目录
1.实验介绍
2.安装前准备
3.实验环境搭建
4.安装Hadoop
4.1下载Hadoop
4.2修改hadoop配置文件
5.启动Hadoop集群
6.Hadoop测试
1.实验介绍
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。
本实验使用四台虚拟主机搭建集群系统,网络拓扑如下

2.安装前准备
所需软件:
- Vmware Workstation 15 Pro
- Ubuntu 18.04.4镜像
参考教程:
- https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
- https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/ClusterSetup.html
- https://blog.csdn.net/yangrui1985123/article/details/103381645
注:Ubuntu18与低版本VMware不兼容,如果VMware版本过低,会安装失败,建议直接安装VMware最新版本。虚拟机安装只需不断点击下一步,直至完成。
3.实验环境搭建
- 搭建网络环境
设置hadoop0网络模式为NAT模式,在此模式下虚拟机可以联网并和主机互通
依次单击【编辑虚拟机设置】→【网络适配器】,选择“NAT模式”

在【编辑】菜单打开【虚拟网络编辑器】,单击【NAT模式】

单击【NAT设置】,查看网关IP

单击【DHCP设置】,查看可用的IP地址范围

打开hadoop0【设置】菜单,修改网络配置:
IPv4 Method: Manual
Addresses:192.168.133.128 255.255.25.0 192.168.133.2
DNS: 192.168.133.2
Routes: 192.168.133.2 255.255.25.0 192.168.133.2
地址必须在DHCP指定的范围,域名、网关和NAT网关地址相同,配置完成后重启网卡
- 修改hosts文件
在命令行输入:
sudo vim /etc/hosts添加4台服务器的节点名信息
hadoop0:192.168.133.128
hadoop1:192.168.133.130
hadoop2:192.168.133.129
hadoop3:192.168.133.131
- 安装所需软件
sudo apt-get install ssh
sudo apt-get install pdsh- 安装JDK1.8
下载地址https://www.oracle.com/java/technologies/javase-jdk8-downloads.html

在/usr/lib/目录创建java文件夹
sudo mkdir /usr/lib/java将下载的jdk复制到刚才创建的java文件夹中,解压文件
tar -zxvf /usr/lib/java/jdk-8u241-linux-x64.tar.gz配置环境变量, 编辑profile文件:
sudo vim /etc/profile
保存后,使刚才编辑的文件生效
source /etc/profile测试是否安装成功:
java -version如下表示jdk环境配置成功:

- 复制虚拟机
基础环境配置完成后将此虚拟机复制三份,打开虚拟机后单击【编辑虚拟机设置】→【选项】,依次修改虚拟机名称为hadoop1,hadoop2,hadoop3

依次配置ip地址分别为
hadoop1:192.168.133.130
hadoop2:192.168.133.129
hadoop3:192.168.133.131- 设置ssh免密
在hadoop0上配置主节点到所有机器(包括自己)ssh免密
ssh-keygen
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop34.安装Hadoop
4.1下载Hadoop
下载Hadoop3.2.1二进制包https://hadoop.apache.org/releases.html

将下载的Hadoop压缩包复制到/usr/local文件夹并解压,修改文件夹名称为hadoop
tar -zxvf /local/Hadoop/ hadoop-3.2.1.tar.gz将hadoop根目录添加到环境变量
sudo vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
保存后,使刚才编辑的文件生效
source /etc/profile
4.2修改hadoop配置文件
在hadoop0安装目录下打开etc/hadoop文件夹,可以看到Hadoop配置文件
cd /usr/local/Hadoop/etc/hadoop
- 配置hadoop_env.sh文件
export JAVA_HOME=/usr/lib/java/jdk1.8.0_241
export HDFS_NAMENODE_USER=baikun
export HDFS_DATANODE_USER=baikun
export HDFS_SECONDARYNAMENODE_USER=baikun
export YARN_RESOURCEMANAGER_USER=baikun
export YARN_NODEMANAGER_USER=baikunexport HADOOP_PID_DIR=/usr/local/hadoop/pids
export HADOOP_LOG_DIR=/usr/local/hadoop/logs
- 配置core-site.xml
根据自己的情况配置目录,fs.defaultFS为默认文件系统的名称,以主节点+端口命名,配置完成后新建/usr/local/hadoop/tmp文件夹
<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop0:8020</value></property><property><name>hadoop.tmp.fir</name><value>/usr/local/hadoop/tmp</value></property>
</configuration>
- 配置hdfs_site.xml
dfs.replication表示副本数量,配置完成后新建/usr/local/hadoop/hdfs/name和/usr/local/hadoop/hdfs/data文件夹
<configuration><property><name>dfs.namenode.http-address</name><value>hadoop0:50070</value></property><property><name>dfs.namenode.secondary.http-address</name><value>hadoop1:50090</value></property><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/hdfs/name</value></property><property><name>dfs.namenode.data.dir</name><value>file:/usr/local/hadoop/hdfs/data</value></property>
</configuration>
- 配置workers文件,添加DataNode数据节点
hadoop1
hadoop2
hadoop3
- 配置yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHadnler</value></property><property><name>yarn.resourcemanager.address</name><value>hadoop0:8032</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>hadoop0:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name><value>hadoop0:8031</value></property><property><name>yarn.resourcemanager.admin.address</name><value>hadoop0:8033</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>hadoop0:8088</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property>
</configuration>
- 配置mapred_site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>hadoop0:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop0:19888</value></property>
</configuration>
- ssh依次登陆其它服务器,修改/usr/local文件夹的写权限
ssh hadoop1
sudo chmod 777 /usr/local
exit
ssh hadoop2
sudo chmod 777 /usr/local
exit
ssh hadoop3
sudo chmod 777 /usr/local
exit
- 远程复制hadoop0的hadoop文件夹到其它服务器
sudo scp -r /usr/local/hadoop baikun@hadoop1:/usr/local/hadoop
sudo scp -r /usr/local/hadoop baikun@hadoop2:/usr/local/hadoop
sudo scp -r /usr/local/hadoop baikun@hadoop3:/usr/local/hadoop- 在hadoop0上打开hadoop文件夹写权限
sudo chmod -R 777 /usr/local/hadoop- 在hadoop0格式化NameNode,此步骤只需在hadoop初次安装后操作
sudo $HADOOP_HOME/bin/hdfs namenode -format
5.启动Hadoop集群
sudo $HADOOP_HOME/sbin/start-dfs.sh
sudo $HADOOP_HOME/sbin/start-yarn.sh
sudo $HADOOP_HOME/bin/mapred --daemon start historyserver
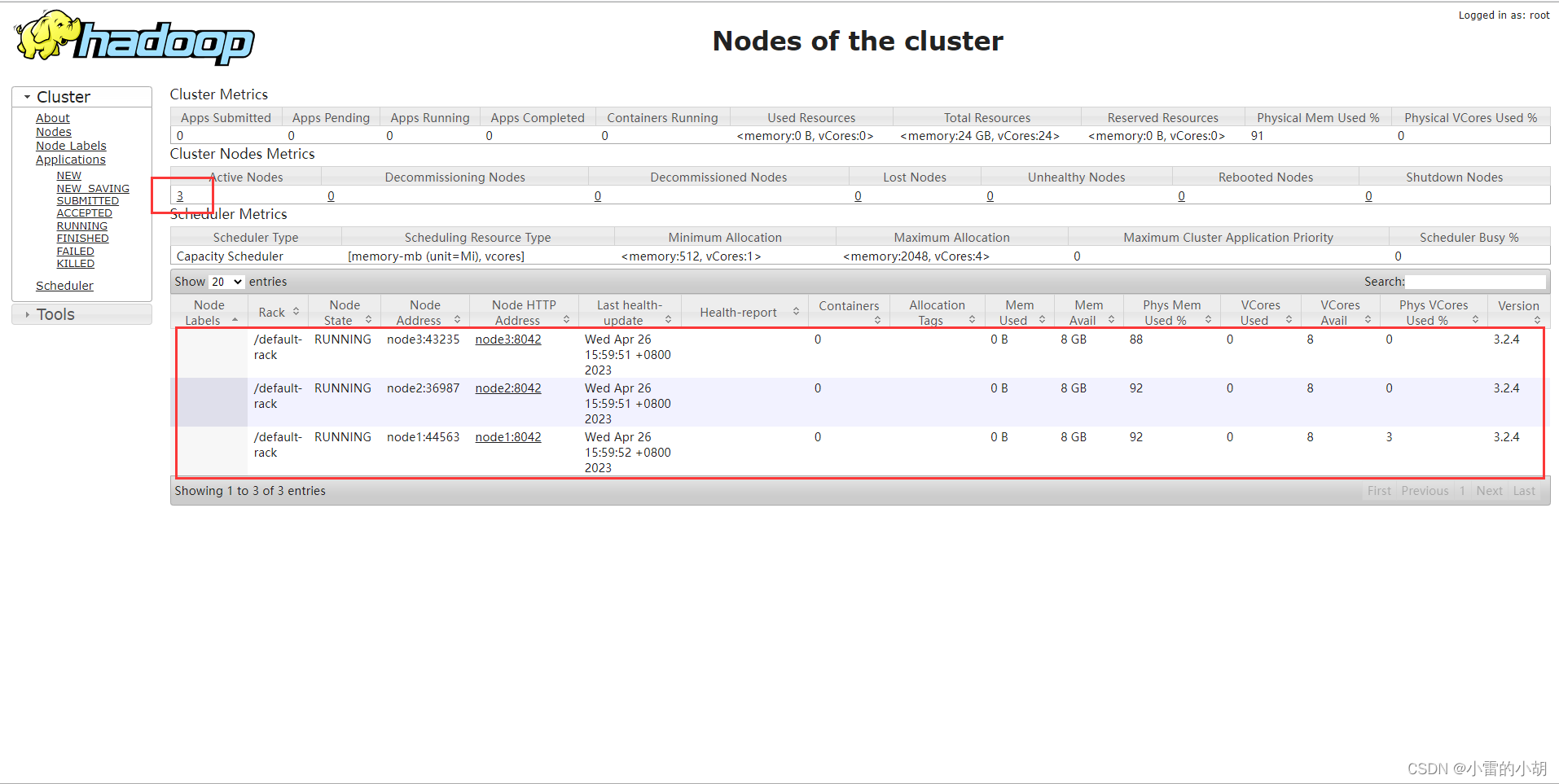
- 查看hdfs web
在浏览器中输入地址:http://192.168.133.128:50070


- 查看yarn web
在浏览器中输入地址:http://192.168.133.128:8088


6.Hadoop测试
- 关闭安全模式
Hadoop启动后默认运行在安全模式,此模式不可以创建文件夹、上传文件、删除文件,所以需要关闭安全模式
$HADOOP_HOME/bin/hdfs dfsadmin -safemode leave- 创建测试文件
在Hadoop文件夹下创建测试文件并随机输入一些字符
sudo mkdir /usr/local/hadoop/txt
sudo vim /usr/local/hadoop/txt/test.txt
- 将测试文件上传到Hadoop
在hadoop上创建/input文件夹
$HADOOP_HOME/bin/hadoop fs -mkdir /input将测试文件上传到/input文件夹
$HADOOP_HOME/bin/hadoop fs -put /usr/local/hadoop/txt/test.txt /input
- 查看结果
查看/input文件夹
$HADOOP_HOME/bin/hadoop fs -ls /input![]()
打印文件名、块报告、每个block的位置、DataNode网络拓扑结构
$HADOOP_HOME/bin/hadoop fsck /input/test.txt -files -blocks -locations -racks