任务描述:如题,以2010年月尺度1km的MODIS的植被覆盖度(NDVI)数据为例
第一步 :获得MODIS数据下载链接
Earthdata Search(下载地址)
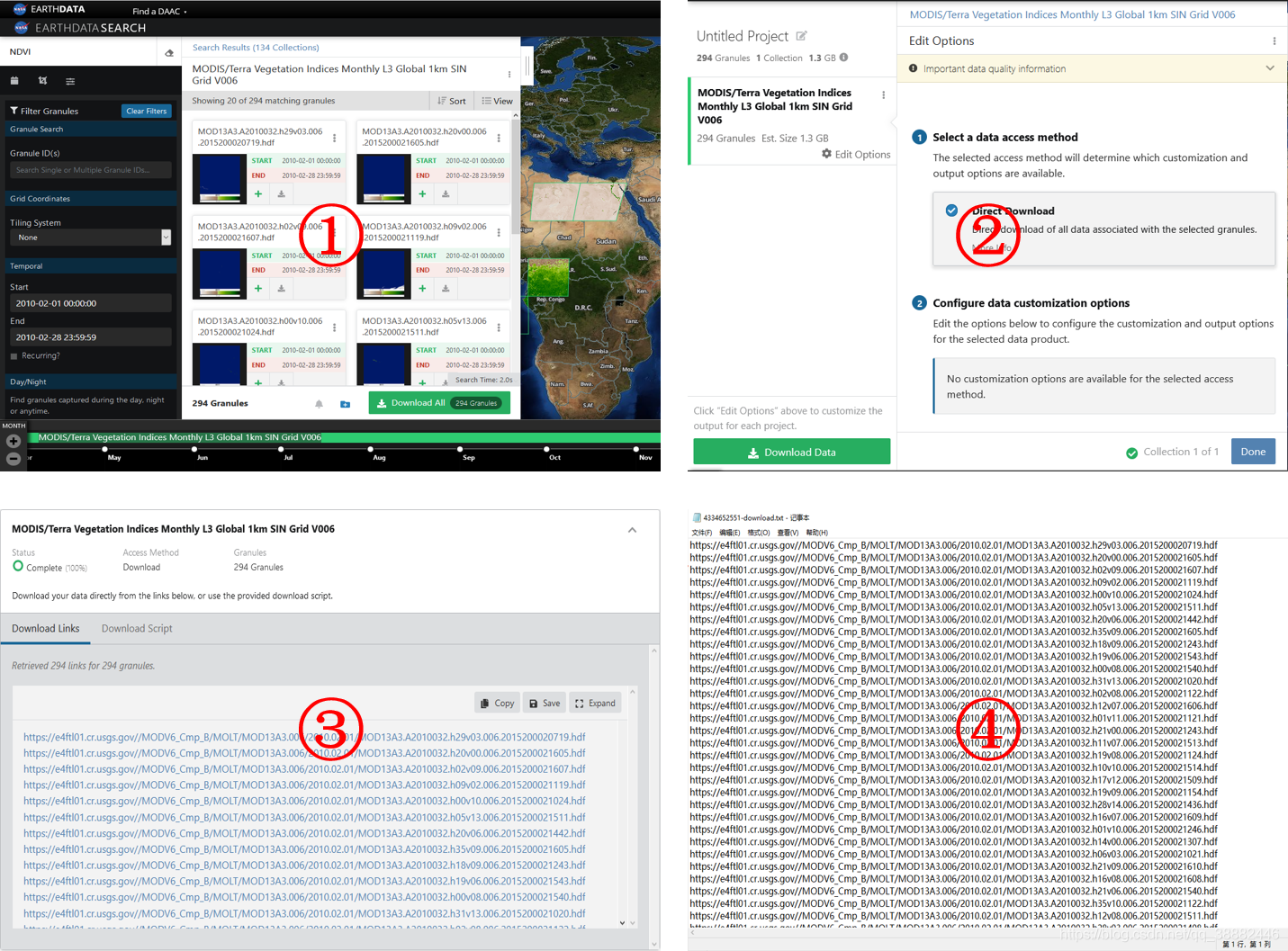 可以选择自己想要的时间空间范围,NASA官网会自动生成下载链接,点击保存得到txt文件
可以选择自己想要的时间空间范围,NASA官网会自动生成下载链接,点击保存得到txt文件
第二步:下载数据(使用MATLAB)
那么如何根据Txt文件中的url链接下载数据呢?
%% 代码用于下载MODIS NDVI月尺度数据,全部存在默认文件夹中,需要将系统默认浏览器设置为Chrome,存储路径在浏览器中修改clc
clear
close allurl_total = textread('C:\Users\DELL\Downloads\NDVI201002.txt','%s'); %NDVI201002.txt 是我重命名的MODIS下载链接文件
for i = 1:length(url_total) url = url_total{i};web(url,'-browser')disp([num2str(i),'/',num2str(length(url_total))])%设置5秒的时间间隔,避免过于密集地打开T = clock;t1 = T(6);while 1T = clock;t2 = T(6);if abs(t2 - t1)>5break;endend
end
第三步:数据分类(使用MATLAB)
此时MODIS的数据全部被下载在一个文件夹中了,我们需要根据文件名进行分类,把同一个月的数据放在同一个文件夹下,方便后续的操作
clc
clear%% 根据文件名进行分类
datadir = 'C:\Users\DELL\Downloads\'; %指定hdf文件所在位置
filelist = dir([datadir,'*.hdf']); %指定文件类型
k = length(filelist);
time_standard = {'001','032','060','091','121','152','182','213','244','274','305','335'};...%MODIS官网文件命名规则,例如'032'指的是第二个月
for i = 1:khdfFilePath = ['C:\Users\DELL\Downloads\',filelist(i).name]; %依次读取文件time_num = filelist(i).name(14:16); %记录序列编号[~,b] =ismember(time_num,time_standard); %根据文件名判断属于第几个月if b < 10movefile(hdfFilePath, ['F:\MODIS_NDVI_Monthly_1km_v006\hdf\20100',num2str(b),'\',filelist(i).name])elsemovefile(hdfFilePath, ['F:\MODIS_NDVI_Monthly_1km_v006\hdf\2010',num2str(b),'\',filelist(i).name])end
end
这样我们的文件就分类存储在不同文件夹下了,例如’032’的文件全在201002文件夹下:
第四步:数据转换(hdf→tif,使用python)
此时的文件还是hdf,需要转换为tif文件进行拼接操作
此处转换代码来自:python_MODIS HDF数据转为tif并拼接图像
做了一些修改,增加了批量转换功能:
# -*- coding:utf-8 -*-
'''
用于将NDVI的hdf文件转为tif
'''
import os
import arcpy
from arcpy import env
time_mon = ['01','02','03','04','05','06','07','08','09','10','11','12']
for i in range(0,12):# print(i)sourceDir=(u'F:\\MODIS_NDVI_Monthly_1km_v006\\hdf\\2010'+time_mon[i]+'\\') #输入targetDir=(u'F:\\MODIS_NDVI_Monthly_1km_v006\\tif\\2010'+time_mon[i]) #输出arcpy.CheckOutExtension("Spatial")env.workspace = sourceDirarcpy.env.scratchWorkspace = sourceDirhdfList = arcpy.ListRasters('*','hdf')for hdf in hdfList:print hdfeviName=os.path.basename(hdf).replace('hdf','tif')outname=targetDir+'\\'+eviNameprint outnamedata1=arcpy.ExtractSubDataset_management(hdf,outname, "MOD_Grid_monthly_1km_VI") #MOD_Grid_monthly_1km_VI是子数据集名称
print 'all done'
第五步:图像拼接(使用python)
将200多个小图像拼接成全球分布图
代码来自ArcPy镶嵌至新栅格(MosaicToNewRaster)
做了一些修改,添加了批量拼接的功能
# -*- coding: utf-8 -*-
"""
Created on Wed Jan 20 20:20:39 2021
@author: Administrator
"""# -*- coding: utf-8 -*-import arcpy
from arcpy import env
from arcpy.sa import *time_mon = ['01','02','03','04','05','06','07','08','09','10','11','12']
for i in range(0,12):# 定义工作区env.workspace = ('F:\\MODIS_NDVI_Monthly_1km_v006\\tif\\2010'+time_mon[i]+'\\')# 裁剪后文件输出的文件夹outputpath= "F:\\MODIS_NDVI_Monthly_1km_v006\\tif"# 读取工作区中的所有的栅格文件rasters = arcpy.ListRasters("*", "tif")mosaic_rasters=""for raster in rasters:mosaic_rasters=mosaic_rasters+raster+";"print(mosaic_rasters)arcpy.CheckOutExtension("Spatial")arcpy.MosaicToNewRaster_management(mosaic_rasters,outputpath, ('2010'+time_mon[i]+'.tif'), "","16_BIT_SIGNED", "", "1", "","")print('finish')
关于拼接命令arcpy.MosaicToNewRaster_management,建议详细读一下镶嵌至新栅格,不同子栅格之间是用分号隔开的
得到最后成果图:
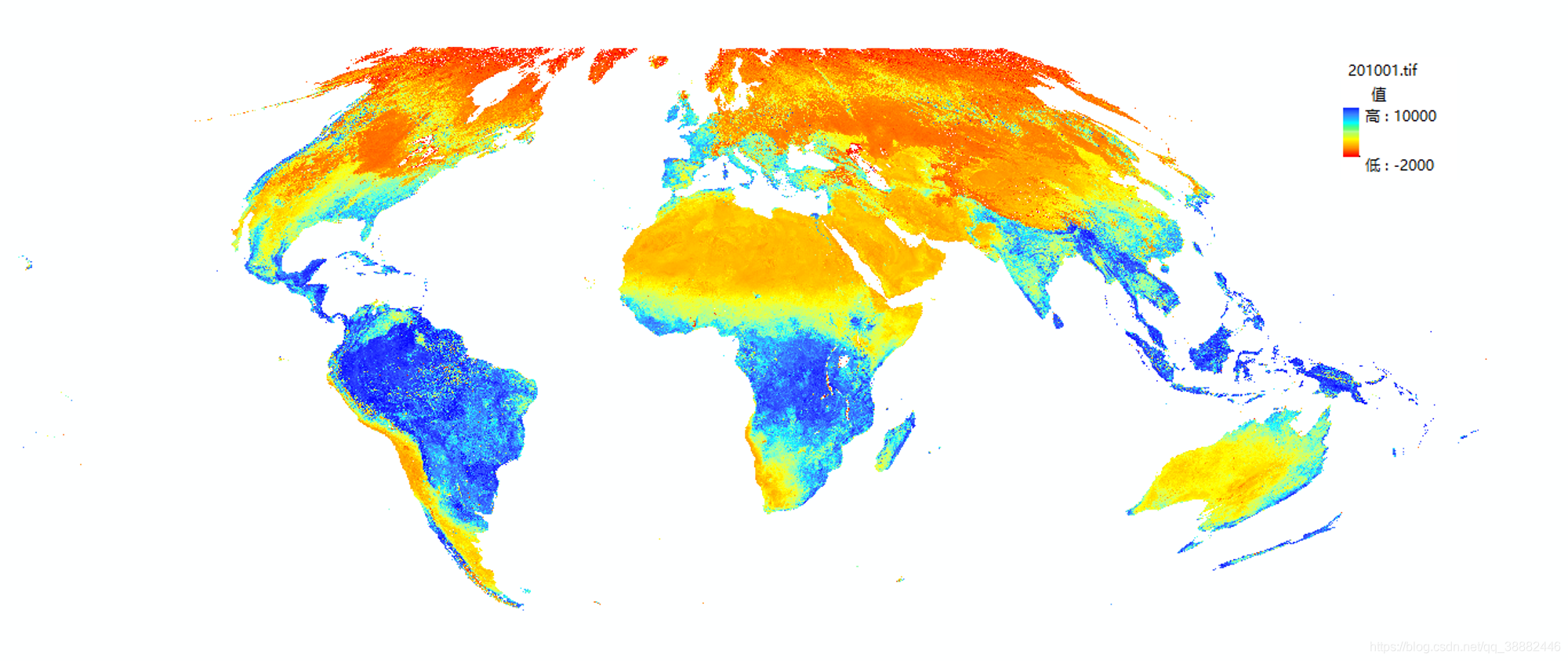 Finish!
Finish!