SQL DDL:用户自定义函数UDF
什么是UDF?
Hive支持的函数除了内置函数,允许编写用户自定义函数(User Define Function)来扩充函数的功能。
用户自定义函数需要使用Java语言进行编写,完成的UDF可以打包成Jar加载到Hive中使用。
UDF根据功能不同,可以分为UDF、UDAF、UDTF。
UDF对每一行数据进行处理,输出相同行数的结果,是一对一的处理方式,比如将每一行字符串转换为大写形式。
UDAF(用户自定义聚合函数),对多行进行处理,输出单个结果,是一对多的处理方式。一般UDAF会配合group by来使用,比如先按照city进行group by操作,然后统计每个city的总人数。
UDTF(用户自定义表生成函数),对一行数据进行处理,输出多个结果,多对一处理方式。比如将每一行字符串按照空格进行拆分,拆分成多行进行存储。使用了UDTF后,表的行数会增多。
用户自定义函数操作
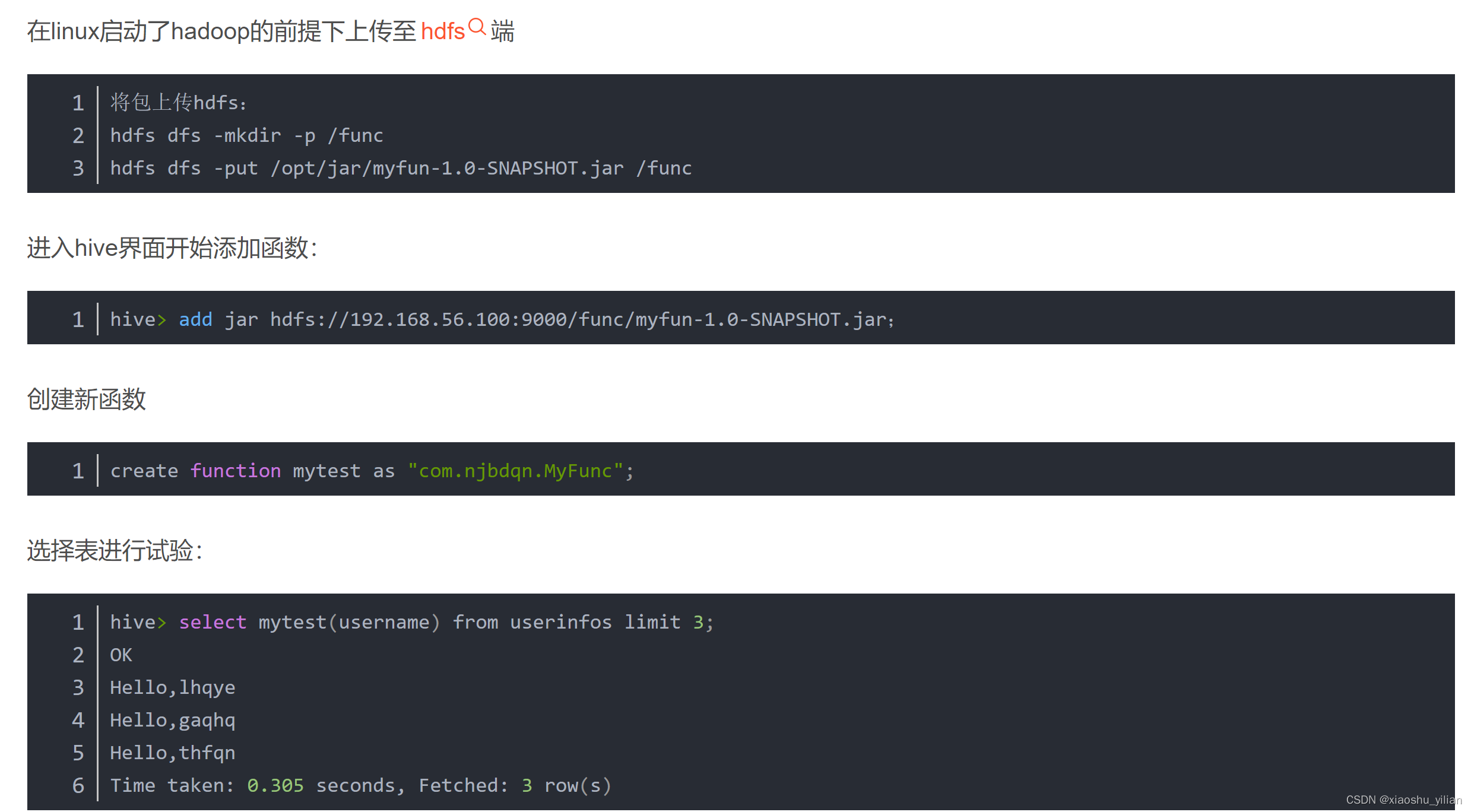
将代码打成Jar包,上传到集群中。可以通过Jar包在Hive中创建临时函数、永久函数。其中临时函数在Hive的生命周期有效,重启Hive后函数失效,而永久函数则永久生效。
临时函数的创建命令:
ADD JAR[S] <local_or_hdfs_path>;
CREATE TEMPORARY FUNCTION <function_name> AS <class_name>;
DROP TEMPORARY FUNCTION [IF EXISTS] <function_name>;
永久函数的创建命令:
CREATE PERMANENT FUNCTION <function_name> AS <class_name>[USING JAR|FILE|ARCHIVE '<file_uri>' [, JAR|FILE|ARCHIVE '<file_uri>'] ];
DROP PERMANENT FUNCTION [IF EXISTS] <function_name>;
函数创建后,可以查看所有函数:
SHOW FUNCTIONS;
也可以单独查看某个函数的详细情况:
DESCRIBE FUNCTION <function_name>;
UDF编写
创建UDF可以继承org.apache.hadoop.hive.ql.exec.UDF或者org.apache.hadoop.hive.ql.udf.generic. GenericUDF类。其中直接继承UDF类,功能实现较为简单,但在运行时使用Hive反射机制,导致性能有损失,而且不支持复杂类型。GenericUDF则更加灵活,性能也更出色,支持复杂数据类型(List,Struct),但实现较为复杂。
在较新的Hive版本中,org.apache.hadoop.hive.ql.exec.UDF类已经废弃,推荐使用GenericUDF来完成UDF的实现。但org.apache.hadoop.hive.ql.exec.UDF方式实现起来方便,在很多开发者中,依然很受欢迎。
UDF实现方式一:继承UDF类
UDF开发流程
继承UDF类进行UDF的开发流程是:
- 继承org.apache.hadoop.hive.ql.exec.UDF类
- 实现evaluate()方法,在方法中实现一对一的单行转换
案例描述
现在来编写3个实际案例的开发,需要实现以下功能:
功能一:将每行数据,转换为小写形式
功能二:传入yyyy-MM-dd hh:mm:ss.SSS形式的时间字符串,返回时间戳(单位毫秒)
功能三:为每一行数据生成一个指定长度的随机字符串作为UUID
UDF开发:功能一
功能一的开发相对简单,创建Java类,继承org.apache.hadoop.hive.ql.exec.UDF,然后实现evaluate()方法,因为要将每行数据转换为小写,所以evaluate()方法参数为Text类型,首先进行空值判断,如果不为空,则转换为小写形式并返回。
这些为什么使用Text类型,而不使用String类型呢?其实都可以。只不过Text类型是Hadoop的Writable包装类,进行了序列化实现,可以在Hadoop集群中更方便的进行数据传输,而且Writable对象是可重用的,效率会更高一些。
常见的Hadoop包装类有:
BooleanWritable:标准布尔型数值
ByteWritable:单字节数值
DoubleWritable:双字节数值
FloatWritable:浮点数
IntWritable:整型数
LongWritable:长整型数
Text:使用UTF8格式存储的文本
NullWritable:当<key, value>中的key或value为空时使用
在UDF方法前,可以使用注解Description对方法添加描述信息。
功能一的具体实现如下:
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.exec.Description;
import org.apache.hadoop.io.Text;@org.apache.hadoop.hive.ql.exec.Description(name = "Lower",extended = "示例:select Lower(name) from src;",value = "_FUNC_(col)-将col字段中的每一行字符串数据都转换为小写形式")
public final class Lower extends UDF {public Text evaluate(final Text s) {if (s == null) { return null; }return new Text(s.toString().toLowerCase());}
}
在Test.java中进行测试:
import org.apache.hadoop.io.Text;public class Test {public static void testLower(String in){Lower lower = new Lower();Text res = lower.evaluate(new Text(in));System.out.println(res);}public static void main(String[] args) {testLower("UDF");}
}
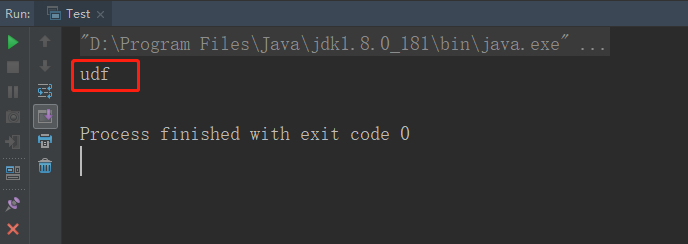
测试通过后,需要先将代码打成Jar包。
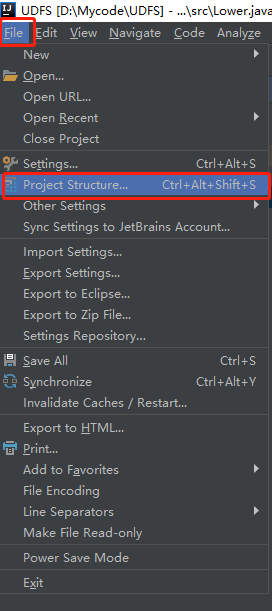
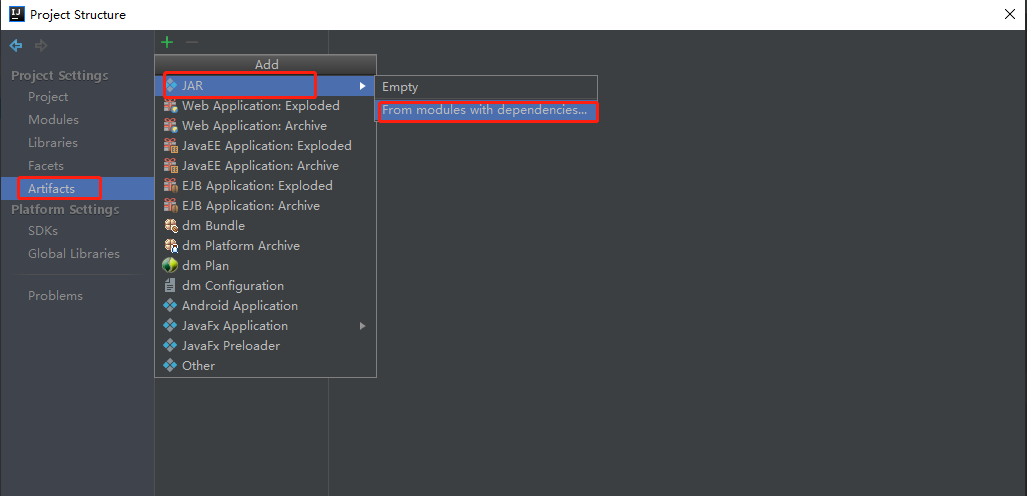
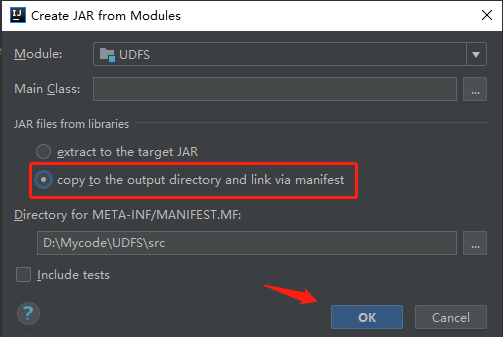
因为集群中已经有hadoop、hive依赖了,所以需要将代码中的依赖去除。
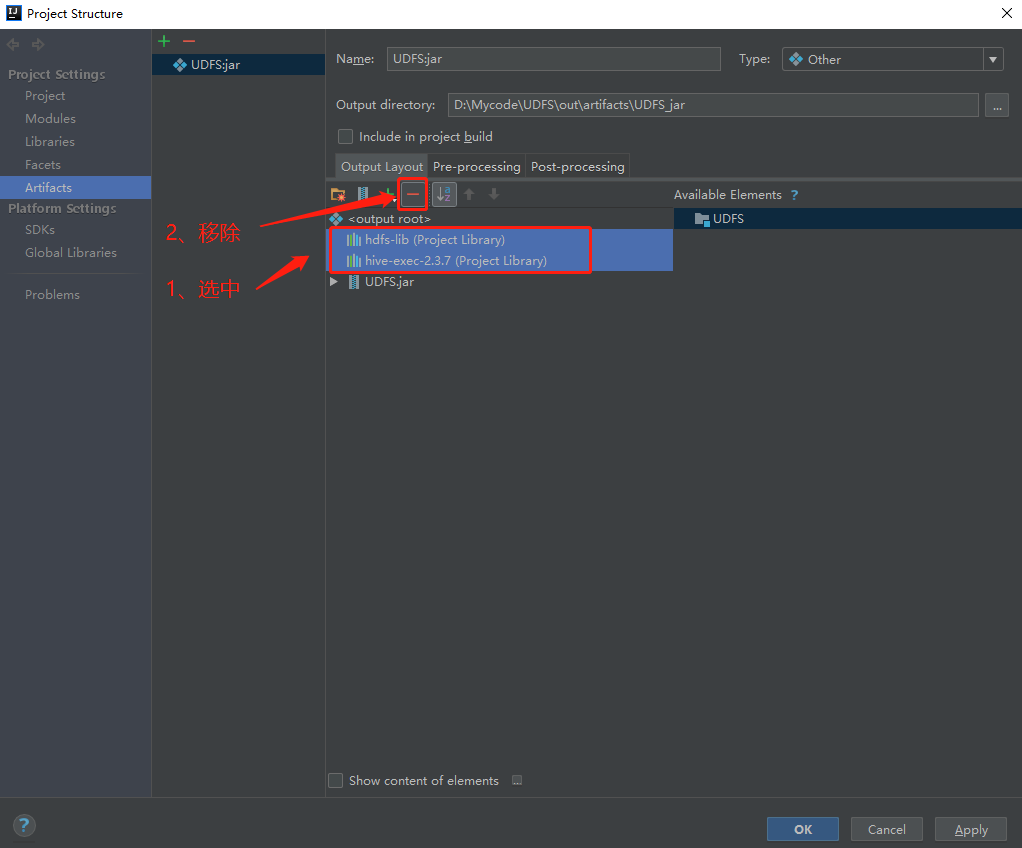
进行源码编译,生成jar包。
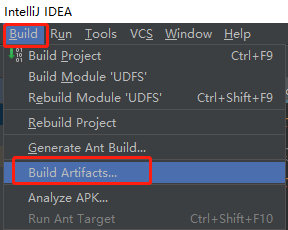
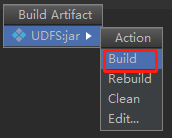
找到编译好的jar包,并上传到Node03节点的/root目录下。
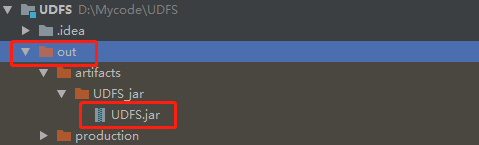
在beeline中,使用SQL将jar包添加到hive中。
add jars file:///root/UDFS.jar;

通过jar包中的Lower类,创建临时函数udf_lower,当然也可以创建永久函数。在教程中,为了方便起见,之后的函数都会创建为临时函数使用。
--创建临时函数
create temporary function udf_lower as "Lower";
--创建永久函数
create permanent function udf_lower as "Lower";

函数创建好之后,便可以在SQL中进行调用:
select udf_lower("UDF");
UDF开发:功能二
功能二的开发,也相对比较简单,同样创建java类TimeCover,继承org.apache.hadoop.hive.ql.exec.UDF,然后实现evaluate()方法。
在方法中,传入yyyy-MM-dd hh:mm:ss.SSS形式的时间字符串,将返回时间戳(单位毫秒)。具体实现如下:
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;import java.time.LocalDate;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;@org.apache.hadoop.hive.ql.exec.Description(name = "TimeCover",extended = "示例:select TimeCover(create_time) from src;",value = "_FUNC_(col)-将col字段中每一行形式为yyyy-MM-dd hh:mm:ss.SSS的时间字符串转换为时间戳")
public class TimeCover extends UDF {public LongWritable evaluate(Text time){String dt1 = time.toString().substring(0,time.toString().indexOf("."));String dt2 = time.toString().substring(time.toString().indexOf(".")+1);DateTimeFormatter dtf=DateTimeFormatter.ofPattern("yyyy-MM-dd hh:mm:ss");long millisec;LocalDate date = LocalDate.parse(dt1, dtf);millisec = date.atStartOfDay(ZoneId.systemDefault()).toInstant().toEpochMilli() + Long.parseLong(dt2);LongWritable result = new LongWritable(millisec);return result;}
}编写测试方法进行测试:
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;public class Test {private static void testTimeCover(String in){TimeCover timeCover = new TimeCover();LongWritable res = timeCover.evaluate(new Text(in));System.out.println(res.get());}public static void main(String[] args) {testTimeCover("2021-01-17 05:25:30.001");}
}
打成Jar包,在hive中创建临时函数进行测试。这里需要注意的是,重复添加同名的jar包时需要重启hive。
add jars file:///root/UDFS.jar;
create temporary function time_cover as "TimeCover";
select time_cover("2021-01-17 05:25:30.001");
这里对时间的处理,使用的是DateTimeFormatter类,如果对Java开发比较熟悉的同学应该知道,它是线程安全的。在Hive的UDF开发过程中,一定要避免线程非安全类的使用,如SimpleDateFormat。线程非安全类的使用,在分布式环境中运行时会带来很多问题,产生错误的运行结果,而且不会产生报错,因为不是程序本身的问题;这种情况非常不好进行排查,在本地测试时正常,在集群中会出问题,所以在开发时一定要有这个意识。
UDF开发:功能三
功能三的需求是:为每一行数据生成一个指定长度的随机字符串作为UUID,这和前面两个UDF有所区别。前两个UDF是将某一个字段作为参数,将这一列的每一行数据进行了转换;而功能三则是传入一个指定数值,新生成一列数据。如select UUID(32) from src,传入参数32,为每一行数据新生成了一个32位长度的随机字符串。
代码实现起来相对简单,具体实现如下:
import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.hive.ql.udf.UDFType;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;/*生成一个指定长度的随机字符串(最长为36位)*/
@org.apache.hadoop.hive.ql.exec.Description(name = "UUID",extended = "示例:select UUID(32) from src;",value = "_FUNC_(leng)-生成一个指定长度的随机字符串(最长为36位)")
@UDFType(deterministic = false)
public class UUID extends UDF {public Text evaluate(IntWritable leng) {String uuid = java.util.UUID.randomUUID().toString();int le = leng.get();le = le > uuid.length() ? uuid.length() : le;return new Text(uuid.substring(0, le));}
}
编写测试方法进行测试:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;public class Test {private static void testUUID(int in){UUID uuid = new UUID();Text res = uuid.evaluate(new IntWritable(in));System.out.println(res);}public static void main(String[] args) {testUUID(10);}
}
打成Jar包,在hive中创建临时函数进行测试。
add jars file:///root/UDFS.jar;
create temporary function uuid as "UUID";
select uuid(10);

UDF开发注意事项
继承UDF类进行开发时,默认调用evaluate()方法;当然也可以继承UDFMethodResolver类,更改默认的入口方法。
现在已经实现的三个UDF功能都进行了数据的返回,如果需要evaluate()不返回数据的,可以返回null,比如数据清洗的时候会用到这种场景。对于UDF的返回类型可以是Java类型或者Writable类,当然推荐Writable包装类。
UDF实现方式二:继承GenericUDF类
继承org.apache.hadoop.hive.ql.udf.generic. GenericUDF类进行UDF的开发,是社区推荐的写法。它能处理复杂类型数据,而且相对于UDF类来说,更加灵活。但实现起来会稍微复杂一些。
开发流程
使用GenericUDF进行UDF开发的具体流程为:
- 继承org.apache.hadoop.hive.ql.udf.generic. GenericUDF类
- 实现initialize、 evaluate、 getDisplayString方法
重写的这三个方法,它们各自完成的功能如下:
| 接口方法 | 返回值 | 描述 |
|---|---|---|
| initialize | ObjectInspector | 全局初始化,一般用于检查参数个数和类型,初始化解析器,定义返回值类型 |
| evaluate | Object | 进行数据处理,并返回最终结果 |
| getDisplayString | String | 函数在进行HQL explain解析时,展示的字符串内容 |
GenericUDF实际案例
现在,完成一个UDF的开发案例来进行实践。这个案例中,将会对复杂数据类型Map进行处理。
在表中,学生的成绩字段数据以Map类型进行保存:
{"computer":68, "chinese": 95, "math": 86, "english": 78}
现在,需要开发UDF,对每个学生的成绩进行平均值的计算。即对每一行保存的Map数据进行提取,获取到成绩后(68、95、86、78),完成平均值的计算( ( 68+95+86+78 ) / 4 ),返回结果。精度要求为:保留两位小数。
首先导入相关包,继承GenericUDF,并重写它的三个方法:
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.MapObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;import java.text.DecimalFormat;@org.apache.hadoop.hive.ql.exec.Description(name = "AvgScore",extended = "示例:select AvgScore(score) from src;",value = "_FUNC_(col)-对Map类型保存的学生成绩进行平均值计算")
public class AvgScore extends GenericUDF {@Overridepublic ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {…}@Overridepublic Object evaluate(DeferredObject[] deferredObjects) throws HiveException {…}@Overridepublic String getDisplayString(String[] strings) {…}
}
在AvgScore类中,需要定义类属性,用于保存基本信息。这里定义的UDF的名称和返回值精度,还包含一个参数解析类MapObjectInspector的对象。因为GenericUDF通过参数解析对象来对传入数据进行解析、转换,所以它比直接继承UDF类有更好的灵活性,支持对各种复杂类型数据的处理。
@org.apache.hadoop.hive.ql.exec.Description(name = "AvgScore",extended = "示例:select AvgScore(score) from src;",value = "_FUNC_(col)-对Map类型保存的学生成绩进行平均值计算")
public class AvgScore extends GenericUDF {// UDF名称private static final String FUNC_NAME="AVG_SCORE";// 参数解析对象private transient MapObjectInspector mapOi;// 返回值精度DecimalFormat df = new DecimalFormat("#.##");@Overridepublic ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {…}@Overridepublic Object evaluate(DeferredObject[] deferredObjects) throws HiveException {…}@Overridepublic String getDisplayString(String[] strings) {…}
}然后重写initialize方法,进行参数个数、类型检测,并初始化数据解析对象,定义UDF最终的返回值类型。
initialize方法中的形参ObjectInspector[],为UDF在调用时传入的参数列表的数据对象。在案例中AvgScore(score),传入了score字段,则ObjectInspector[]列表长度为1,其中ObjectInspector对象包含了成绩字段的数据以及它的参数个数、类型等属性。
在方法中,需要对参数进行数据类型检测。GenericUDF支持的数据类型在ObjectInspector.Category中进行了定义。包含基础数据类型:PRIMITIVE,复杂数据类型: LIST, MAP, STRUCT, UNION。
除此之外,还需要初始化用于数据解析的ObjectInspector对象,指定解析的数据类型。提供的数据解析类有PrimitiveObjectInspector、ListObjectInspector、MapObjectInsector、StructObjectInsector等。
initialize函数需要在return时返回UDF最终输出的数据类型,这里因为是对成绩的平均值计算,所以最终结果为Double类型,返回javaDoubleObjectInspector。
initialize函数其实完成的就是定义了数据的输入和输出,并完成了数据类型、个数的稽查。
@Overridepublic ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {// 检测函数参数个数if (objectInspectors.length != 1) {throw new UDFArgumentException("The function AVG_SCORE accepts only 1 arguments.");}// 检测函数参数类型,提供的类型有PRIMITIVE, LIST, MAP, STRUCT, UNIONif (!(objectInspectors[0].getCategory().equals(ObjectInspector.Category.MAP))) {throw new UDFArgumentTypeException(0, "\"map\" expected at function AVG_SCORE, but \""+ objectInspectors[0].getTypeName() + "\" " + "is found");}// 初始化用于数据解析的ObjectInspector对象// 提供的类有PrimitiveObjectInspector、ListObjectInspector、MapObjectInsector、StructObjectInsector等mapOi = (MapObjectInspector) objectInspectors[0];// 定义UDF函数输出结果的数据类型return PrimitiveObjectInspectorFactory.javaDoubleObjectInspector;}
接着,需要重写evaluate方法,使用数据解析对象进行数据解析,并求取平均值。
@Overridepublic Object evaluate(DeferredObject[] deferredObjects) throws HiveException {// 获取输入数据Object o = deferredObjects[0].get();// 数据交由ObjectInspector对象进行解析,并进行处理double v = mapOi.getMap(o).values().stream().mapToDouble(a -> Double.parseDouble(a.toString())).average().orElse(0.0);// 返回运算结果,结果数据类型在initialize中已经定义return Double.parseDouble(df.format(v));}
最后,重写getDisplayString方法,完成字符串信息的输出。
@Overridepublic String getDisplayString(String[] strings) {// 函数在进行HQL explain解析时,展示的字符串内容return "func(map)";}
打包成jar,在hive中创建临时函数。
add jars file:///root/UDFS.jar;
create temporary function avg_score as "AvgScore";
创建测试数据score.txt,并上传到HDFS的/tmp/hive_data_score目录下:
# 数据文件内容
1,zs,computer:68-chinese:95-math:86-english:78
2,ls,computer:80-chinese:91-math:56-english:87
3,ww,computer:58-chinese:68-math:35-english:18
4,zl,computer:97-chinese:95-math:98-english:94
5,gg,computer:60-chinese:60-math:60-english:60# 上传到HDFS中
hadoop fs -mkdir -p /tmp/hive_data/score
hadoop fs -put score.txt /tmp/hive_data/score/
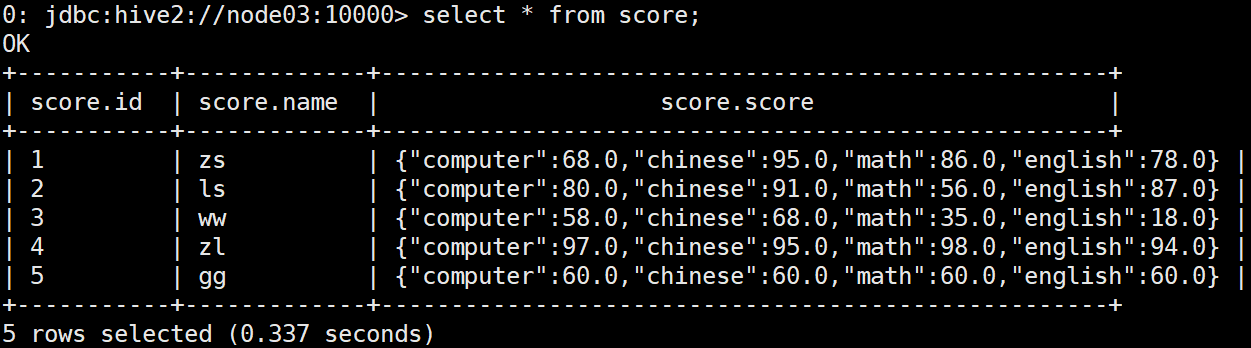
在Hive中创建测试需要的数据表:
create external table score(id int, name string, score map<string, double>)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n'
LOCATION '/tmp/hive_data/score/';
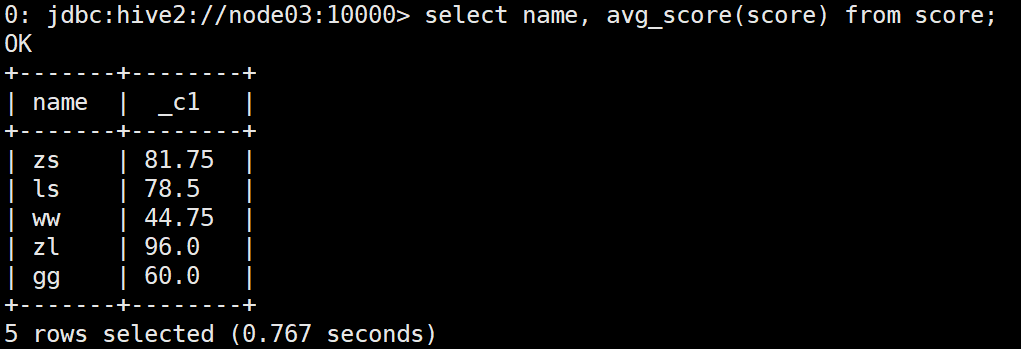
使用UDF函数统计平均成绩:
select name, avg_score(score) from score;