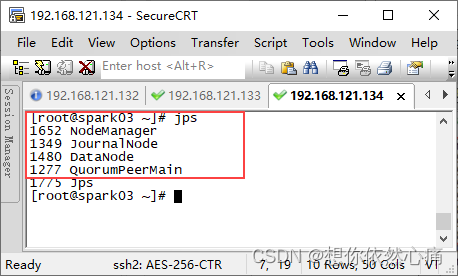
启动Hadoop集群
第一次启动前置工作
注意:首次启动 HDFS 时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的 HDFS 在物理上还是不存在的。(本质是对namenode进行初始化)
命令:hdfs namenode -format 或者 hadoop namenode -format
命令中的 - 已经修复为 英文输入法下的 -
关于hdfs的格式化:
首次启动需要进行格式化;
格式化本质是进行文件系统的初始化操作 创建一些自己所需要的文件;
格式化之后 集群启动成功 后续再也不要进行格式化;
格式化的操作在hdfs集群的主角色(namenode)所在机器上操作(我们设置的是node-1)。
注意:第一次格式化启动是会为集群产生一个标识,标识我们每一个节点的ID是多少,如果格式化之后,你再进行一次格式化,就会改变这个标识,导致节点的ID发生变化,导致集群启动失败。
![[外链图片转存失败(img-MCU6lU6N-1565707079239)(D:\学习笔记\hadoop\保存图片\安装Hadoop\格式化HDFS01.jpg)]](https://img-blog.csdnimg.cn/20190813223826113.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3h4eWR6eXI=,size_16,color_FFFFFF,t_70)
HDFS格式化失败解决方案
格式化的时候发现,之前设置的hddata文件夹没有创建,查询不大节点ID,然后懵了。
这时候想到的是格式化失败,因为之前是复制之前的脚本输入的,想了想,是不是脚本有问题,于是手动输入了一下,格式化成功了,对比之前的命令,发现 中文状态下的- 和英文状态下的- 不是一样的。心态爆炸…
启动Hadoop
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个集群。
单节点逐个启动
在主节点上使用以下命令启动 HDFS NameNode:
hadoop-daemon.sh start namenode
在每个从节点上使用以下命令启动 HDFS DataNode:
hadoop-daemon.sh start datanode
在主节点上使用以下命令启动 YARN ResourceManager:
yarn-daemon.sh start resourcemanager
在每个从节点上使用以下命令启动 YARN nodemanager:
yarn-daemon.sh start nodemanager
以上脚本位于Hadoop安装目录下的sbin目录下。如果想要停止某个节点上某个角色,只需要把命令中的 start 改为 stop 即可。
脚本一键启动
如果配置了 etc/hadoop/slaves 和 ssh 免密登录,则可以使用程序脚本启动所有 Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
首先进入Hadoop的安装目录下的sbin目录,我这边是:cd /export/server/hadoop-2.7.4/sbin/
里面有 .sh 结尾的文件(用于在Linux上启动集群),有.cmd结尾的文件(用于在window上启动集群)。
start-dfs.sh # 启动hdfs
sbin/start-yarn.sh # 启动YARN
stop-dfs.sh # 停止hdfs集群
stop-yarn.sh # 停止yarn集群
里面还有start-all.sh 和 stop-all.sh ,这两个可以直接启动或停止HDFS和YARN集群,但是这两个命令是过时了的,可能到了Hadoop的某个版本就不能使用了。
![[外链图片转存失败(img-MLSoEv1C-1565707079240)(D:\学习笔记\hadoop\保存图片\安装Hadoop\启动Hadoop集群.jpg)]](https://img-blog.csdnimg.cn/20190813223852338.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3h4eWR6eXI=,size_16,color_FFFFFF,t_70)
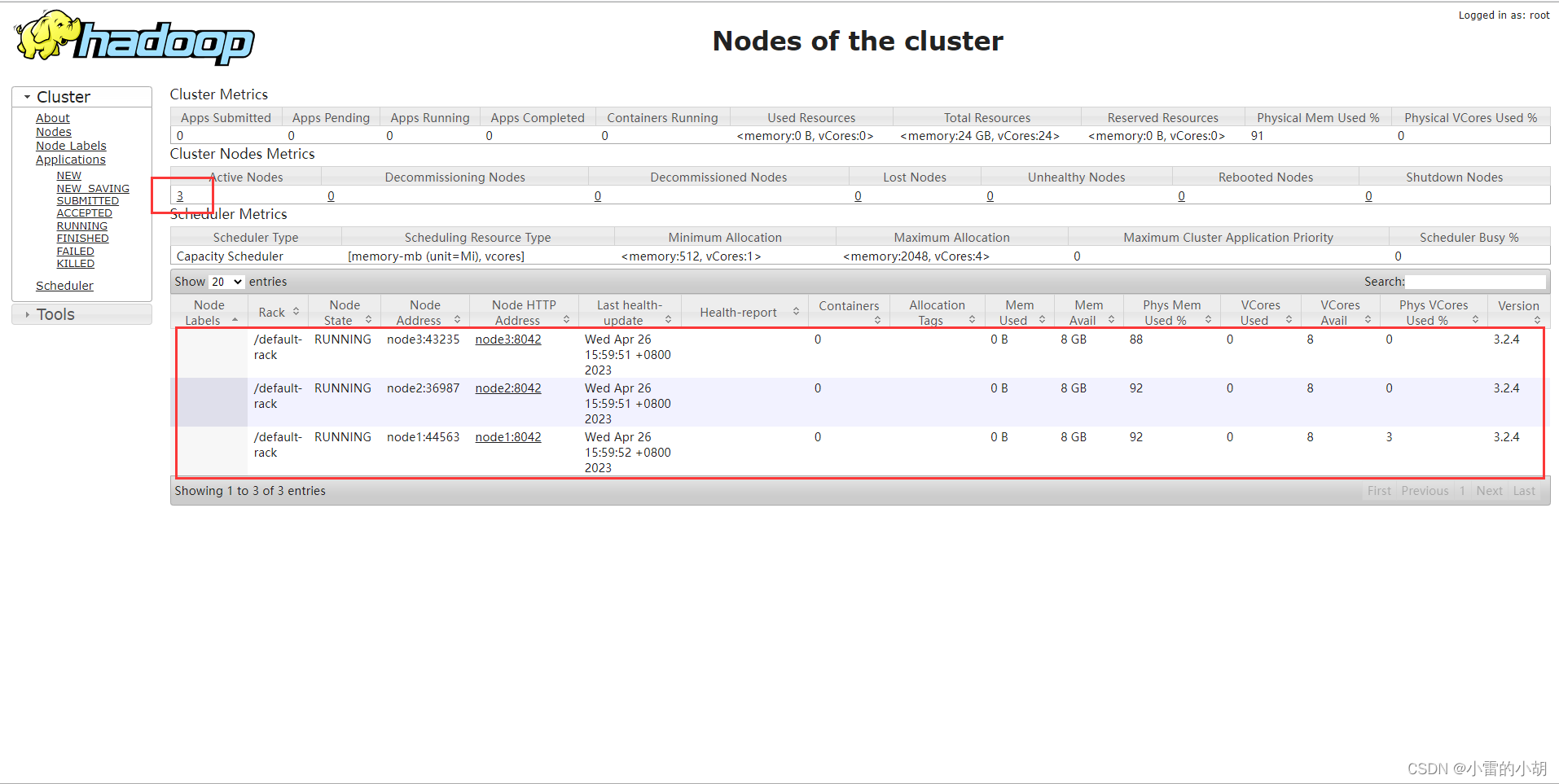
集群 web-ui
一旦 Hadoop 集群启动并运行,可以通过 web-ui 进行集群查看,如下所述:
NameNode http://nn_host:port/ 默认 50070.
ResourceManager http://rm_host:port/ 默认 8088.
这个需要我们在window上配置主机名IP映射,之前貌似有介绍配置。
然后直接在电脑的浏览器上输入:node-1:50070 即可看到这个界面。
![[外链图片转存失败(img-sXZzBKSm-1565707079262)(D:\学习笔记\hadoop\保存图片\安装Hadoop\HadoopUI界面01.jpg)]](https://img-blog.csdnimg.cn/20190813223909807.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3h4eWR6eXI=,size_16,color_FFFFFF,t_70)
![[外链图片转存失败(img-141H4IxK-1565707079263)(D:\学习笔记\hadoop\保存图片\安装Hadoop\HadoopUI界面02.jpg)]](https://img-blog.csdnimg.cn/20190813223924916.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3h4eWR6eXI=,size_16,color_FFFFFF,t_70)
Non DFS Used = 配置的容量 - 剩余容量 - DFS使用容量
而配置容量 = 总容量 - 预留空间(总容量为磁盘的总大小,预留空间为默认的5%)
所以,Non DFS used=(总容量-预留空间)- 剩余容量 - DFS使用容量
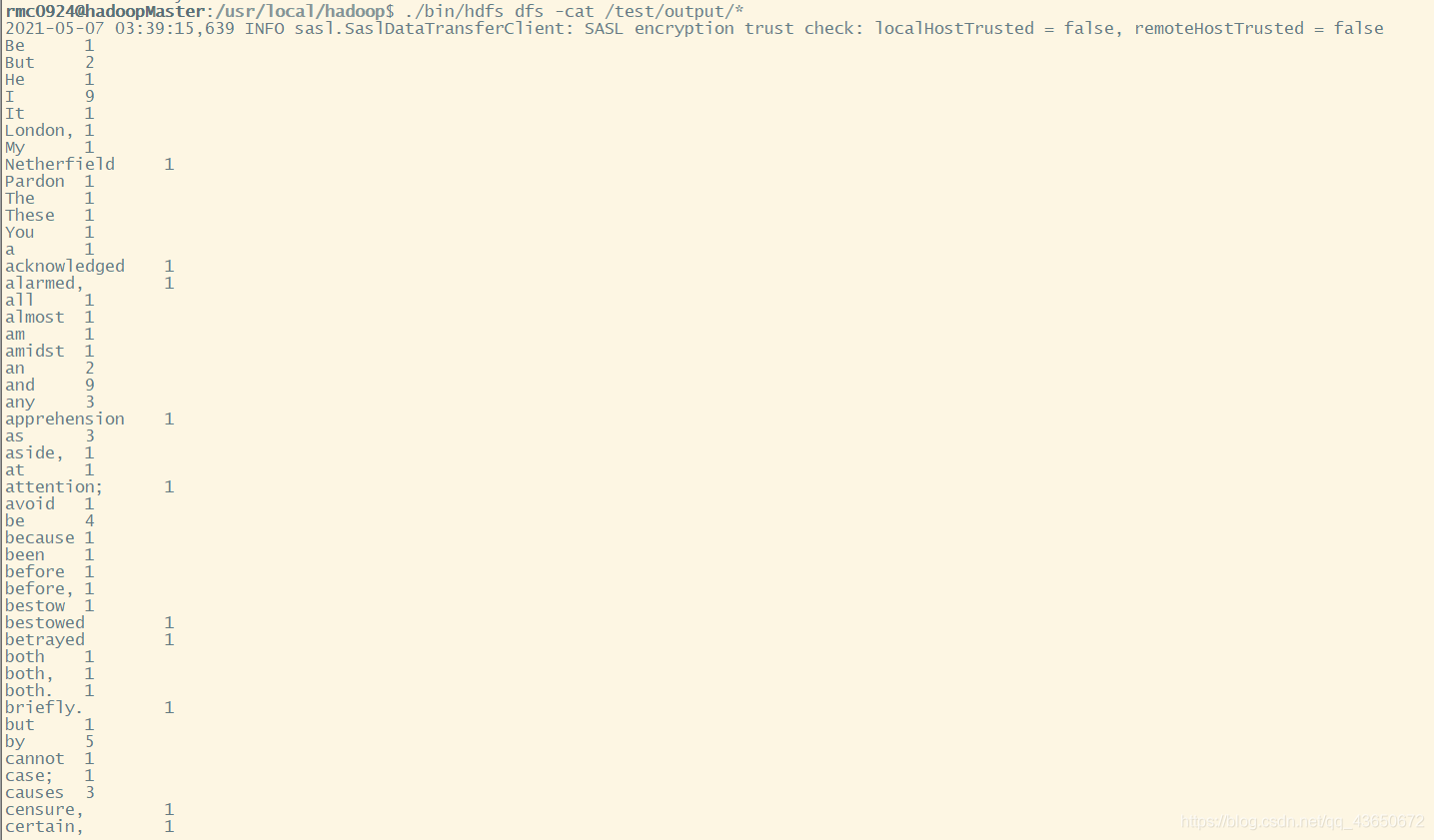
查看hdfs目录文件
在UI界面上点击Utilities显示下拉菜单,在下拉菜单中选择Browse the file system。
![[外链图片转存失败(img-r6m4Hvb5-1565707079264)(D:\学习笔记\hadoop\保存图片\安装Hadoop\HadoopUI界面查看hdfs存储文件.jpg)]](https://img-blog.csdnimg.cn/20190813223950768.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3h4eWR6eXI=,size_16,color_FFFFFF,t_70)
进入后,我们输入 / 查看根目录下存储的文件,因为集群刚刚创建,所以里面没有任何数据。
![[外链图片转存失败(img-4KkYV9Kz-1565707079265)(D:\学习笔记\hadoop\保存图片\安装Hadoop\HadoopUI界面查看hdfs存储文件01.jpg)]](https://img-blog.csdnimg.cn/20190813223940672.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3h4eWR6eXI=,size_16,color_FFFFFF,t_70)
我们在Linux系统上上传一个文件后再来这查看一下。
hdfs dfs -ls / # 查看hdfs根目录下的文件
hdfs dfs -mkdir /hellohdfs # 在根目录下创建一个名为hellohdfs的文件
hdfs dfs -put 1.txt /hellohdfs # 将1.txt上传到hellohdfs文件夹下
hdfs dfs -ls /hellohdfs # 查看 hellohdfs 文件夹下的文件
![[外链图片转存失败(img-dmXsEP4Z-1565707079265)(D:\学习笔记\hadoop\保存图片\安装Hadoop\HadoopUI界面查看hdfs存储文件02.jpg)]](https://img-blog.csdnimg.cn/20190813224005922.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3h4eWR6eXI=,size_16,color_FFFFFF,t_70)
![[外链图片转存失败(img-8I6TxeHP-1565707079266)(D:\学习笔记\hadoop\保存图片\安装Hadoop\HadoopUI界面查看hdfs存储文件03.jpg)]](https://img-blog.csdnimg.cn/20190813224016246.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3h4eWR6eXI=,size_16,color_FFFFFF,t_70)
查看YARN的UI界面
在浏览器输入:node-1:8088 即可进入yarn的ui界面。
[外链图片转存失败(img-AK5Pd6Of-1565707079267)(D:\学习笔记\hadoop\保存图片\安装Hadoop\HadoopUI界面查看yarn.jpg)]
在yarn上运行一个Hadoop自带的案例程序:计算圆周率。
使用命令:cd /export/server/hadoop-2.7.4/share/hadoop/mapreduce/ ,这个下面存放了一个example的jar包(java写的)。
这个案例用来计算圆周率。
使用命令Hadoop jar来加载jar包程序:hadoop jar hadoop-mapreduce-examples-2.7.4.jar pi 20 50
后面的pi 20 50 是所输入的参数(这个不用太深究,毕竟只是测试)。
![[外链图片转存失败(img-KOmwFvSS-1565707079267)(D:\学习笔记\hadoop\保存图片\安装Hadoop\初次尝试测试yarn上运行.jpg)]](https://img-blog.csdnimg.cn/20190813224034451.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3h4eWR6eXI=,size_16,color_FFFFFF,t_70)
在yarn的UI界面,我们可以看到正在运行的mr程序。
![[外链图片转存失败(img-tpnnzNFR-1565707079268)(D:\学习笔记\hadoop\保存图片\安装Hadoop\初次尝试测试yarn上运行01.jpg)]](https://img-blog.csdnimg.cn/20190813224050551.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3h4eWR6eXI=,size_16,color_FFFFFF,t_70)