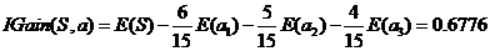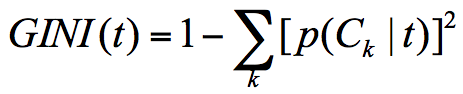决策树-ID3实例
参考书籍:
《机器学习》周志华,第1版
《统计学习方法》李航,第2版
用来记录自己对书中知识的理解,加强自己的理解和记忆,同时提出自己迷惑不解的地方,提高自己编辑的表达能力。
代码参考博客:https://blog.csdn.net/weixin_43084928/article/details/82455326?
https://blog.csdn.net/laojie4124/article/details/92018932?
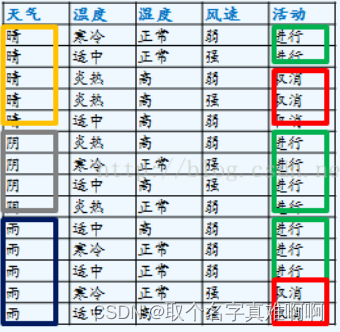
数据集:
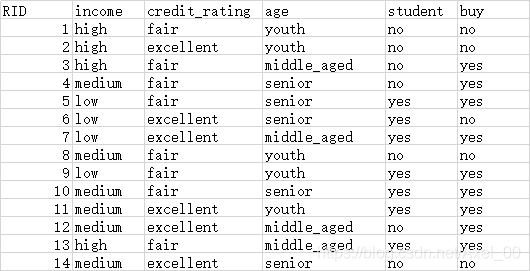
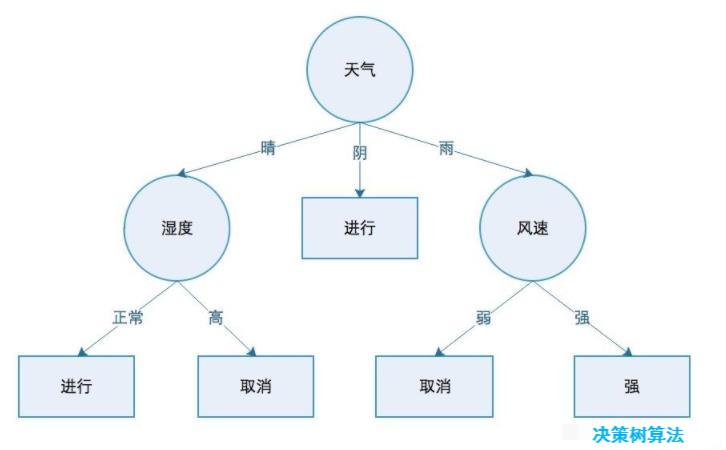
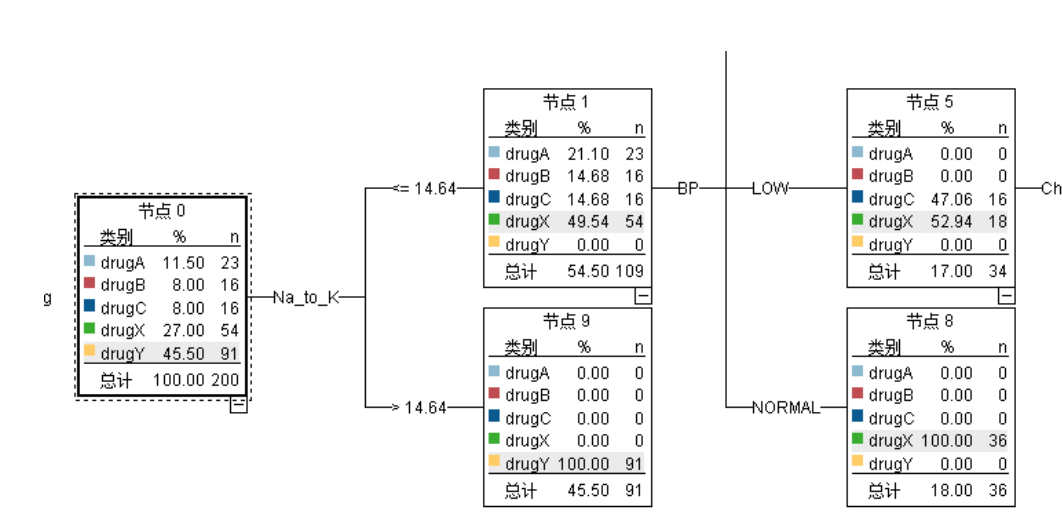
ID3是通过计算信息增益来选择分类特征
后面会在此基础上通过graphviz模块打印输出决策树,并增加C4.5算法,预剪枝和后剪枝
结合数据集,具体的算法流程:
1)计算分类的信息熵:buy
# 计算分类特征的信息熵,数据集是最后一列,买或者不买,并返回信息熵
def calEnt(dataset):# 获取数据集的维度,有多少行数据n = dataset.shape[0]# 每一列有哪些数据,数量是多少columns_set = dataset.iloc[:,-1].value_counts()# 每种数据占总数量的比重p = columns_set / n # print('p:',p)# 信息熵ent = (-p*np.log2(p)).sum()return ent
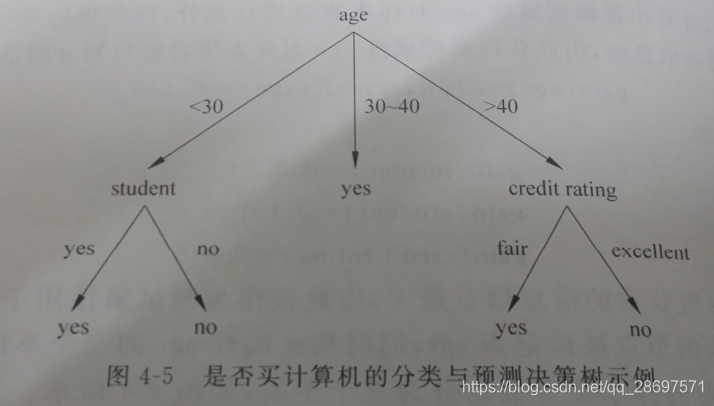
2)计算4个特征的信息熵:income,credit_rating,age,student,这个完全根据数学计算步骤来来处理的。
计算信息增益最高的特征,并返回,以便选择节点:
def best_split(dataset):base_ent = calEnt(dataset)best_Gain = 0 #计算分类信息熵axis = 0 #初始化标签列,最优列gain = []for i in range(1,dataset.shape[1]-1):levels = dataset.iloc[:,i].value_counts() #获取每一行的数据dict_levels = dict(levels)# print('levels:\n',dict_levels)ents = 0 #初始化信息熵for j in dict_levels.keys():# print('j:',j)child_set = dataset[dataset.iloc[:,i] == j]child_ent = calEnt(child_set)ents += (child_set.shape[0]/dataset.shape[0])*child_ent# print('ents:',ents)infogain = base_ent - entsgain.append(infogain)# print('infogain:',infogain)if infogain > best_Gain:best_Gain = infogainaxis = ireturn axis
3)创建决策树,用的是字典结构
def get_feature_2(dataset):# 返回特征值列表feature_list = list(dataset.columns)return feature_list
def sub_Split(dataset,axis,value):# 根据信息增益最高坐标返回特征值col = dataset.columns[axis]# drop()删除某一行或列,axis = 0 表示行,axis = 1表示列# 获取value值所在行,然后将col列删除redataset = dataset.loc[dataset[col]==value,:].drop(col,axis=1)return redataset
def create_tree(dataset):# 获得特征列表feature_list = get_feature_2(dataset)# print(feature_list)# 获得分类值,例如yes和noclass_list = dataset.iloc[:,-1].value_counts()# 判断目前这个数据集是否都是一类,或者数据集只有一个特征if class_list[0]==dataset.shape[0] or dataset.shape[1] == 1:# print('class_list的索引:',class_list.index[0])#如果是,返回类标签return class_list.index[0]# 第一次寻找所有特征中信息增益最高的那个特征的坐标,1-4中任意一个,第一个是RID,最后一个分类标签best_ent_axis = best_split(dataset)best_ent_feature = feature_list[best_ent_axis]# print(best_ent_feature)# 采用字典嵌套来存储树信息class_tree = {best_ent_feature:{}}# print(class_tree)# 从特征列表中删除信息增益最高的特征del feature_list[best_ent_axis]# print(feature_list)# 提取信息增益最高特征的数据value_list = set(dataset.iloc[:,best_ent_axis])# print(value_list)# 对每一个特征值递归建树,例如age:youth,middle_age,seniorfor value in value_list:class_tree[best_ent_feature][value] = create_tree(sub_Split(dataset,best_ent_axis,value))# print("生成的树:",class_tree)return class_tree
5)分类,递归调用,对训练集进行判断
# 分类判断
def classify(input_tree,labels,test_vec):# 获取决策树的根节点first_str = next(iter(input_tree))seconde_dict = input_tree[first_str]# 第一个节点所在的索引feature_index = labels.index(first_str)for key in seconde_dict.keys():# print('key:',key)# 如果测试数据的索引键值和根结点的键值一样if test_vec[feature_index] == key:# 如果子结点是一个字典,就继续分类,否则就是一个叶子结点if type(seconde_dict[key]) == dict :# 递归分类class_label = classify(seconde_dict[key], labels, test_vec)else:class_label = seconde_dict[key]return class_label
6)计算测试数据集在训练好的决策树的精度
# 测试精度
def acc_classify(train_dataset,test_dataset):# 根据训练数据得到决策树input_tree = create_tree(train_dataset)labels = list(train_dataset.columns)results = []for i in range(test_dataset.shape[0]):test_vec = train_dataset.iloc[i,:-1]class_label = classify(input_tree,labels,test_vec)results.append(class_label)# 在数据集增加一列predict,将预测出来的分类保存在这一列test_dataset['predict'] = resultsacc = (test_dataset.iloc[:,-1] == test_dataset.iloc[:,-2]).mean()print('测试的精度:')print(acc)
前面需要导入用的模块:
import csv
from sklearn.feature_extraction import DictVectorizer #用来转换数据
from sklearn import preprocessing
import pandas as pd
import numpy as np
调用写好的函数,得到结果,由于用的训练数据和测试数据是一个,所以这个精度不准,但是整个流程是没问题的:
file_path = 'E:\\arithmetic_practice\\tree.csv'
dataset = pd.read_csv(file_path)
dataset = pd.DataFrame(dataset)
train_dataset = dataset
test_dataset = dataset
acc_classify(train_dataset, test_dataset)