机名,删除原有内容,配置以下内容
node1
node2
node3
3.创建数据存放目录
mkdir -p /develop/server/hadoop-2.7.5/data/tempdata
mkdir -p /develop/server/hadoop-2.7.5/data/nndata
mkdir -p /develop/server/hadoop-2.7.5/data/dndata
mkdir -p /develop/server/hadoop-2.7.5/data/nn/edits
mkdir -p /develop/server/hadoop-2.7.5/data/snn/name
mkdir -p /develop/server/hadoop-2.7.5/data/dfs/snn/edits4.文件分发
4.1将安装配置好的hadoop分发到另外两台机器
scp -r hadoop-2.7.5/ node2:$PWDscp -r hadoop-2.7.5/ node3:$PWD4.2在另外两台机器上分别查看分发后的文件
cd /develop/server/
ll

4.3分别在三台机器上配置hadoop环境变量
vim /etc/profile.d/my_env.sh# HADOOP_HOME
export HADOOP_HOME=/develop/server/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
4.4刷新环境变量
source /etc/profile
4.5另外两台机器同样配置环境变量
5.启动hadoop集群
5.1首次启动hdfs时需要格式化,在node1执行以下命令
hadoop namenode -format
5.2启动相关服务,三种启动方式
5.2.1单节点逐一启动,
5.2.1.1启动namenode,在node1执行以下命令
hadoop-daemon.sh start namenode
5.2.1.2三台机器分别启动datanode,在node1、node2、node3上,分别使用以下命令启动 datanode
hadoop-daemon.sh start datanode


5.2.1.3在node1启动resourcemanager
yarn-daemon.sh start resourcemanager
5.2.1.4在node1、node2、node3上使用以下命令启动YARN nodemanager
yarn-daemon.sh start nodemanager


5.2.1.5在node2上启动secondarynamenode
hadoop-daemon.sh start secondarynamenode
5.2.1.6在node1上启动historyserver
mr-jobhistory-daemon.sh start historyserver
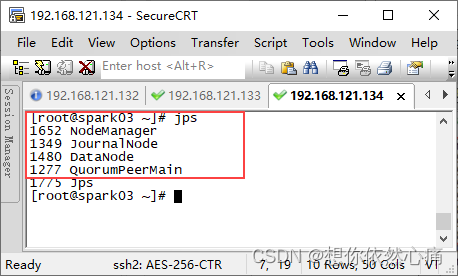
5.2.1.7查看服务启动情况,分别在三台机器执行jps命令



5.2.1.8关闭服务
如果要关闭服务只需将上面命令中的start改为stop即可
5.2.2使用hadoop自带脚本启动,以下命令在node1执行
5.2.2.1启动hdfs
start-dfs.sh
5.2.2.2启动yarn
start-yarn.sh
5.2.2.3启动历史任务服务
mr-jobhistory-daemon.sh start historyserver
5.2.2.3关闭服务
stop-dfs.shstop-yarn.shmr-jobhistory-daemon.sh stop historyserver

5.2.3一键启动脚本:hadoop集群启动脚本
6.访问集群UI页面
6.1 namenode集群页面
http://ip:50070/ 
6.2 yarn集群页面
http://ip:8088/cluster
6.3mapreduce历史任务页面
http://ip:19888/jobhistory
到此,hadoop集群搭建完毕