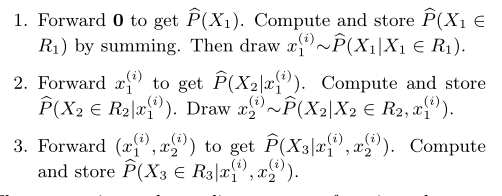当地时间2019年8月26至30日,VLDB 2019会议在美国加利福尼亚召开,腾讯分布式数据库TDSQL与中国人民大学最新联合研究成果被VLDB 2019接收并将通过长文形式发表。VLDB是国际数据管理与数据库领域顶尖的学术会议之一,这是继去年腾讯TDSQL相似度计算的论文被VLDB录用后,腾讯TDSQL再一次迈进VLDB殿堂。
论文中,腾讯介绍了基于TDSQL扩展而来的全时态数据库系统(T-TDSQL)。该系统在保证OLTP性能的前提下,提供了轻量级的全时态数据管理功能和全时态数据的事务处理能力,以及集当前态数据于生产系统、集历史态数据于分析型系统的集群架构,构成了全时态数据的完备解决方案。

当前态数据库和历史态数据都是具有价值的,并且全时态数据为数据安全、数据重演、数据挖掘和AI技术的施展提供了物理基础,还可以进一步建立数据之间的关联关系以实现“数据血统”的逻辑等,这使得TDSQL具备了在海量全时态数据上的分析计算能力。
一般主流数据库由于技术复杂度原因,不会保存历史态数据,丢弃了有价值的历史态数据,这成为许多企业机构数字化时代面临的痛点。腾讯分布式数据库TDSQL推出的具备海量时态数据计算能力的解决方案T-TDSQL,突破在于具备全时态数据模型,全时态数据存储、查询、计算等特性,并在保持全局一致性的基础上拥有高效的性能,真正实现为数据赋能。
据了解,论文提出了一种拓展的全时态数据模型,并提供了内建的全时态数据库解决方案,在针对TDSQL进行大量优化后,最终实现TDSQL全时态数据库系统。通过引入异步数据迁移、增量历史数据管理、原生全时态查询执行器等策略,使得该解决方案可实现轻量且高效的全时态数据管理计算。
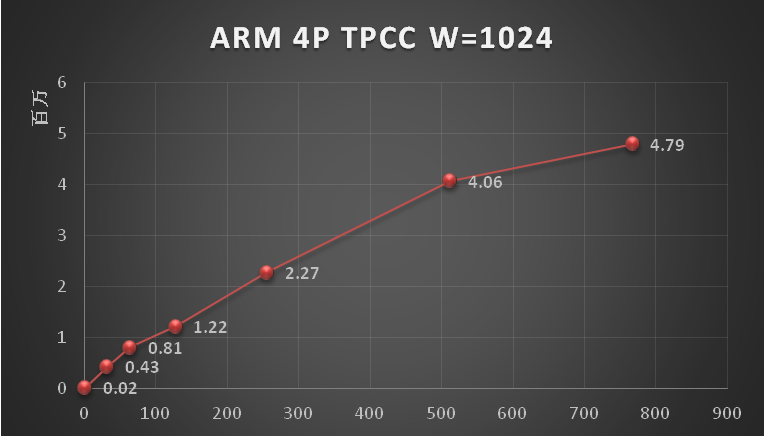
通过TPCC测试基准,基于TDSQL实现的全时态数据库系统的系统性能相较于原始TDSQL下降率均值不到6%,领先于其他基于传统关系数据库实现的时态数据库系统。另外,基于真实的批处理业务场景实验结果显示,腾讯全时态数据库系统在简化业务应用开发的同时,可以缩短近一半的业务执行时间。
更重要的是,该解决方案具有很强的通用性,可以方便地引入到其他数据库系统中。
TDSQL是腾讯TEG计费平台部自主研发的金融级分布式数据库,十几年来承载了腾讯近90%的金融、交易、计费类业务。从2014年开始,TDSQL通过腾讯金融云平台对外开放,提供稳定可靠的云数据库服务,目前在公有云上服务金融机构500余家,为中国银行、微众银行在内的超过44家银行及政企机构提供专有云服务。

TDSQL一直致力于数据库技术自主研发投入,在VLDB2018上,腾讯TDSQL通过Short Paper展示了合作成果MSQL+ ,一个基于TDSQL的插件式近似查询工具https://mp.weixin.qq.com/s/BZZOH20NfRyCltPkl7Q7_Q。并向学界贡献领先的研究成果。同时,腾讯TDSQL持续通过腾讯高校合作犀牛鸟科研专项、高校联合实验室等平台与学界建立科研合作,推动技术创新。本次入选论文也是基于与人大长期高校合作产出的优秀成果。
在不断提升性能、完善配套服务之余,包括TDSQL在内的腾讯云数据库也一直秉承开放、共享的心态参与开源。未来,TDSQL将继续加大技术投入,持续提升产品能力,助力企业数字化转型升级。
本文由博客一文多发平台 OpenWrite 发布!
![【轨迹压缩】Trajectory Simplification: On Minimizing the Direction-based Error [2015] [VLDB]](https://img-blog.csdnimg.cn/be6eda238261421d9b8f96b6adf26c3f.png)