来源:专知
本文为教程介绍,建议阅读5分钟最近的研究工作通过开发表格数据的神经表示扩展了语言模型。
在过去的几年中,自然语言处理界见证了基于transformer的语言模型(LM)在自由文本的神经表示方面的进展。鉴于关系表中可用知识的重要性,最近的研究工作通过开发表格数据的神经表示扩展了语言模型。在本教程中,我们提出这些建议有两个主要目标。首先,我们向数据库观众介绍当前模型的潜力和局限性。其次,我们将演示从transformer体系结构中受益的大量数据应用程序。本教程旨在鼓励数据库研究人员参与并为这个新方向做出贡献,并为实践者提供一组用于涉及文本和表格数据的应用程序的新工具。
一些工作正在研究如何用神经模型表示表格数据,用于自然语言处理(NLP)和数据库(DB)的应用。这些模型支持有效的解决方案,超越了围绕一阶逻辑和SQL构建的传统声明性规范的限制。示例包括回答用自然语言表达的查询[16,19,31],执行自然语言推理,如事实核查[7,18,35],语义解析[36,37],检索相关表[20,25,33],理解表元数据[8,11,29],数据集成[6,22],数据到文本生成[32]和数据imputation[8,17]。由于这些应用程序既涉及结构化数据又涉及自然语言,因此它们构建在新的数据表示和架构之上,这些数据表示和架构超越了传统的DB方法。
https://vldb.org/2022/?program-schedule-tutorials
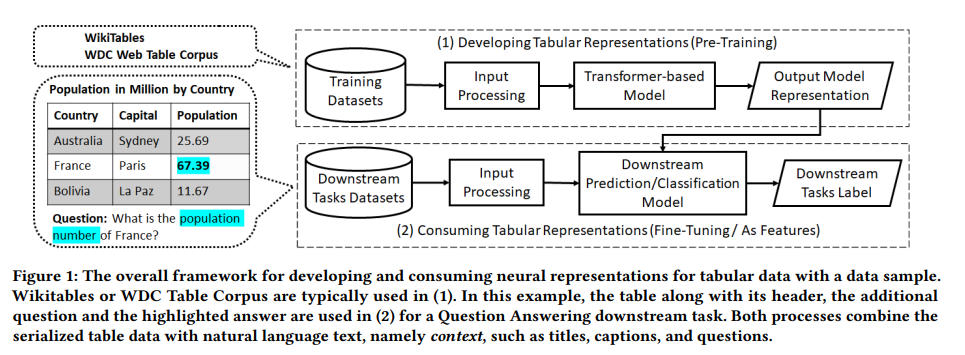
神经的方法。基于注意力机制的transformer模型已被成功用于开发预训练语言模型(LMs),如BERT[9]、RoBERTa[24]。与传统技术相比,这些LMs在目标文本任务(如情感分析)中取得了惊人的效果,使NLP领域发生了革命性的变化[2,3]。然而,transformer已被证明能够超越文本,并已成功地用于视觉[10]和音频[14]数据。遵循这一趋势,transformer在开发表格数据表示方法方面开始受到欢迎。本教程关注渲染transformer架构的核心问题“数据结构感知”,并将设计选择和对大量下游任务的贡献联系起来。与会者可以了解根据目标应用程序使用transformer的不同方式。的例子。当采用基于transformer的方法时,选择范围从采用现有的预训练模型(从数百万表中创建)到从头开始构建解决方案。作为transformer架构的一个例子,请考虑图1。使用顶层管道创建语言模型(1)。例如,在BERT[9]中,通过自监督任务处理大量文档语料库,以创建模型,然后用于构建以文本为中心的应用程序。模型的创建是昂贵的,但是任何有在线Python笔记本的从业者都可以使用最终的模型。构建应用程序最流行的方法是使用少量的特定示例(例如,文档分类或情感分析)对这种模型进行微调。这在底层管道(2)中得到了描述。从文本数据转移到表格数据,一些方法使用了一个表的语料库来创建一个预先训练的模型,它“理解”表格格式(1)。目标应用程序现在可以使用这个模型来处理下游任务(2)。在(1)和(2)中,表首先被序列化并连接到其内容,以将其作为输入提供给变压器。例如,在(1)中,训练数据可以是从维基百科中提取的大量表的语料库。(2)是使用预训练的模型直接回答用自然语言对给定表表示的查询。示例的输入是一个表,以及它的标题“以百万计的国家人口”作为上下文,以及关于法国人口的问题。期望的输出是给定表中突出显示的单元格。当预训练模型不足以满足任务时,可以用少量示例进行微调(2)。在某些情况下,模型是从头开始进行预训练的(1),以利用对典型transformer架构的新扩展,以考虑表格结构,这与传统的自由文本不同,有时更丰富。