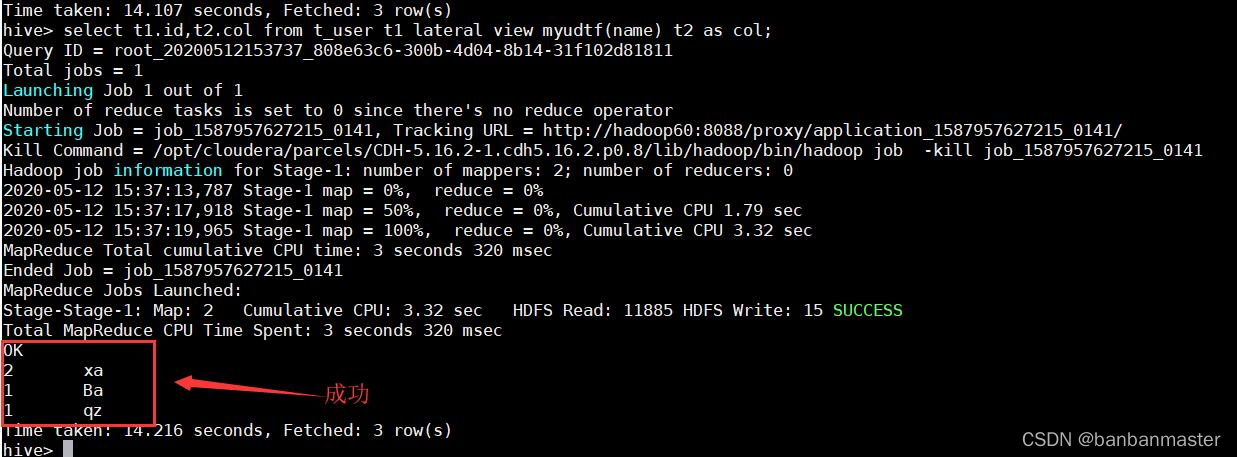
hive自带了一些函数,比如:max、min 等,但是自带的函数数量有限,所以hive提供给用户自定义函数的功能。
udf 函数可以直接应用于select 语句,对查询结构做格式化处理之后,然后再输出内容。
下面将详细介绍下,如何编写一个udf函数,以及这个过程中的需要的一些配置步骤。
1、 安装intelliJ IDEA(公认的最好的java解释器)
–如果公司没有提供已经购买的安装软件,可以直接上淘宝买(远程安装)
–安装intelliJ解释器
2、 安装jdk(一般是java8(jdk1.8))
–可以上淘宝买
–安装java (jdk)
3、 配置java环境
我的电脑>属性>高级系统设置>环境变量>系统变量
–添加JAVA_HOME
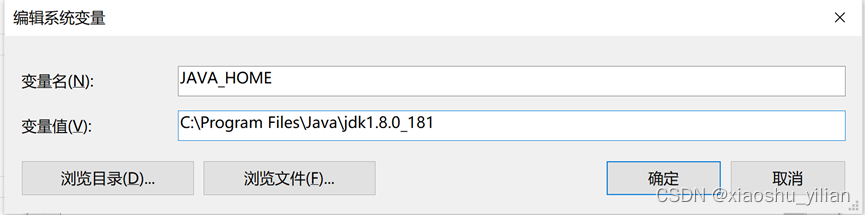
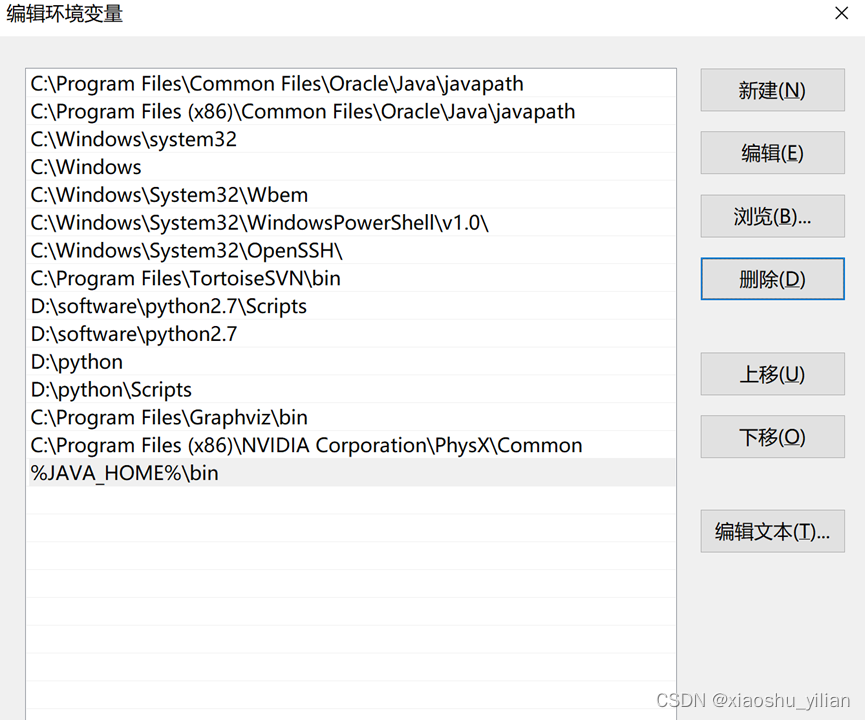
–Path添加JAVA_HOME
–最后验证下,java环境是否搭建好
开始>cmd>where java
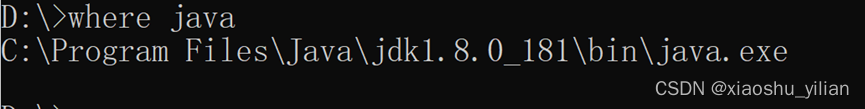
说明java环境已经搭建好
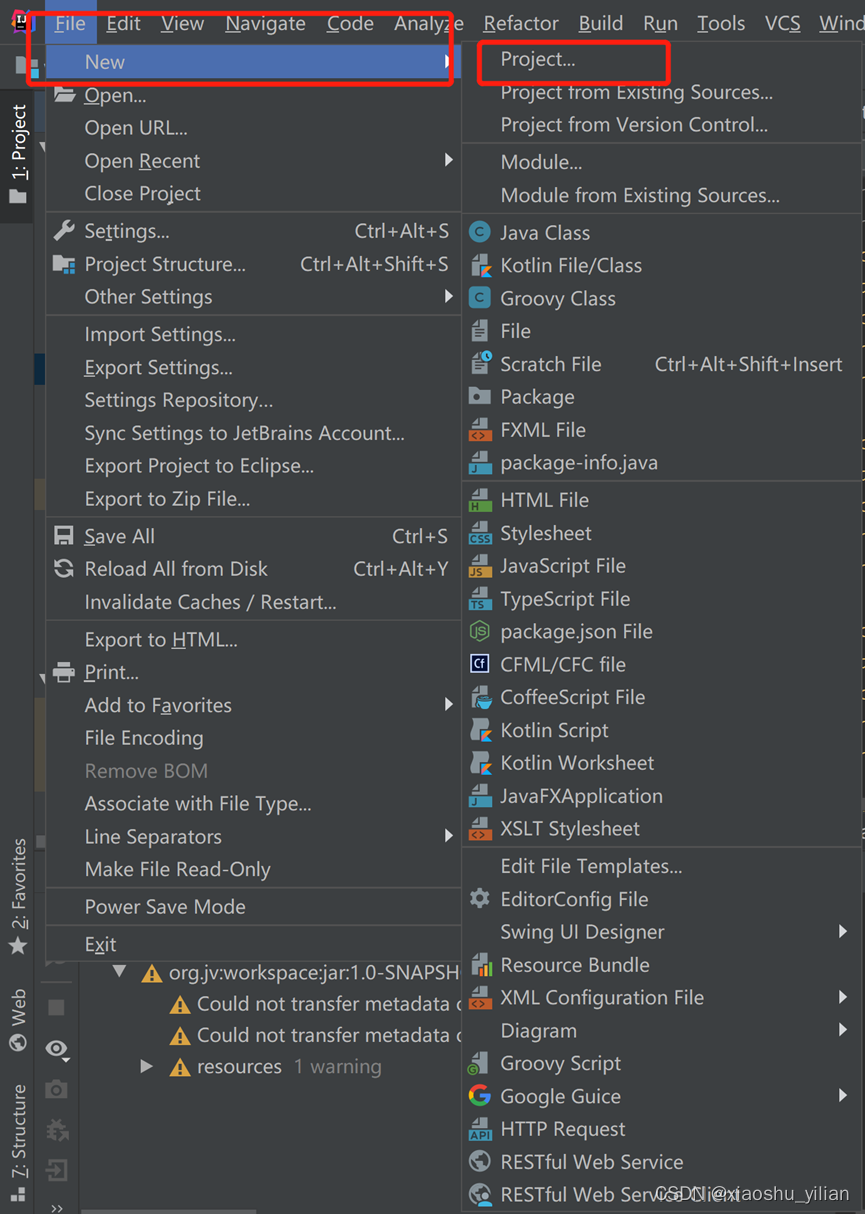
4、 创建一个maven项目
maven不需要安装,idea自带,我们只需要下载依赖(引入需要的jar包,配置文件加上依赖信息)
4.1、找到IntelliJ里的maven
4.2、新建一个maven项目
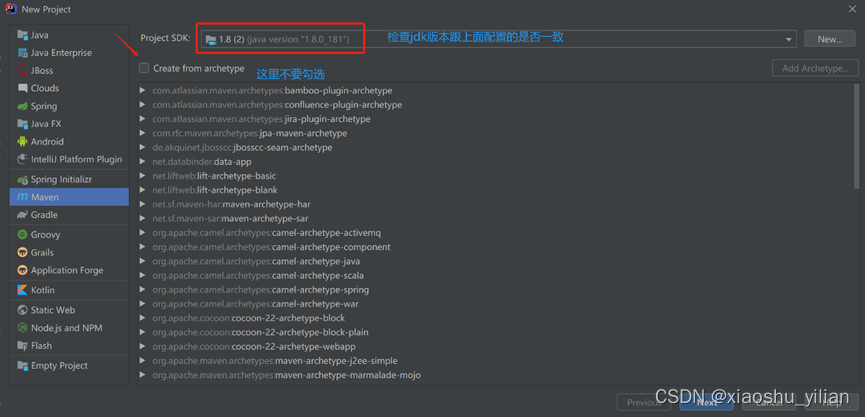
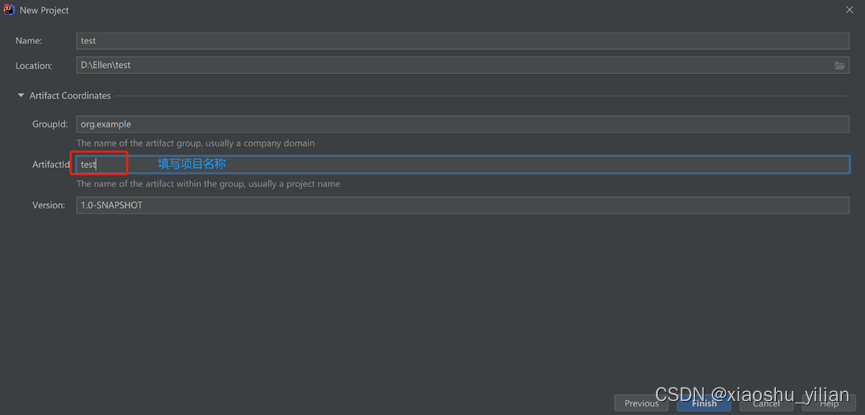
4.3、编写udf 函数
–java>右键>new package>new BigintAdd.class
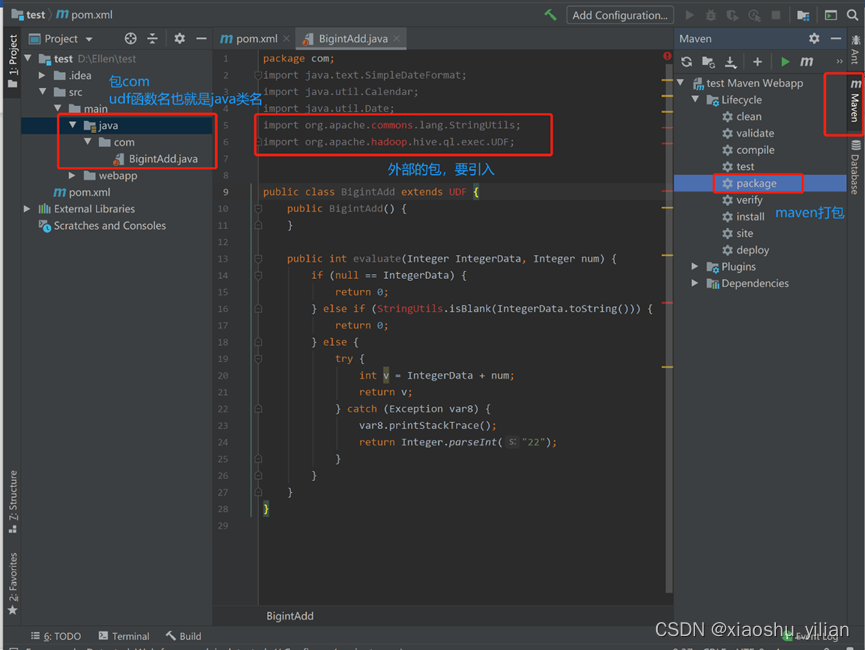
4.4、引入需要的包
–去Maven仓库(https://mvnrepository.com/)下载需要的jar包以及复制所需要的依赖信息
下面以import org.apache.hadoop.hive.ql.exec.UDF;这个包为例
它的jar包名称为hive-exec
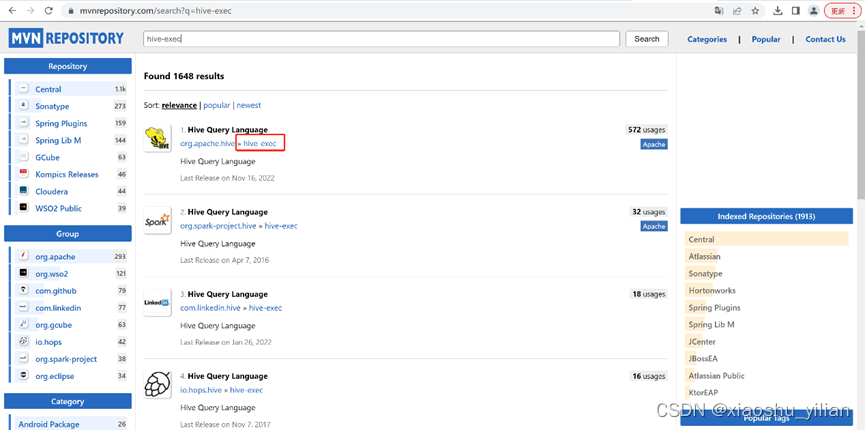
–选择下载的版本
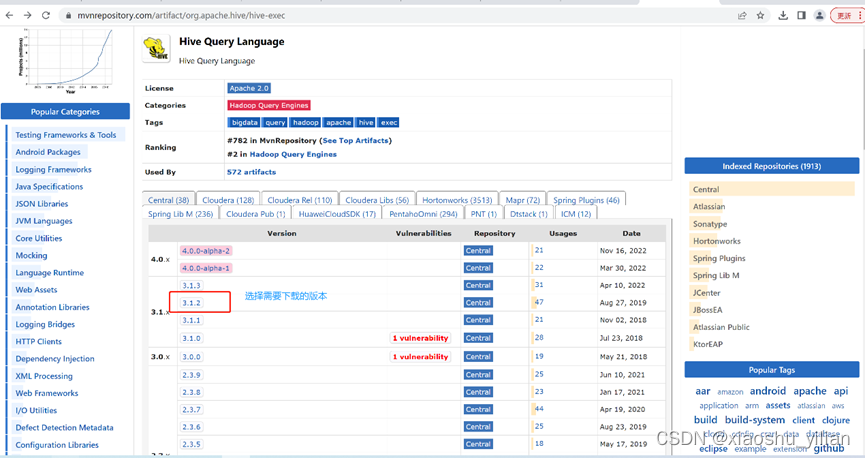
–下载jar包和复制依赖信息
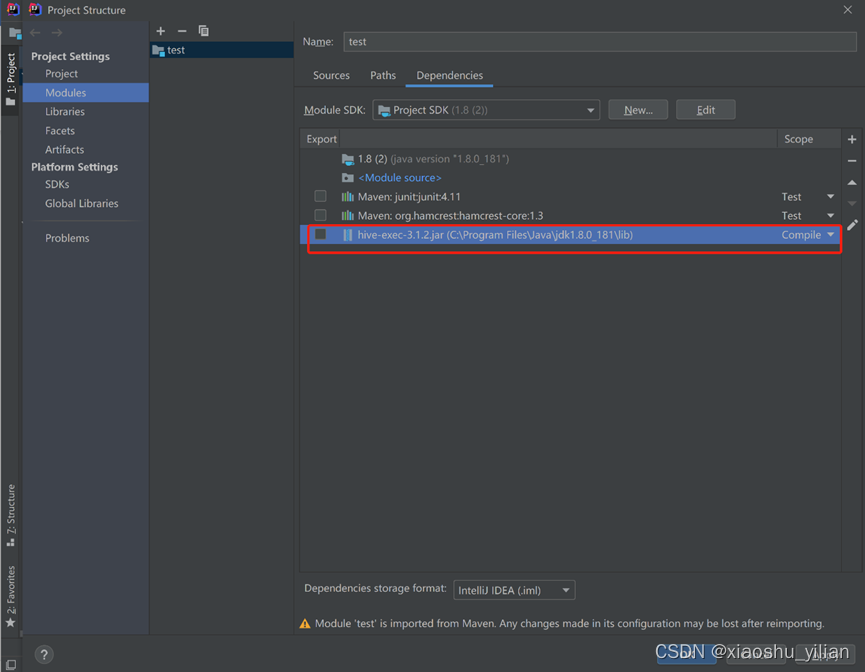
–File>Project Structure>Modules>Dependencies>Jars or directories>添加你下载的jar包
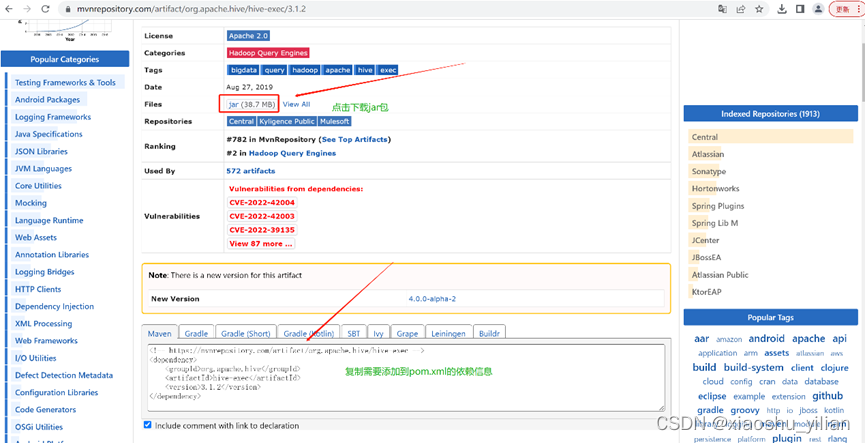
–粘贴依赖的信息
<dependencies><dependency><groupId>commons-lang</groupId><artifactId>commons-lang</artifactId><version>2.6</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><version>3.1.2</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.2</version></dependency>
</dependencies>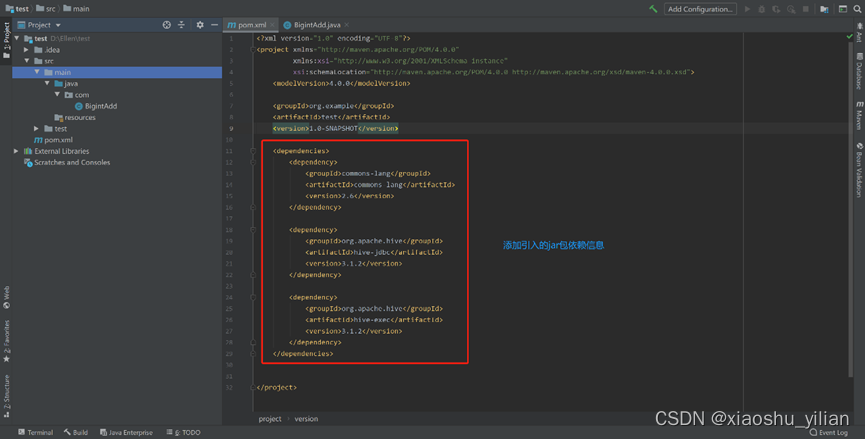
–重新引入配置文件
Test(项目)>右键>Maven>Reimport
–打jar包
Maven>package>Run Maven Build
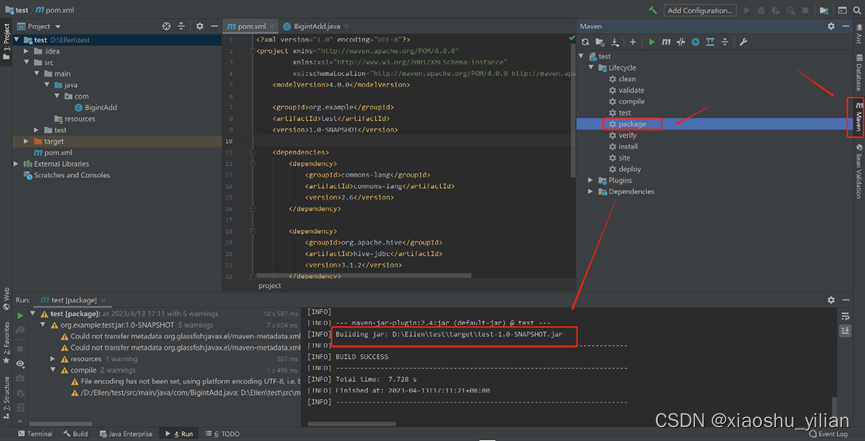
参考这篇文章:https://blog.csdn.net/m0_67393295/article/details/126565694
5、 运行udf函数
由于我们没有开放相关权限,引用网络上大佬的程序,一般公司的大数据平台会开放相关的udf函数接口供用户上传自己编写的udf函数。
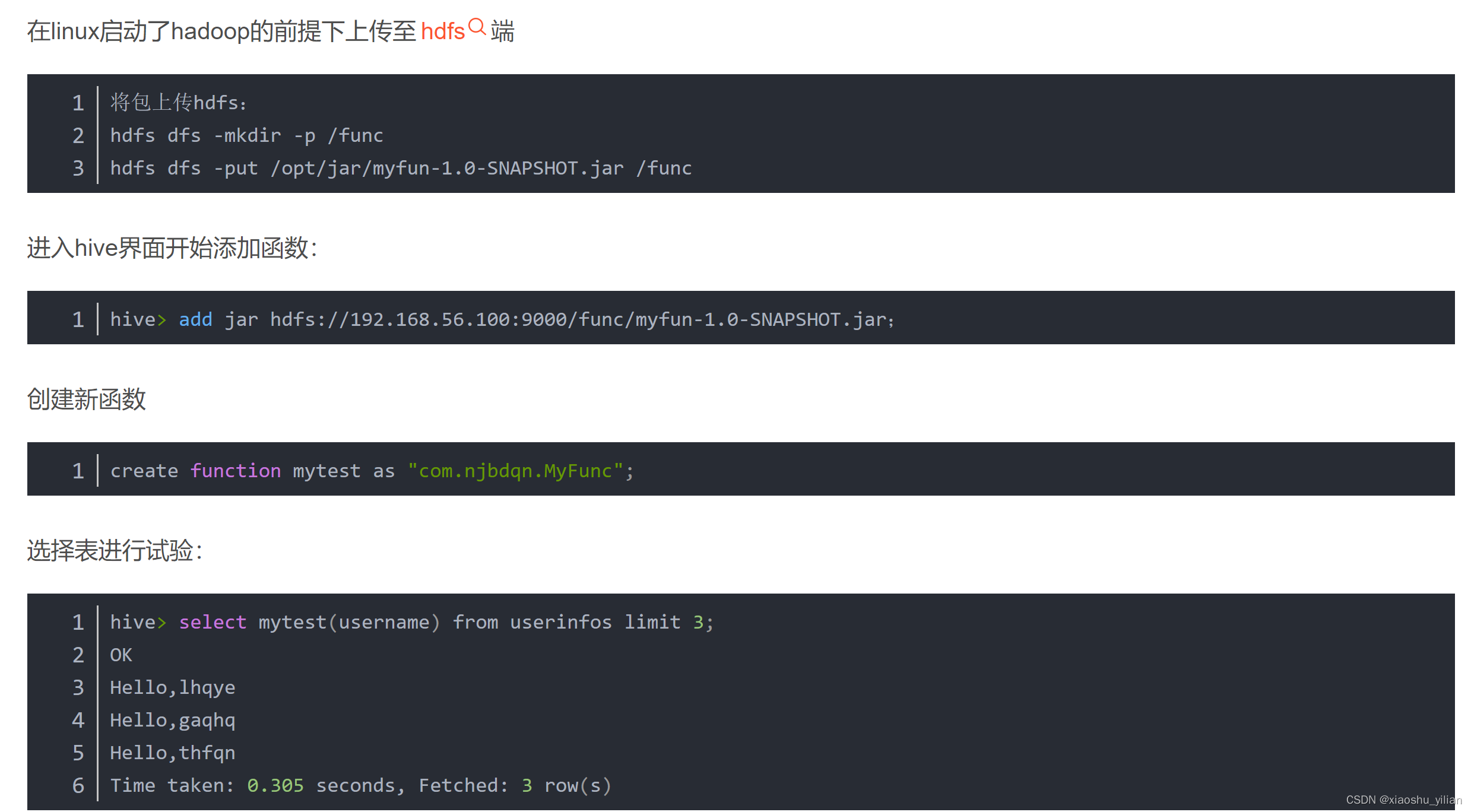
其中"com.njbdqn.Myfunc"是作者的包
引用文章链接:http://t.csdn.cn/2qX3q