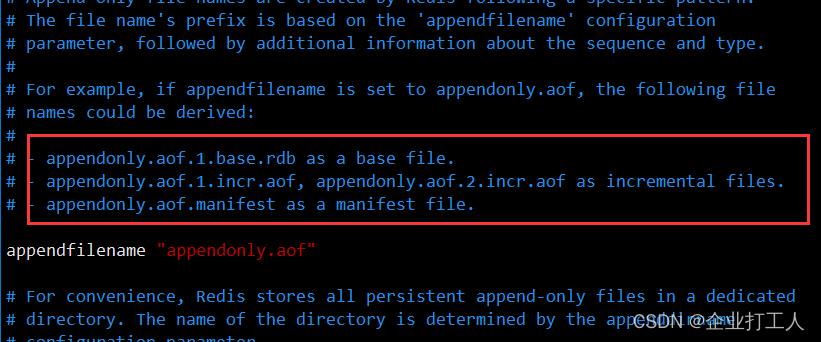
一、概念
Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce。HDFS是一个分布式文件系统,类似mogilefs,但又不同于mogilefs,hdfs由存放文件元数据信息的namenode和存放数据的服务器datanode组成;hdfs它不同于mogilefs,hdfs把元数据信息放在内存中,而mogilefs把元数据放在数据库中;而对于hdfs的元数据信息持久化是依靠secondary name node(第二名称节点),第二名称节点并不是真正扮演名称节点角色,它的主要任务是周期性地将编辑日志合并至名称空间镜像文件中以免编辑日志变得过大;它可以独立运行在一个物理主机上,并需要同名称节点同样大小的内存资源来完成文件合并;另外它还保持一份名称空间镜像的副本,以防名称节点挂了,丢失数据;然而根据其工作机制,第二名称节点要滞后主节点,所以当主名称节点挂掉以后,丢失数据是在所难免的;所以snn(secondary name node)保存镜像副本的主要作用是尽可能的减少数据的丢失;MapReduce是一个计算框架,这种计算框架主要有两个阶段,第一阶段是map计算;第二阶段是Reduce计算;map计算的作用是把相同key的数据始终发送给同一个mapper进行计算;reduce就是把mapper计算的结果进行折叠计算(我们可以理解为合并),最终得到一个结果;在hadoop v1版本是这样的架构,v2就不是了,v2版本中把mapreduce框架拆分yarn框架和mapreduce,其计算任务可以跑在yarn框架上;所以hadoop v1核心就是hdfs+mapreduce两个集群;v2的架构就是hdfs+yarn+mapreduce;
HDFS架构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mSQCg2Tu-1632577617270)(C:\Users\chmod\Desktop\HDFS.png)]
提示:从上图架构可以看到,客户端访问hdfs上的某一文件,首先要向namenode请求文件的元数据信息,然后nn就会告诉客户端,访问的文件在datanode上的位置,然后客户端再依次向datanode请求对应的数据,最后拼接成一个完整的文件;这里需要注意一个概念,datanode存放文件数据是按照文件大小和块大小来切分存放的,什么意思呢?比如一个文件100M大小,假设dn(datanode)上的块大小为10M一块,那么它存放在dn上是把100M切分为10M一块,共10块,然后把这10块数据分别存放在不同的dn上;同时这些块分别存放在不同的dn上,还会分别在不同的dn上存在副本,这样一来使得一个文件的数据块被多个dn分散冗余的存放;对于nn节点,它主要维护了那个文件的数据存放在那些节点,和那些dn存放了那些文件的数据块(这个数据是通过dn周期性的向nn发送);我们可以理解为nn内部有两张表分别记录了那些文件的数据块分别存放在那些dn上(以文件为中心),和那些dn存放了那些文件的数据块(以节点为中心);从上面的描述不难想象,当nn挂掉以后,整个存放在hdfs上的文件都将找不到,所以在生产中我们会借助zk集群(zookeeper)来对nn节点做高可用;对于hdfs来讲,它本质上不是内核文件系统,所以它依赖本地Linux文件系统;
mapreduce计算过程[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JhPZpXFR-1632577617274)(C:\Users\chmod\Desktop\mepreduce.png)]
提示:如上图所示,首先mapreduce会把给定的数据切分为多个(切分之前通过程序员写程序实现把给定的数据切分为多分,并抽取成kv键值对),然后启动多个mapper对其进行map计算,多个mapper计算后的结果在通过combiner进行合并(combiner是有程序员编写程序实现,主要实现合并规则),把相同key的值根据某种计算规则合并在一起,然后把结果在通过partitoner(分区器,这个分区器是通过程序员写程序实现,主要实现对map后的结果和对应reducer进行关联)分别发送给不同的reducer进行计算,最终每个reducer会产生一个最终的唯一结果;简单讲mapper的作用是读入kv键值对,输出新的kv键值对,会有新的kv产生;combiner的作用是把当前mapper生成的新kv键值对进行相同key的键值对进行合并,至于怎么合并,合并规则是什么是由程序员定义,所以combiner就是程序员写的程序实现,本质上combiner是读入kv键值对,输出kv键值对,不会产生新的kv;partitioner的作用就是把combiner合并后的键值对进行调度至reducer,至于怎么调度,该发往那个reducer,以及由几个reducer进行处理,由程序员定义;最终reducer折叠计算以后生成新的kv键值对;[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DtV3Fuwv-1632577617276)(C:\Users\chmod\Desktop\ways.jpg)]
提示:rm(resource manager)收到客户端的任务请求,此时rm会根据各dn上运行的nm(node manager)周期性报告的状态信息来决定把客户端的任务调度给那个nm来执行;当rm选定好nm后,就把任务发送给对应nm,对应nm内部会起一个appmaster(am)的容器,负责本次任务的主控端,而appmaster需要启动container来运行任务,它会向rm请求,然后rm会根据am的请求在对应的nm上启动一个或多个container;最后各container运行后的结果会发送给am,然后再由am返回给rm,rm再返回给客户端;在这其中rm主要用来接收个nm发送的各节点状态信息和资源调度以及接收各am计算任务后的结果并反馈给各客户端;nm主要用来管理各node上的资源和上报状态信息给rm;am主要用来管理各任务的资源申请和各任务执行后端结果返回给rm;
hadoop生态圈[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U6c5JdQb-1632577617281)(C:\Users\chmod\Desktop\hadoop.png)]
提示:上图是hadoop v2生态圈架构图,其中hdfs和yarn是hadoop的核心组件,对于运行在其上的各种任务都必须依赖hadoop,也必须支持调用mapreduce接口;
二、hadoop集群部署
| 名称IP | IP | 账号 | 密码 |
|---|---|---|---|
| maser | 10.67.15.187 | root | Aa123456 |
| slave1 | 10.67.15.101 | root | Aa123456 |
| slave2 | 10.67.15.102 | root | Aa123456 |
-
设置主机名称及hosts文件
master

slave1
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EiiSPQtu-1632577650686)(C:\Users\chmod\AppData\Roaming\Typora\typora-user-images\image-20210906140254184.png)]](https://img-blog.csdnimg.cn/2f817d58643a417ea700848f45e6b0cf.png)
slave2
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mbPXr8zV-1632577650689)(C:\Users\chmod\AppData\Roaming\Typora\typora-user-images\image-20210906140331994.png)]](https://img-blog.csdnimg.cn/b2541c00bd8d4f0b97ac446fd2997fa9.png)
分别配置3台服务器的hosts文件,如下:
vi /etc/hosts
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-koO5xcKr-1632577650691)(C:\Users\chmod\AppData\Roaming\Typora\typora-user-images\image-20210906140614445.png)]](https://img-blog.csdnimg.cn/69538f14a5d249b29ce2e97650c88176.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5LqR6K6h566X5aSn5pWw5o2u5bCP5pyL5Y-L,size_20,color_FFFFFF,t_70,g_se,x_16)
2. ssh免密操作
本操作是让master节点可以无密码SSH 到各个Slave节点上,操作步骤如下:
第一步:首先在master节点上执行以下命令,产生公钥私钥对:
ssh-keygen -t rsa
注:其他用默认设置,直接回车即可,如下图:

第二步:使用ssh-copy-id 将公钥复制到master、slave1和slave2上,其命令如下:
ssh-copy-id master
(注:输入master root用户密码)
ssh-copy-id slave1
(注:输入yes回车后,输入slave1 root用户的密码)
ssh-copy-id slave2
(注:输入yes回车后,输入slave2 root用户的密码)

第三步:测试是否成功,在Master节点上,执行以下命令,可直接SSH到对应的Slave节点
ssh master (免密登录到master)
ssh slave1 (免密登录到slave1)
ssh slave2 (免密登录到slave2)

3. 上传文件
| JDK和hadoop安装包 | |
|---|---|
| jdk-8u77-linux-x64.tar.gz | 版本兼容即可,不限版本 |
| hadoop-2.7.7.tar.gz | 版本兼容即可,不限版本 |
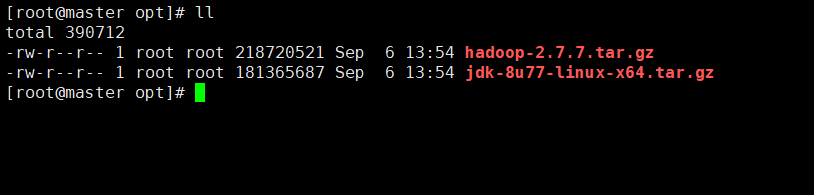
通过XFtp工具或者yum install lrzsz安装rz命令上传

我们上传到/opt目录下面即可
解压文件
命令:
mkdir /usr/local/hadoop
tar -zxvf jdk-8u77-linux-x64.tar.gz -C /usr/local/hadoop/
tar -zxvf hadoop-2.7.7.tar.gz -C /usr/local/hadoop/
==cd /usr/local/hadoop/ ==
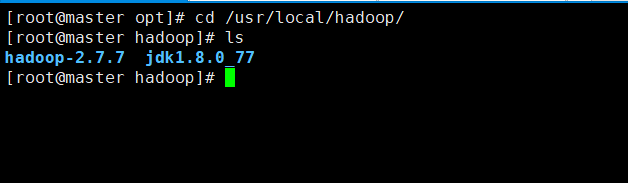
配置环境变量
vi /etc/profile
# JDK
export JAVA_HOME=/usr/local/hadoop/jdk1.8.0_77
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:$JAVA_HOME/bin:$PATH
# Hadoop
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH然后我们通过scp命令将它传到各节点

最后节点source一下,查看JDK环境和hadoop环境即可

5. 配置hadoop集群环境
配置Hadoop集群需要修改各个节点上/usr/local/hadooop/etc/hadoop下的6个配置文件
- slaves
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- slaves
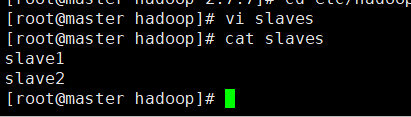
hadoop-env.sh
配置JDK环境
export JAVA_HOME=/usr/local/hadoop/jdk1.8.0_77

- core-site.xml
<property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/hadoop-2.7.7/tmp</value><description>Abase for other temporary directories.</description></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
- hdfs-site.xml
<property><name>dfs.namenode.secondary.http-address</name><value>master:50090</value></property> <property><name>dfs.replication</name><value>2</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/hadoop-2.7.7/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/hadoop-2.7.7/tmp/dfs/data</value></property>- mapred-site.xml
mv mapred-site.xml.template mapred-site.xml
<property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>master:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>master:19888</value></property>
- yarn-site.xml
<property><name>yarn.resourcemanager.hostname</name><value>master</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
配置完成以后,我们使用scp将/usr/localhost/haoop/*文件里面的东西复制到各节点
scp -r /usr/local/hadoop/ 10.67.15.101:/usr/local/
scp -r /usr/local/hadoop/ 10.67.15.102:/usr/local/首次启动需要先在master节点上执行namenode的格式化操作,其命令如下:
hdfs namenode -format完成Hadoop格式化后,在namenode节点上启动Hadoop各个服务,其命令如下:
start-all.sh
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jkcRlZLA-1632577962760)(C:\Users\chmod\AppData\Roaming\Typora\typora-user-images\image-20210906150656813.png)]](https://img-blog.csdnimg.cn/f938e3616c8d4fb29d5ed452f14a549d.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBA5LqR6K6h566X5aSn5pWw5o2u5bCP5pyL5Y-L,size_20,color_FFFFFF,t_70,g_se,x_16)
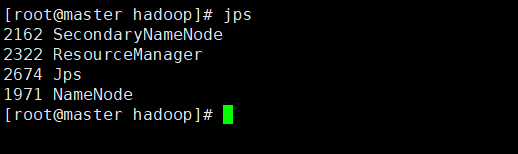
- master节点
- slave1
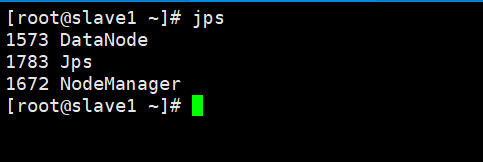
- slave2
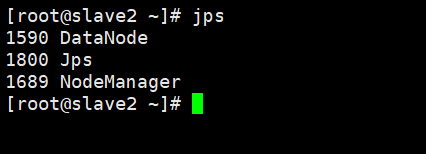
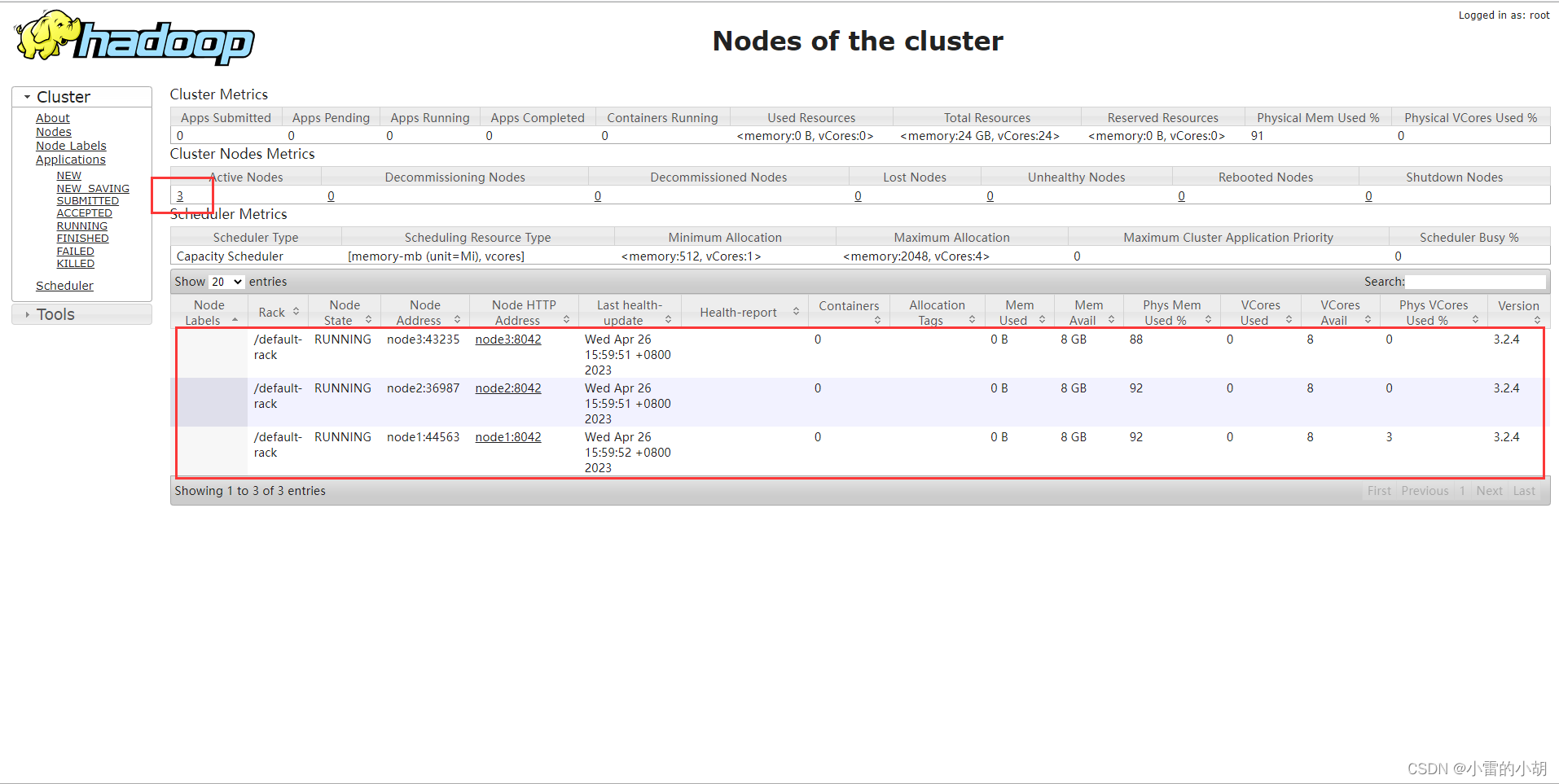
通过命令jps可以查看各个节点所启动的进程。正确的话,在Master节点上可以看到NameNode,ResourceManager,SecondaryNameNode,JobHistoryServer进程。
在Slave节点可以看到DataNode和NodeManager进程。
缺少任一进程都表示出错。另外还需要在Master节点上通过命令hdfs dfsadmin -report查看
hdfs dfsadmin -report

详情查看StrivePine博客