参考资料:《深入理解Kafka核心设计与实践原理》、《尚硅谷2022版Kafka3.x教程》
Kafka生产者发送流程详解
- 序列化器
- 分区策略
- 如何将一些相关连的数据放进同一张表里?
- 自定义分区
- 生产者拦截器
Kafka生产者发送流程详解大致流程如下:
整个生产者客户端由两个线程协调运行,这两个线程分别是main线程和Sender线程。在主线程中由KafkaProducer创建消息,然后通过可能的拦截器、序列化器和分区器的作用后缓存到消息累加器(RecordAccumlator,也称为消息收集器)中。Sender线程负载从RecordAccumulator中获取消息并将其发送到Kafka集群中。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DFzWMnjW-1660649642553)(D:\note\笔记仓库\图片\image-20220815125151314.png)]](https://img-blog.csdnimg.cn/4d94a3885d9043839fd3194598307fb0.png)
-
main线程:在客户端将数据放入双端队列里
-
Sender线程:从队列里读取数据发送到kafka集群
Sender从RecordAccumulator获取到缓存的消息之后,会将原本==<分区,Deque<ProducerBath>>的保存形式转化为<Node,List<ProducerBatch>>==的形式。
其中Node表示的就是kafka集群中的broker节点
在转换成<Node,List<ProducerBatch>>之后,Sender还会进一步封装成==<Node,Request>==的形式,这样就可以将Request请求发往各个Node之中
-
DQueue:双端队列,每个分区对应一个双端队列。队列中的内容就是ProducerBatch,即DQueue<ProducerBatch>,写入缓存时放入尾部,Sender读取消息时从头部读取。****
-
batch.size:只有数据积累到batch.size之后,sender才会取数据发送,默认大小为16k
消息在网络上都是以字节来传输,在发送之前需要创建一块内存区域来保存消息。
在Kafka生产者客户端,通过java.io.ByteBuffer来实现消息内存创建和释放,为了解约创建和释放的消耗。在RecordAccumulator由一个==BufferPool==来实现ByteBuffer的复用,以实现缓存的高效利用。
BufferPool的大小就由batch.size参数决定
-
linger.ms:如果数据迟迟没有到达batch.size,那么sender线程在等待linger.ms设置的实践到达后就会取数据发送。(默认是0,表示没有延迟)
-
ProducerBatch:就是一个消息批次,包含很多ProducerRecord
ProducerBatch与batch.size参数有关系,当消息放入双端队列中时,会从队列尾部获取一个ProducerBatch,查询是否可以将当前消息写入ProducerBatch
-
如果可以就不需要新建ProducerBatch。
-
否则新建ProducerBatch时也需要评估这条消息的大小是否超过batch.size,
如果不超过,那么就以batch.size大小创建ProducerBatch,并且使用完后,还可以通过BUfferPool进行管理复用。
如果超过,就以原始大小来创建ProducerBatch,并且不会复用,使用完就释放掉这段内存
-
-
RecordAccumulator主要用来缓存消息以便 Sender 线程可以批量发送,进而==减少网络传输的资源消耗以提升性能。==可通过生产者客户端参数buffer.memory配置,默认大小为32M。
如果生产者速度大于消费者速度,则会导致生产者空间不足,这时候调用send()方法要么阻塞,要么抛出异常。由参数max.block.ms配置,默认为60s。
-
InFlightRequests:缓存已经发出去但还没有收到响应的请求
请求从Sender线程发往至Kafka集群之前还会保存到InFlightRequests中,其中保存的具体形式为Map<NodeId,Deque<Request>>。
InFlightRequests可以通过配置参数来限制缓存的broker的连接数(客户端和Node之间的连接),默认为5.
InFlightRequests还可以决定**leastLoadedNode(当前在InFlightRequests中负载最小的node),发送请求时会优先发送leastLoadedNode**
-
元数据信息:
元数据信息值的就是kafka集群中某个主题的分区数、副本数、leader副本所在的节点这些信息。
在发送消息之前,我们必须要得知这些信息后才能够正常发送消息。
当客户端没有指明需要使用的元数据信息时或者超过metadata.max.age.ms(默认5分钟)时间没有更新元数据都会引起元数据的更新操作,就会从InFlightRequests中选出**leastLoadedNode,然后向这个Node发送MetadataRequest**请求来获取元数据信息。
-
-
retries:重试次数,可自行配置
-
响应acks:kafka集群收到消息后的响应,用于决定发送端是否重试。
-
0:生产者发送到服务端即可,不需要等待应答
如果发送过程由于网络等原因发送失败,或者服务端接收后突然宕机都会导致丢数问题
-
1:leader副本收到即可(常常用于记录日志使用)
应答完成后,leader还未进行同步就挂了,那么其它选举出来的leader就没有这条数据,也会导致丢数问题
-
-1:ISR队列里的所有节点都收到消息后返回(支付相关的场景使用)
副本数大于2的情况下能够保证数据可靠(高水位)。如果副本数为1,那么就和ack=1的场景一样,也可能会导致丢数
-
序列化器
为什么不用Java的序列化器?
Java序列化器太重,会增加额外的数据来保证安全传输。在大数据场景下,一般不会使用java原生的序列化器。
生产者需要用序列化器(Serializer)把对象转换成字节数组才能通过网络发送给Kafka。而在对侧, 消费者需要用反序列化器(Deserializer)把从Kafka中收到的字节数组转换成相应的对象。
综上所述:生产者和消费者的序列化器必须是相同的,否则可能就会出现乱码的情况
下面是kafka的序列化接口的官方定义:表明了必须将我们发送的消息转化为字节数组
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DBg9hM3y-1660649642556)(D:\note\笔记仓库\图片\image-20220816162100522.png)]](https://img-blog.csdnimg.cn/17d3cd3603aa4e9892fa5433d39c33da.png)
下面是kafka的序列化接口的定义:
public interface Serializer<T> extends Closeable {/*** 配置这个类。* @param 键/值对中的配置* @param 是键还是值*/void configure(Map<String, ?> configs, boolean isKey);/*** 将data转换为字节数组。** @param topic 与数据相关的主题* @param data 输入数据* @return 序列化字节*/byte[] serialize(String topic, T data);/*** 关闭此序列化程序。此方法必须是幂等的,因为它可能会被多次调用。*/@Overridevoid close();
}
总的来说:
- configure()方法用来配置当前类
- serialize()方法用来执行序列化操作
- close()方法用来关 闭当前的序列化器:一般情况下close()是一个空方法, 如果实现了此方法, 则必须确保此方法的幕等性, 因为这个方法很可能会被KafkaProducer调用多次
下面来看一下StringSerializer的代码实现:
/*** String encoding defaults to UTF8 and can be customized by setting the property * value.serializer.encoding or serializer.encoding. The first two take precedence over the last.*/
public class StringSerializer implements Serializer<String> {private String encoding = "UTF8";@Overridepublic void configure(Map<String, ?> configs, boolean isKey) {String propertyName = isKey ? "key.serializer.encoding" : "value.serializer.encoding";Object encodingValue = configs.get(propertyName);if (encodingValue == null)encodingValue = configs.get("serializer.encoding");if (encodingValue instanceof String)encoding = (String) encodingValue;}@Overridepublic byte[] serialize(String topic, String data) {try {if (data == null)return null;elsereturn data.getBytes(encoding);} catch (UnsupportedEncodingException e) {throw new SerializationException("Error when serializing string to byte[] due to unsupported encoding " + encoding);}}@Overridepublic void close() {// nothing to do}
}
- 首先对于configure()方法,这个方法是在创建KafkaProducer实例的时候调用,用于确定编码类型。(一般情况下我们不会配置,所以默认就是UTF-8)
- serialize()方法就很直观,将String类型转化为byte[]类型
分区策略
分区好处:
- 便于合理的使用存储资源,各个分区存储在不同的broker节点上,合理控制分区的任务,可以实现负载均衡的效果,并提高可存储数据量‘
- 提高了并行度,不同的消费者可以同时消费不同分区上的数据(这里要注意的是,一个分区只能由一个消费者消费)
kafka的几种分区策略:
主要是由在构造ProducerRecord对象的时候,有没有指定partition、key决定
- 指明partition:如果在创建ProducerRecord的时候,声明了分区号partition,那么就存储到这个分区中去
- 指明Key,未指明partition:将key的hash值与topic的分区数取余得到最终的partition值
- 即没有key,也没有partition:kafka会采用默认的RoundRobin轮询分配,首先随机选择一个分区存储(并尽可能一直使用该分区),直到分区存储满时或者已完成,再去随机选择下一个分区使用(和上一次的分区不同)。
在不改变主题分区数量的情况下 key 与分区之间的映射可保持不变。不过, 一旦主题中增加了分区,那么就难以保证 key 与分区之间的映射关系了。
如何将一些相关连的数据放进同一张表里?
将表名字作为key传进去(它会通过hash算法得到一个相同的值),存入指定的分区。消费者能够将对应分区的数据放进一个表里
自定义分区
实现Partitioner接口,重写方法即可,返回对应的分区值。还需要再主程序关联我们自定义的分区(在Properties中声明),不然它会走默认的分区策略
例如:我们想让含有“china”相关的字符串,存到主题为china的分区里。
我们可以通过去判断value里是否包含china,如果包含就指明对应的分区号即可。
public class MyPartition implements Partitioner {/**** @param s:topic* @param o:key* @param bytes* @param o1:value* @param bytes1* @param cluster:集群* @return*/@Overridepublic int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) {String message = bytes1.toString();int partition;if(message.contains("china")){partition = 1;}else{partition = 2;}return partition;}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> map) {}
}
生产者拦截器
生产者拦截器主要是为消息发送前做一些准备工作,如过滤某些不表的信息、修改消息的内容等等,有可以在发送回调逻辑前做一些定制化需求,比如统计类工作
生产者拦截器主要由接口ProducerInterceptors实现,主要包含以下三个方法:
-
在消息序列化和计算分区之前会调用onSend()方法
public ProducerRecord<K, V> onSend(ProducerRecord<K, V> record); -
在消息应答或者发送失败时会调用onAcknowledgement()方法,优先于Callback之前执行
public void onAcknowledgement(RecordMetadata metadata, Exception exception) -
close()方法主要是关闭拦截器时执行的一些资源清理工作
上述3个方法中抛出的异常都会被捕获并记录到日志中去,且不会再向上传递
KafkaProducer 中不仅可以指定一个拦截器,还可以指定多个拦截器以形成拦截链。拦截链会按照 interceptor.classes 参数配置的拦截器的顺序来一一执行(配置的时候,各个拦截器之间使用逗号隔开)。
自定义拦截器:
/*** @authoer:zky* @createDate:2022/8/16* @description:*/
public class ProducerInterceptorDate implements ProducerInterceptor<String,String> {private volatile long sendSuccess = 0;private volatile long sendFailure = 0;@Overridepublic ProducerRecord<String,String> onSend(ProducerRecord<String,String> record) {return new ProducerRecord(record.topic(),record.partition(),record.timestamp(),record.key(),record.value() + "-" + new SimpleDateFormat("yyyy-MM-dd").format(new Date()),record.headers());}@Overridepublic void onAcknowledgement(RecordMetadata metadata, Exception exception) {if (exception == null) {sendSuccess++;} else{sendFailure++;}}@Overridepublic void close() {double successRatio = (double)sendSuccess / (sendFailure + sendSuccess);System.out.println("[INFO]发送成功率=" + String.format("%f",successRatio * 100) + "%");}@Overridepublic void configure(Map<String, ?> configs) {}
}添加properties属性:
properties.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,"com.zky.kafkademo.ProducerInterceptorDate");
进行如上两个操作后,生产者生成消息的时候就会走我们自定义的拦截器








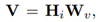


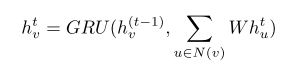
![[概念]神经网络的种类(前馈神经网络,反馈神经网络,图网络)](https://img-blog.csdnimg.cn/20200226160209933.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MDUxOTMxNQ==,size_16,color_FFFFFF,t_70)