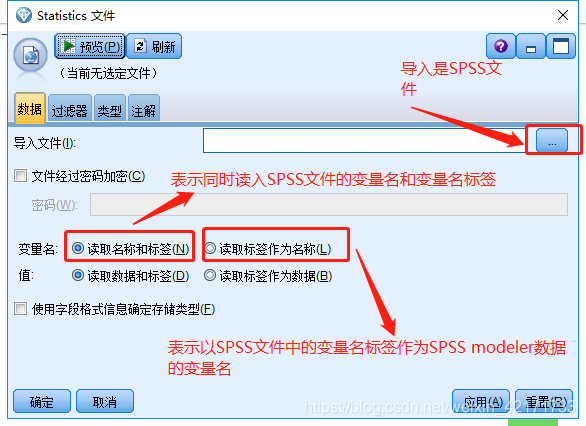
摘要
基于ieee802.11标准的Wi-Fi系统是最流行的无线接口,它采用先听后讲(LBT)的方式进行信道接入。大多数基于LBT的系统的显著特征是,发射机使用在数据之前的前导码来允许接收机执行分组检测和载波频率偏移(CFO)估计。前导码通常包含具有良好相关特性的训练符号的重复,而传统的数字接收机将基于相关的方法用于包检测和CFO估计。然而,近年来,基于数据的机器学习方法正在扰乱物理层的研究。特别是在基于深度学习(DL)的信道估计领域,已经给出了令人鼓舞的结果。在本文中,我们提出了一个性能和复杂性分析的数据包检测和CFO估计使用传统的和基于DL的方法。本研究的目的是探讨在何种条件下,基于DL的方法的性能优于甚至超过传统方法,但在何种条件下,其性能较差。我们的研究以新兴的ieee802.11ah标准为重点,使用了基于标准的模拟环境和基于软件无线电的真实测试平台。
索引项:深度学习,载波频率偏移估计,IEEE 802.11ah
介绍
基于正交频分复用(OFDM)的无线通信系统是当前无线通信研究和发展的主流。为了确保公平性,无线系统在未经许可的频段中使用先听后讲(LBT)方法共享一个公共信道。在大多数LBT系统中,通常的方法是发射机向数据包发送预编码,以确保接收机检测到信号并获得初始同步。前导码通常包含具有良好相关特性的符号序列,允许接收端识别包开始样本并建立初始定时和频率偏移同步。OFDM接收机中传统的基于模型的信号处理方法已经被很好地理解,并且目前被用作接收机设计的基础[1]-[9]。
传统方法最近受到依赖深度学习(DL)的基于数据的方法的挑战[10]-[12]。基于DL的方法已经在整个物理系统中进行了评估层(PHY)、跨信号检测的测距[13]、信道估计[14]、[15]和纠错编码[16],与传统方法相比,显示了良好的性能。此外,最近研究了利用信道状态信息作为指纹的基于DL的定位服务[17]。然而,在大多数基于DL的PHY研究中,假设接收机处的信号检测是完全已知的,其包括在信道估计之前的过程,例如分组检测和载波频率偏移(CFO)估计。此外,专门针对基于前导码的LBT OFDM系统的基于DL的PHY方法的研究也缺失,信道估计领域除外[18]。
本文主要研究ieee802.11系统中基于DL的包检测和CFO估计方法。本文扩展了我们最近对包检测的研究[19]。为了提供一个详细的、特定于标准的调查,我们考虑了一个新兴的ieee802.11ah标准,用于低功耗物联网(IoT)应用[20]。我们使用基于标准的模拟环境和基于软件无线电(sdr)的真实测试平台来评估我们的结果。
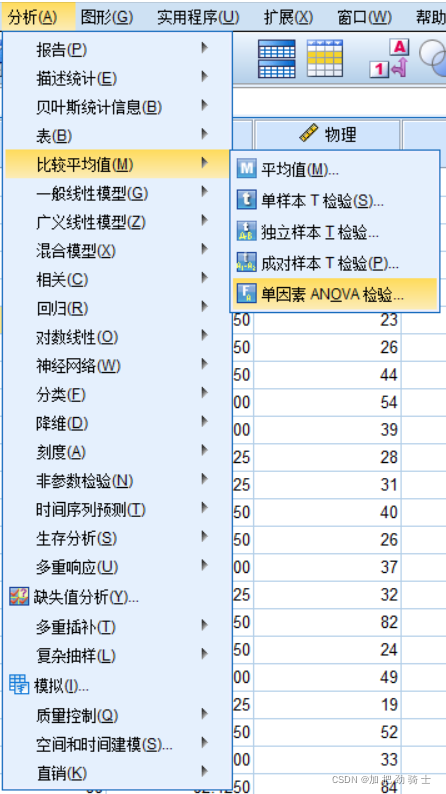
本文主要分为两个部分。在论文的第一部分中,我们重点研究了分组检测问题,给出了详细的复杂度与性能评估,并对传统的和基于DL的分组检测进行了比较。结果表明,基于一维卷积神经网络(1D-CNN)的DL方法在减少计算量的情况下,性能优于传统方法,但漏检率和虚警率较低。
在论文的第二部分,我们研究了基于DL的CFO估计方法,并将其与传统方法进行了比较。结果表明,在ieee802.11ah接收机上,基于长-短记忆(LSTM)的递归神经网络(RNN)算法的CFO估计性能与传统方法相当,甚至在中低信噪比(SNR)下优于传统方法。然而,与传统方法相比,基于DL的方法具有更高的复杂度。
A.相关工作和论文投稿
使用DL进行物理处理是一个非常活跃的研究领域。然而,最近的工作大多集中在信道估计上,假设信号的检测和处理都是在信道估计的基础上进行的同步是理想的。然而,最近的一些论文在几种情况下讨论了基于DL的信号检测。
文献[21]中的作者解决了OFDM接入(OFDMA)系统上行链路中的CFO问题,其中DL用于次优估计对应于不同用户的CFO。文[22]研究了新兴的毫米波多输入多输出(MIMO)系统中,低分辨率模数转换后接收信号的基于DL的CFO,与传统方法相比,证明了改进的性能。对于基于OFDM的无人机通信,CFO的DL方法在[23]中提出。我们在CFO估计部分的工作受到了[13]的影响,这是一个早期的单载波系统中基于DL的CFO估计的研究。最后,在[24]中对ieee802.11ax接收机设计的DL方法进行了全面的概述。
这项工作的贡献总结如下:
- 我们在基于前导码的ieee802.11系统中引入了一种基于DL的包检测算法,并与传统的包检测算法进行了系统性能和复杂度比较。文[19]中给出的初始结果用额外的数值结果和基于SDR的真实世界演示进行了扩展;
- 在基于前导码的ieee802.11系统中,我们比较了基于DL和传统CFO方法的系统性能和复杂度;
- 我们的结果在基于标准的ieee802.11ah模拟环境中得到了验证,并在一个使用sdr的真实环境中得到了验证;
- 该研究提供了一个清晰的见解,在哪些条件下,基于DL的方法的性能可能接近甚至超过传统的包检测和CFO估计方法,但在哪些条件下,它们的性能较差。
论文的结构如下。以秒为单位。二、 我们提出了系统模型并回顾了ieee802.11ah帧结构。秒。第三章讨论了数据包检测问题,首先描述了传统的和基于DL的方法,然后通过数值模拟和真实世界的SDR实验进行了评估。以类似的方式,第。第四章介绍并比较了传统的和基于DL的CFO估计方法,包括基于模拟和真实SDR的结果。本文在第二节结束。五。
背景和系统模型
略~
三、 基于前导码的包检测
B.基于深度学习的数据包检测
2) 真实环境:为了在真实环境中评估提出的方法,我们使用软件无线电(SDR)实现来收集数据集。我们在室内环境中部署了真实世界的设置,将发射机放置在一系列预定义的网格点上,而接收机是静止的,如图5所示。注意,20个发射机位置中有12个与接收机在同一个房间,其余8个在相邻的房间,从而为我们提供了范围更广的接收信噪比数据集。

发射机和接收机都包括标准兼容的基于MATLAB的802.11ah PHY实现和USRP B210 SDR平台,如图6所示。从每个点,发射机发送1000个1 MHz NDP数据包,测量SNR范围∈ [−6分贝,31分贝)。在接收机侧,在滤波和下采样之后获得的复基带数据样本被收集并分离成长度为40、80、160、320、800和1600样本的输入块y。大约50%的区块不包含包含数据包启动实例,从而生成一个由40000(| y |)组成的数据集,τS) 配对(70%用于培训,15%用于验证,15%用于测试)。其他系统假设和参数与模拟环境中的相同。

四、 基于前导码的CFO估计
在论文的第二部分,我们考虑了基于深度学习的CFO估计在ieee802.11ah中的实现,并与传统的CFO估计方法进行了性能比较。
A.传统CFO估计
CFO估计的一种常见方法使用两个连续相同的短训练符号的样本通过与CFO foff成比例的相移而不同的事实:
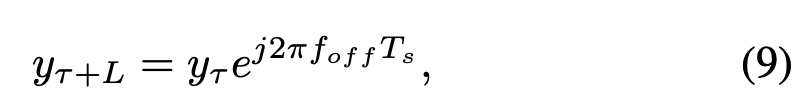
B.基于深度学习的CFO估计
在本文中,我们测试了所选择的DNN架构 从接收STF符号的相位估计CFO的能力
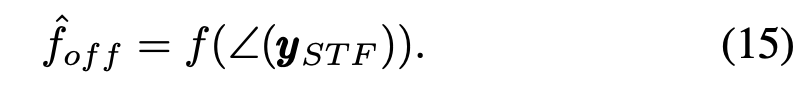
换句话说,DNN体系结构学习接收到的数据之间的映射∠(yST F)和fof。注意,与同时使用STF和LTF字段的传统方法不同,我们仅在STF字段上测试基于DNN的CFO估计。接下来,我们详细介绍了用于CFO估计的DNN结构,并描述了数据集和训练过程。
1) 全连接前馈神经网络:
这种神经网络结构由输入、输出和隐层组成,是一种简单且易于理解的DNN模型。输入x和输出y之间的关系是计算单元的分层组合:
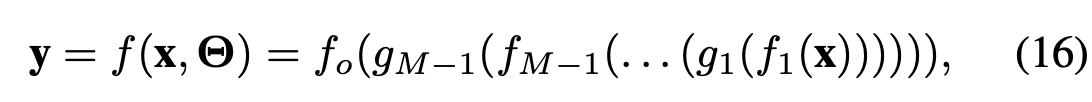
哪里Θ 表示网络参数集:权Wi和偏压bi,
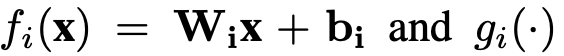
分别为第i个隐层的线性预激活函数和激活函数,fo(·)为输出层的线性函数,M为层数。在非线性激活函数中,我们关注的是校正线性单元(ReLU),因为ReLU DNNs是一大类函数的通用分段线性函数逼近器[30]。
2) 递归神经网络:
RNN代表基于序列的模型,能够在先前和当前环境之间建立时间相关性。图13给出了单层RNN的简单示例,其中前一时间步t的输出− 1成为当前时间步长t的输入的一部分,从而捕获过去的信息。一个RNN单元执行的计算结果可以表示为以下函数[31]:
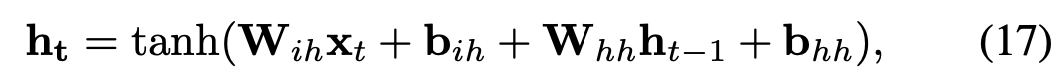
其中tanh表示双曲正切函数ht和ht−1是时间步t和t的隐藏状态−1,W,W和b,b分别是需要学习得出的权重和偏差,时间t的输入表示为xt。

由于梯度的消失或爆炸,基本的RNN细胞无法学习长程依赖性。为了解决这个问题,长-短时间记忆(LSTM)[32]单元是在循环隐藏层中包含称为记忆块的特殊单元,增强了其建立长期依赖关系模型的能力。此块是一个循环连接的子网,包含称为内存单元和门的功能模块。前者记住网络的时态,后者控制来自前一个小区状态的信息流。
除了标准的LSTM细胞外,我们还考虑了门控循环单位(GRU)[33]。LSTMs的主要思想被保留,但是GRU只引入了两个门,更新门和重置门来控制信息流。GRU的性能与LSTM类似,但执行时间减少[34]。
3) 训练过程:
为了训练DNN模型,我们最小化MSE损失:
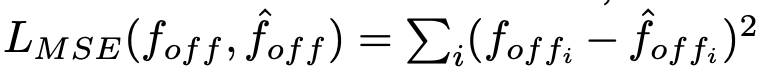
将MSE-off-i-offi训练集划分为大小为100的小批量,500个历元足以实现损失函数的收敛。网络参数的优化方法与Sec中的相同。III-B,即以学习率使用SGD和Adam
ReLU-DNN包括五层:160个神经元的输入层、32个、64个和16个神经元的三个隐藏层和一个单神经元的输出层。RNN由一个具有30个单元的LSTM或GRU层、一个具有5个神经元的ReLU FC层和一个输出单神经元层组成。不像ReLU DNN,输入是整个序列∠(在RNN,这个序列被分成STS(16个样本),一个STS被输入一个LSTM/GRU单元。
C.数据集生成
1) 模拟环境:
使用模拟环境,我们生成成对的数据集
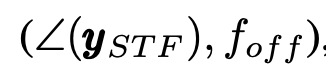
其中foff表示在传输过程中引入的CFO。经过采样和过滤,ySTF由160个样本组成(16个样本重复10次)。我们模拟了50000个NDP数据包的传输,提取了STF相位矢量,同时在模拟中均匀地随机地从中生成了相应的真CFO值
![[−∆f、f、,∆f]=[−15.625千赫,15.625千赫]。](https://img-blog.csdnimg.cn/20210616170215764.png)
70%的记录用于培训,15%用于验证,15%用于测试。为了检验估计器的稳健性,NDP包被接收到的snr范围在1db到25db之间。根据模拟的信道模型,创建了两个数据集:i)AWGN信道和ii)室内多径衰落信道-模型B[29]。
2) 真实环境:
在真实环境中用于生成数据集的设置与SecIII-C中的设置相同。从每个网格点,发射机发送1000个1兆赫的NDP数据包与测量的SNR范围∈ [−6分贝,31分贝]。在接收端,在包检测之后,STF相位向量被提取

收集的数据集由20000个组成
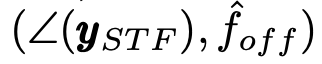
配对(70%用于培训,15%用于验证,15%用于测试),其中作为标签fˆ 我们使用传统算法估计的CFO。这是因为,在现实条件下,我们对传输过程中引入的CFO没有先验知识。因此,在这种情况下,我们训练基于DL的CFO估计器来复制传统方法的性能。
还要注意的是,与CFO值从给定间隔均匀随机生成的模拟环境不同,在实际实验中,两个SDR设备之间的估计CFO值几乎是平稳的。