目录
自定义函数
自定义UDF函数
自定义UDTF函数
自定义函数
Hive自带一些函数,比如:max/min等;当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数。
UDF:user-defined function
根据用户自定义函数类别可分为以下三种:
1)UDF(User-Defined-Function):一进一出
2)UDAF(User-Defined Aggregation Function):聚集函数,多进一出,类似于count/max/min
3)UDTF(User-Defined Table-Generating Functions):一进多出,如:lateral view explode()
编程步骤:
1)继承Hive提供的类
org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
2)实现类中的抽象方法
3)在hive的命令行窗口创建函数
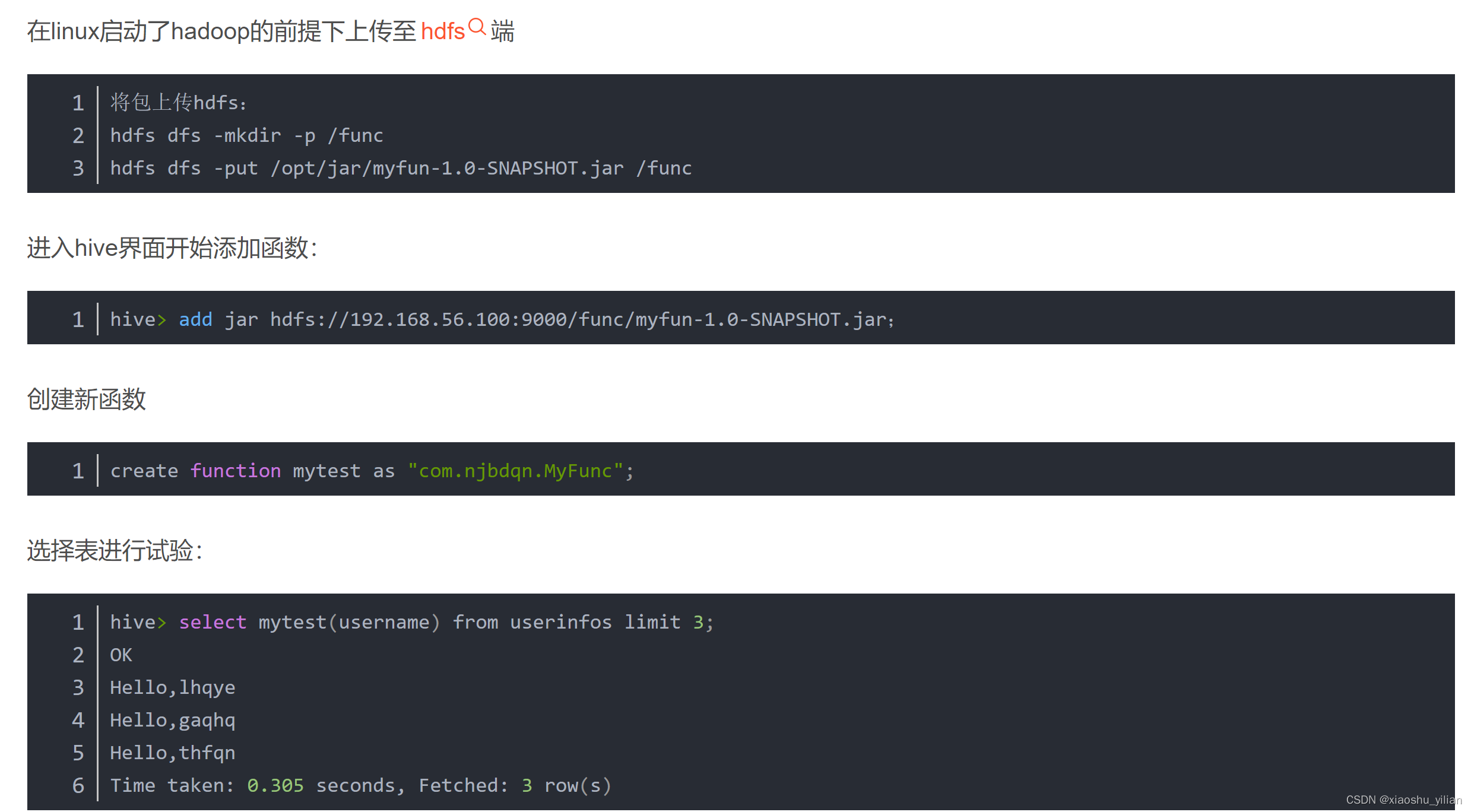
添加jar
add jar jar_path创建function
create [temporary] function [dbname.]function_name AS class_name;4)在hive的命令行窗口删除函数
drop [temporary] function [if exists] [dbname.]function_name;自定义UDF函数
需求:自定义一个UDF函数实现计算字符串长度
(1)创建maven工程
(2)导入依赖
<dependencies><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.2</version></dependency></dependencies><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target></properties>(3)编写代码
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentTypeException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;/**
* 自定义UDF函数需要继承GenericUDF类
* 需求:计算指定字符串的长度
*/
public class MyStringLength extends GenericUDF {/*** @objectInspectors 输入参数类型的鉴别器对象* @return 返回值类型的鉴别器类型对象* @throws UDFArgmentException*/public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {//判断输入参数的个数if (objectInspectors.length != 1) {throw new UDFArgumentLengthException("Input args Length Error!!!");}//判断输入参数的类型if (!objectInspectors[0].getCategory().equals(ObjectInspector.Category.PRIMITIVE)) {throw new UDFArgumentTypeException(0,"Input Type Error!!!");}//函数本身返回值为int,需要返回int类型的鉴别器对象return PrimitiveObjectInspectorFactory.javaIntObjectInspector;}/*** 函数的逻辑处理* @deferredObjects 输入的参数* @return 返回值* @throws HiveException*/public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {if (deferredObjects[0].get() == null) {return 0;}return deferredObjects[0].get().toString().length();}public String getDisplayString(String[] strings) {return null;}
}(4)打包上传到hive
1)打包
2)将包添加到hive
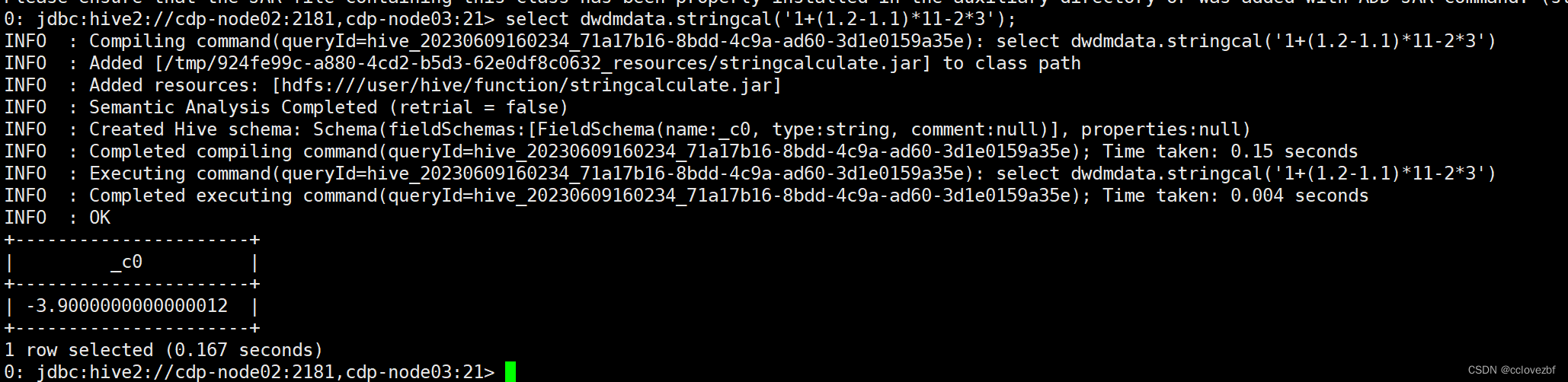
hive (test)> add jar /root/datas/jar/functionlen-1.0-SNAPSHOT.jar;创建临时函数
hive (test)> create temporary function mylen as "com.zj.MyStringLength";
(5)测试
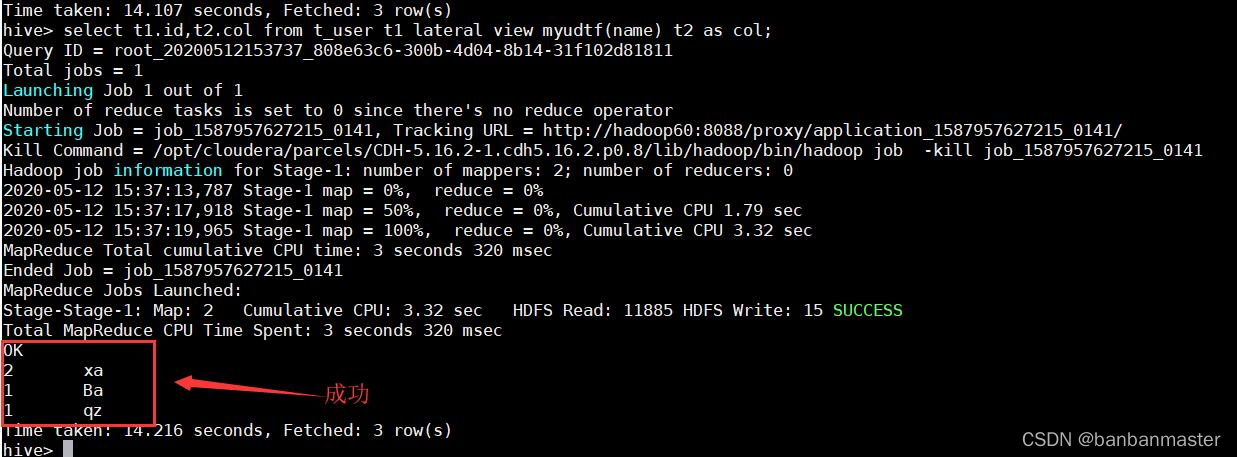
hive (test)> select name,mylen(name) name_len from movie;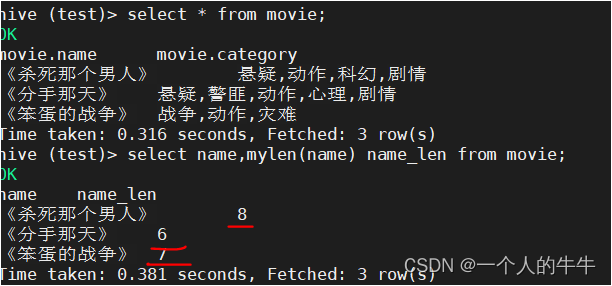
自定义UDTF函数
需求:自定义UDTF函数实现切分字符串
(1)创建maven工程
(2)导入依赖
<dependencies><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.2</version></dependency></dependencies><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target></properties>(3)编写代码
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
import java.util.List;public class MyUDTF extends GenericUDTF {private ArrayList<String> outList = new ArrayList<String>();public StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException{//1.定义输出数据的列名和类型List<String> fieldNames = new ArrayList<String>();List<ObjectInspector> fieldOTs = new ArrayList<>();//2.添加输出数据的列名和类型fieldNames.add("lineToWord");fieldOTs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames,fieldOTs);}public void process(Object[] objects) throws HiveException {//1.获取原始数据String object = objects[0].toString();//2.获取数据输入的第二个参数,此处为分隔符String splitKey = objects[1].toString();//3.将原始数据按照传入的分隔符进行切分String[] fields = object.split(splitKey);//4.遍历切分后的结果,并写出for (String field : fields) {//清空集合outList.clear();//将每一个单词添加至集合outList.add(field);//将集合内容写出forward(outList);}}public void close() throws HiveException {}
}(4)打包上传到hive
1)打包
2)将包添加到hive
hive (test)> add jar /root/datas/jar/functionlen-1.0-SNAPSHOT.jar;创建临时函数
hive (test)> create temporary function myudtf as "com.zj.MyUDTF";

(5)测试
hive (test)> select myudtf("hello,world,hello,hive,hello,spark",",");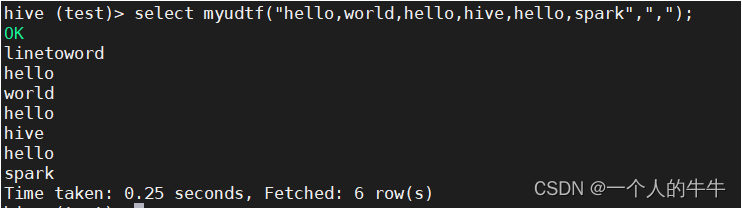
本文为学习笔记!!!