这篇博文主要是对 2021 VLDB Summer School Lab0 的一个总结
这个lab与MIT 6.824 的 lab1 相似,个人感觉比MIT 6.824 的 lab1 要稍微简单些,更容易上手。通过这个lab,可以学习到一些 Golang 的基础知识并对分布式系统有一个基础的了解,我做下来感觉文档写得十分完善,包括需要的一些前置知识都说得很清楚,同时还提供了一些学习资源,强烈推荐分布式系统的初学者做一下这个lab,传送门:https://github.com/tidb-incubator/vldbss-2021/tree/master/lab0
Map-Reduce简介
我之前对Map-Reduce只是简单听说过,没有仔细了解,我首先看了lab里推荐的 MIT 6.824 课程,不过一节课1个多小时,感觉节奏稍微有点慢,我就直接找的原始论文《MapReduce: simplified data processing on large clusters》 对Map-Reduce进行了一个简要地学习。
简单来说,Map-Reduce是一个分布式的用来处理大规模数据的High-Level框架,之所以称之为High-Level是因为在设计它时就是为了让它能够处理大部分分布式数据处理任务,即适用范围要广,所以它的抽象程度会比较高。
整个Map-Reduce框架的主要组成部分如下图所示:

执行流程大致为:
- 读入输入文件
- Master分配分布式集群中的worker(一台可以用于计算的服务器)对输入数据执行map操作,并将执行结果写入该worker的本地磁盘
- map操作的结果成功写入磁盘后会通知Master,此时Master会分配一个reduce任务给一台空闲worker 同时告诉它去哪可以取到map操作的结果,这时这台worker会通过RPC(Remote Procedure Call,远程过程调用)取到map操作的结果,然后以此作为输入执行reduce操作,最后将reduce操作的结果输出为一个单独的文件,注意此时与map操作结果直接写入worker本地不同,reduce操作结果的输出目的地一般是GFS等分布式文件系统或者是作为下一轮Map-Reduce的输入
在这整个过程中,只有Map操作和Reduce操作是由用户自己编写,其余的均由框架完成。
也就是说,我们只关心Map函数和Reduce函数应该完成哪些任务,就可以完成各种各样的分布式数据处理任务,使得分布式处理任务的编码成本得以降低,这也是Map-Reduce框架的主要意义所在。
Lab0 任务一:完成 Map-Reduce 框架
这次lab设计得对初学者十分友好,lab中提供的源码对Map-Reduce框架已经完成了很大一部分,包括Map阶段的代码都是完整的,所以初学者经过简单地学习go语言之后,可以通过阅读框架中已经写好的代码进行快速地上手。
从最简单的的开始,我们首先对Reduce阶段进行实现。
Reduce阶段需要拿到对应的map操作的执行结果,然后以此作为输入执行reduce操作,最后将执行结果输出为一个文件即可,具体代码如下:
// YOUR CODE HERE :)// hint: don't encode results returned by ReduceF, and just output// them into the destination file directly so that users can get// results formatted as what they want.if t.phase != reducePhase {panic("unknown task phase")}reduceRes := make(map[string][]string)for i := 0; i < t.nMap; i++ {//通过文件名规则拿到对应map的结果mappedFileName := reduceName(t.dataDir, t.jobName, i, t.taskNumber)mappedFile, err := os.Open(mappedFileName)if err != nil {log.Fatalln("open mapped file error: ", mappedFileName, " error: ", err)}dec := json.NewDecoder(mappedFile)for {var kv KeyValueif err := dec.Decode(&kv); err != nil {break //EOF}if _, exist := reduceRes[kv.Key]; !exist {reduceRes[kv.Key] = make([]string, 0)}reduceRes[kv.Key] = append(reduceRes[kv.Key], kv.Value)}SafeClose(mappedFile, nil)}fs, bs := CreateFileAndBuf(mergeName(t.dataDir, t.jobName, t.taskNumber))for k, v := range reduceRes {//输出Reduce结果WriteToBuf(bs, t.reduceF(k, v))}SafeClose(fs, bs)观察发现,Map-Reduce 框架需要补充的部分就还剩:Master分发的Map任务都执行完毕之后的执行逻辑
分析得知,map任务都执行完毕之后需要接着分发Reduce任务,对着上面已经写好的Map任务分发逻辑,可以照猫画虎地对Reduce任务分发逻辑进行编写:
// reduce phase// YOUR CODE HERE :DreduceTasks := make([]*task, 0, nReduce)for i := 0; i < nReduce; i++ {t := &task{dataDir: dataDir,jobName: jobName,phase: reducePhase,taskNumber: i,nMap: nMap,reduceF: reduceF,}t.wg.Add(1)reduceTasks = append(reduceTasks, t)go func() { c.taskCh <- t }()}for _, t := range reduceTasks {t.wg.Wait()}以终为始,我们可以通过查看测试函数是如何进行测试的来分析Reduce操作都结束之后是否还需要进行其他操作:
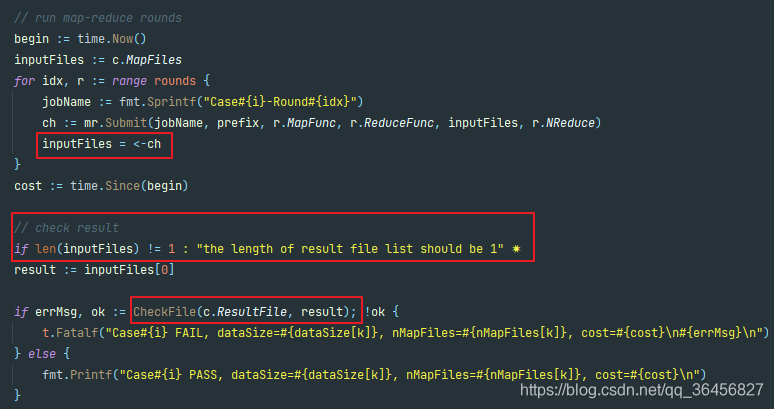
通过分析测试函数(位于urltop10_test.go中)可以发现,测试的逻辑是首先通过Submit函数的返回拿到一个channel,再通过这个channel拿到结果文件,最后通过将这个结果文件和正确结果进行对比从而完成测试,这里需要注意的是最后的输出文件列表最终应该只有一个文件,而每一个Reduce操作都会输出一个结果文件,也就是说最后一轮Reduce操作应该只有唯一的一个worker执行。
分析下来得知,最后我们只需要将Reduce操作的结果放入对应的channel,以便让测试函数拿到这个结果即可:
results := make([]string,0,nReduce)for i := 0; i < nReduce; i++ {results = append(results, mergeName(dataDir, jobName, i))}notify <- results至此,我们就完成了 Map-Reduce 框架。
下面可以通过lab中的make test_example来测试我们的编码是否正确,由于我是直接在我的PC上跑,有可能会出发超时错误,所以我更改了一下test_example脚本,放宽超时时间到一个小时,更改后的脚本如下:
test_example:go test -v -timeout 60m -run=TestExampleURLTop执行
make test_example > ./log/test_example.log进行测试,同时将测试结果重定向输出到test_example.log,测试结果如下:
go test -v -timeout 60m -run=TestExampleURLTop
=== RUN TestExampleURLTop
Case0 PASS, dataSize=1MB, nMapFiles=5, cost=54.1068ms
Case1 PASS, dataSize=1MB, nMapFiles=5, cost=35.8471ms
Case2 PASS, dataSize=1MB, nMapFiles=5, cost=34.1654ms
Case3 PASS, dataSize=1MB, nMapFiles=5, cost=43.7147ms
Case4 PASS, dataSize=1MB, nMapFiles=5, cost=79.54ms
Case5 PASS, dataSize=1MB, nMapFiles=5, cost=49.3617ms
Case6 PASS, dataSize=1MB, nMapFiles=5, cost=46.5659ms
Case7 PASS, dataSize=1MB, nMapFiles=5, cost=50.0676ms
Case8 PASS, dataSize=1MB, nMapFiles=5, cost=48.8755ms
Case9 PASS, dataSize=1MB, nMapFiles=5, cost=41.0224ms
Case10 PASS, dataSize=1MB, nMapFiles=5, cost=38.5016ms
Case0 PASS, dataSize=10MB, nMapFiles=10, cost=320.2324ms
Case1 PASS, dataSize=10MB, nMapFiles=10, cost=167.8428ms
Case2 PASS, dataSize=10MB, nMapFiles=10, cost=120.667ms
Case3 PASS, dataSize=10MB, nMapFiles=10, cost=119.6882ms
Case4 PASS, dataSize=10MB, nMapFiles=10, cost=641.7379ms
Case5 PASS, dataSize=10MB, nMapFiles=10, cost=321.3038ms
Case6 PASS, dataSize=10MB, nMapFiles=10, cost=301.4055ms
Case7 PASS, dataSize=10MB, nMapFiles=10, cost=364.9047ms
Case8 PASS, dataSize=10MB, nMapFiles=10, cost=223.7273ms
Case9 PASS, dataSize=10MB, nMapFiles=10, cost=178.8921ms
Case10 PASS, dataSize=10MB, nMapFiles=10, cost=158.2368ms
Case0 PASS, dataSize=100MB, nMapFiles=20, cost=3.1390011s
Case1 PASS, dataSize=100MB, nMapFiles=20, cost=1.3893513s
Case2 PASS, dataSize=100MB, nMapFiles=20, cost=954.1715ms
Case3 PASS, dataSize=100MB, nMapFiles=20, cost=2.4240299s
Case4 PASS, dataSize=100MB, nMapFiles=20, cost=2.7511003s
Case5 PASS, dataSize=100MB, nMapFiles=20, cost=3.6331775s
Case6 PASS, dataSize=100MB, nMapFiles=20, cost=3.2044724s
Case7 PASS, dataSize=100MB, nMapFiles=20, cost=3.9406203s
Case8 PASS, dataSize=100MB, nMapFiles=20, cost=2.0936492s
Case9 PASS, dataSize=100MB, nMapFiles=20, cost=1.5503635s
Case10 PASS, dataSize=100MB, nMapFiles=20, cost=1.2076629s
Case0 PASS, dataSize=500MB, nMapFiles=40, cost=25.4456317s
Case1 PASS, dataSize=500MB, nMapFiles=40, cost=14.8783234s
Case2 PASS, dataSize=500MB, nMapFiles=40, cost=10.4408874s
Case3 PASS, dataSize=500MB, nMapFiles=40, cost=10.4135559s
Case4 PASS, dataSize=500MB, nMapFiles=40, cost=10.8568517s
Case5 PASS, dataSize=500MB, nMapFiles=40, cost=21.310093s
Case6 PASS, dataSize=500MB, nMapFiles=40, cost=18.2229292s
Case7 PASS, dataSize=500MB, nMapFiles=40, cost=18.1044385s
Case8 PASS, dataSize=500MB, nMapFiles=40, cost=14.2397967s
Case9 PASS, dataSize=500MB, nMapFiles=40, cost=12.504795s
Case10 PASS, dataSize=500MB, nMapFiles=40, cost=14.0792216s
Case0 PASS, dataSize=1GB, nMapFiles=60, cost=48.314779s
Case1 PASS, dataSize=1GB, nMapFiles=60, cost=29.9605215s
Case2 PASS, dataSize=1GB, nMapFiles=60, cost=21.816549s
Case3 PASS, dataSize=1GB, nMapFiles=60, cost=20.0377209s
Case4 PASS, dataSize=1GB, nMapFiles=60, cost=20.6936616s
Case5 PASS, dataSize=1GB, nMapFiles=60, cost=47.7212088s
Case6 PASS, dataSize=1GB, nMapFiles=60, cost=41.5137968s
Case7 PASS, dataSize=1GB, nMapFiles=60, cost=44.1715308s
Case8 PASS, dataSize=1GB, nMapFiles=60, cost=32.9036035s
Case9 PASS, dataSize=1GB, nMapFiles=60, cost=24.7098543s
Case10 PASS, dataSize=1GB, nMapFiles=60, cost=2m32.8035366s
--- PASS: TestExampleURLTop (881.19s)
PASS
ok talent 881.572s测试通过,总耗时为:881.572s
至此lab0的任务一完成
Lab0 任务二:基于 Map-Reduce 框架编写 Map-Reduce 函数
lab在urltop10_example.go中提供了 Map-Reduce 函数的一种实现供我们参考:
func ExampleURLTop10(nWorkers int) RoundsArgs {var args RoundsArgs// round 1: do url countargs = append(args, RoundArgs{MapFunc: ExampleURLCountMap,ReduceFunc: ExampleURLCountReduce,NReduce: nWorkers,})// round 2: sort and get the 10 most frequent URLsargs = append(args, RoundArgs{MapFunc: ExampleURLTop10Map,ReduceFunc: ExampleURLTop10Reduce,NReduce: 1,})return args
}// ExampleURLCountMap is the map function in the first round
func ExampleURLCountMap(filename string, contents string) []KeyValue {lines := strings.Split(contents, "\n")kvs := make([]KeyValue, 0, len(lines))for _, l := range lines {l = strings.TrimSpace(l)if len(l) == 0 {continue}kvs = append(kvs, KeyValue{Key: l})}return kvs
}// ExampleURLCountReduce is the reduce function in the first round
func ExampleURLCountReduce(key string, values []string) string {return fmt.Sprintf("%s %s\n", key, strconv.Itoa(len(values)))
}// ExampleURLTop10Map is the map function in the second round
func ExampleURLTop10Map(filename string, contents string) []KeyValue {lines := strings.Split(contents, "\n")kvs := make([]KeyValue, 0, len(lines))for _, l := range lines {kvs = append(kvs, KeyValue{"", l})}return kvs
}// ExampleURLTop10Reduce is the reduce function in the second round
func ExampleURLTop10Reduce(key string, values []string) string {cnts := make(map[string]int, len(values))for _, v := range values {v := strings.TrimSpace(v)if len(v) == 0 {continue}tmp := strings.Split(v, " ")n, err := strconv.Atoi(tmp[1])if err != nil {panic(err)}cnts[tmp[0]] = n}us, cs := TopN(cnts, 10)buf := new(bytes.Buffer)for i := range us {fmt.Fprintf(buf, "%s: %d\n", us[i], cs[i])}return buf.String()
}示例中的Map-Reduce函数共两轮,第一轮作计数,第二轮作排序同时作Top10的过滤
通过分析,我认为实现找到 10 个出现频率最高的 URL 这个需求还是逃不开计数、排序、Top10过滤这三个步骤。
虽然总体思路还是和示例函数一样,但是我在实现细节上作了一些优化:
- 在第一轮Map时合并相同的key(即在做分词的同时再做计数),以此减少传输I/O
- 在第一轮Reduce时,不再简单地直接进行输出,而是对特定的key的频率做累加求和
- 在第二轮Map时,做排序和Top10过滤,只输出本次Map频率前十的URL(不再输出所有URL),以此减少传输I/O
第二轮Reduce与示例函数一致,做最终的Top10查找
整体代码如下:
// K Top K
const K = 10// URLTop10 .
func URLTop10(nWorkers int) RoundsArgs {// YOUR CODE HERE :)// And don't forget to document your idea.var args RoundsArgs// round 1: both map phase and reduce phase do the url countargs = append(args, RoundArgs{MapFunc: URLTop10CountMap,ReduceFunc: URLTop10CountReduce,NReduce: nWorkers,})// round 2: both map phase and reduce do sort and topK filterargs = append(args, RoundArgs{MapFunc: URLTop10SortFilterMap,ReduceFunc: URLTop10SortFilterReduce,NReduce: 1,})return args
}// URLTop10CountMap count url and combine same key to reduce IO
func URLTop10CountMap(filename string, contents string) []KeyValue {lines := strings.Split(contents, "\n")kvMap := make(map[string]int)for _, url := range lines {url = strings.TrimSpace(url)if len(url) == 0 {continue}if _, exist := kvMap[url]; !exist {kvMap[url] = 0}kvMap[url] = kvMap[url] + 1}kvs := make([]KeyValue, 0)for k, v := range kvMap {kvs = append(kvs,KeyValue{Key: k,Value: strconv.Itoa(v)})}return kvs
}// URLTop10CountReduce calculate key's total count
func URLTop10CountReduce(key string, values []string) string {count := 0for _, v := range values {vInt, err := strconv.Atoi(v)if err != nil{panic(err)}count += vInt}return fmt.Sprintf("%s: %d\n", key, count)
}// URLTop10SortFilterMap do sort and topK filter
func URLTop10SortFilterMap(filename string, contents string) []KeyValue {lines := strings.Split(contents, "\n")cnts := make(map[string]int)for _, v := range lines {v := strings.TrimSpace(v)if len(v) == 0 {continue}tmp := strings.Split(v, ": ")n, err := strconv.Atoi(tmp[1])if err != nil {panic(err)}cnts[tmp[0]] = n}us, cs := TopN(cnts, K)kvs := make([]KeyValue, 0, K)for i := range us {kvs = append(kvs,KeyValue{Key:"",Value: fmt.Sprintf("%s: %d",us[i],cs[i])})}return kvs
}// URLTop10SortFilterReduce do sort and topK filter
func URLTop10SortFilterReduce(key string, values []string) string {kvMap := make(map[string]int, len(values))for _, value := range values {tmp := strings.Split(value, ": ")url := strings.TrimSpace(tmp[0])if len(url) == 0 {continue}n, err := strconv.Atoi(tmp[1])if err != nil {panic(err)}if _, exist := kvMap[url]; !exist {kvMap[url] = 0}kvMap[url] = kvMap[url] + n}us, cs := TopN(kvMap, K)buf := new(bytes.Buffer)for i := range us {fmt.Fprintf(buf, "%s: %d\n", us[i], cs[i])}return buf.String()
}由于Map和Reduce函数都不是I/O密集型,所以第一轮NReduce参数仍使用nWorkers
通过上面对测试函数的分析(最终输出结果的文件列表应该只有一个文件),第二轮NReduce参数保持为1
执行
make test_homework > ./log/test_homework.log进行测试,同时将测试结果重定向输出到test_homework.log,测试结果如下:
go test -v -timeout 60m -run=TestURLTop
=== RUN TestURLTop
Case0 PASS, dataSize=1MB, nMapFiles=5, cost=25.0578ms
Case1 PASS, dataSize=1MB, nMapFiles=5, cost=29.6926ms
Case2 PASS, dataSize=1MB, nMapFiles=5, cost=282.7606ms
Case3 PASS, dataSize=1MB, nMapFiles=5, cost=77.0294ms
Case4 PASS, dataSize=1MB, nMapFiles=5, cost=38.2195ms
Case5 PASS, dataSize=1MB, nMapFiles=5, cost=185.0714ms
Case6 PASS, dataSize=1MB, nMapFiles=5, cost=30.1719ms
Case7 PASS, dataSize=1MB, nMapFiles=5, cost=30.1969ms
Case8 PASS, dataSize=1MB, nMapFiles=5, cost=94.7232ms
Case9 PASS, dataSize=1MB, nMapFiles=5, cost=28.062ms
Case10 PASS, dataSize=1MB, nMapFiles=5, cost=20.1835ms
Case0 PASS, dataSize=10MB, nMapFiles=10, cost=40.7678ms
Case1 PASS, dataSize=10MB, nMapFiles=10, cost=47.6344ms
Case2 PASS, dataSize=10MB, nMapFiles=10, cost=54.7339ms
Case3 PASS, dataSize=10MB, nMapFiles=10, cost=77.6767ms
Case4 PASS, dataSize=10MB, nMapFiles=10, cost=261.5726ms
Case5 PASS, dataSize=10MB, nMapFiles=10, cost=310.2633ms
Case6 PASS, dataSize=10MB, nMapFiles=10, cost=44.0939ms
Case7 PASS, dataSize=10MB, nMapFiles=10, cost=50.4649ms
Case8 PASS, dataSize=10MB, nMapFiles=10, cost=50.4096ms
Case9 PASS, dataSize=10MB, nMapFiles=10, cost=58.3175ms
Case10 PASS, dataSize=10MB, nMapFiles=10, cost=45.2759ms
Case0 PASS, dataSize=100MB, nMapFiles=20, cost=146.0478ms
Case1 PASS, dataSize=100MB, nMapFiles=20, cost=544.0832ms
Case2 PASS, dataSize=100MB, nMapFiles=20, cost=235.3012ms
Case3 PASS, dataSize=100MB, nMapFiles=20, cost=1.4182167s
Case4 PASS, dataSize=100MB, nMapFiles=20, cost=1.6650558s
Case5 PASS, dataSize=100MB, nMapFiles=20, cost=315.7017ms
Case6 PASS, dataSize=100MB, nMapFiles=20, cost=153.0375ms
Case7 PASS, dataSize=100MB, nMapFiles=20, cost=161.2142ms
Case8 PASS, dataSize=100MB, nMapFiles=20, cost=3.6473142s
Case9 PASS, dataSize=100MB, nMapFiles=20, cost=201.0136ms
Case10 PASS, dataSize=100MB, nMapFiles=20, cost=382.0689ms
Case0 PASS, dataSize=500MB, nMapFiles=40, cost=3.9562808s
Case1 PASS, dataSize=500MB, nMapFiles=40, cost=8.7393114s
Case2 PASS, dataSize=500MB, nMapFiles=40, cost=2.5093273s
Case3 PASS, dataSize=500MB, nMapFiles=40, cost=4.3728053s
Case4 PASS, dataSize=500MB, nMapFiles=40, cost=7.8807145s
Case5 PASS, dataSize=500MB, nMapFiles=40, cost=4.0481183s
Case6 PASS, dataSize=500MB, nMapFiles=40, cost=5.6082772s
Case7 PASS, dataSize=500MB, nMapFiles=40, cost=3.2234075s
Case8 PASS, dataSize=500MB, nMapFiles=40, cost=2.1543608s
Case9 PASS, dataSize=500MB, nMapFiles=40, cost=3.4617415s
Case10 PASS, dataSize=500MB, nMapFiles=40, cost=534.848ms
Case0 PASS, dataSize=1GB, nMapFiles=60, cost=9.7468331s
Case1 PASS, dataSize=1GB, nMapFiles=60, cost=8.9736291s
Case2 PASS, dataSize=1GB, nMapFiles=60, cost=7.1103251s
Case3 PASS, dataSize=1GB, nMapFiles=60, cost=12.0123006s
Case4 PASS, dataSize=1GB, nMapFiles=60, cost=17.6703582s
Case5 PASS, dataSize=1GB, nMapFiles=60, cost=6.1326302s
Case6 PASS, dataSize=1GB, nMapFiles=60, cost=8.0123164s
Case7 PASS, dataSize=1GB, nMapFiles=60, cost=9.4003026s
Case8 PASS, dataSize=1GB, nMapFiles=60, cost=6.8128708s
Case9 PASS, dataSize=1GB, nMapFiles=60, cost=5.1652438s
Case10 PASS, dataSize=1GB, nMapFiles=60, cost=9.4698508s
--- PASS: TestURLTop (275.26s)
PASS
ok talent 275.546s
测试通过,总耗时为:275.546s,比示例Map-Reduce函数速度提升了约3倍
至此lab0的任务二完成
至此lab0完成
完成后的代码已开源在:GitHub - Morgan279/vldbss-2021
总结
与课程预期一致,通过这次lab,我学习到了一些 Golang 的基础知识并对分布式系统有了一个基础的了解。之前我从没有学过go语言,这次lab中Map-Reduce框架的go语言实现提供了一个非常好的go语言编码示例,通过对里面代码的模仿学习,加快了我对go语言的上手速度和对go语言的理解。
这次通过亲手实现了一个简单的Map-Reduce框架,同时利用lab中提供的测试函数来很方便地测试实现的正确性,形成了一个动手到反馈的闭环,让我对分布式系统有了比以往更深入地一个理解,最后感谢主办方对这次lab的精心设计。