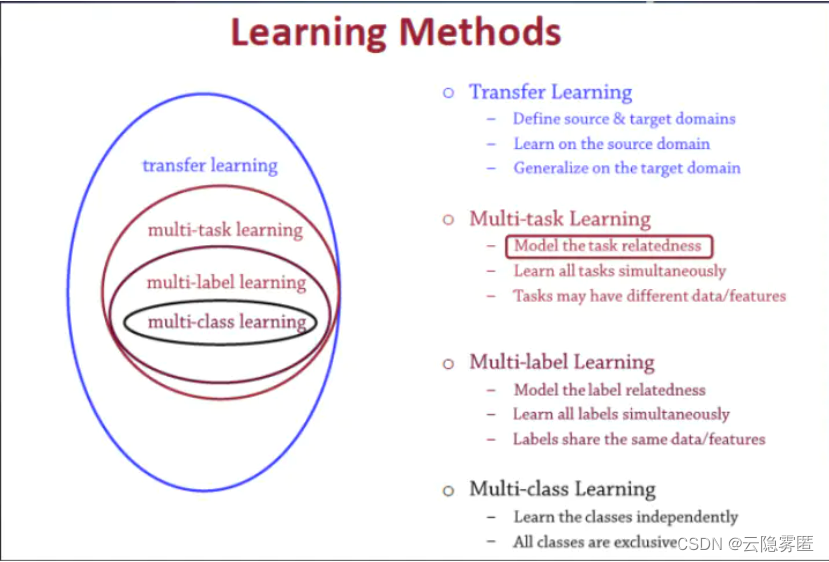
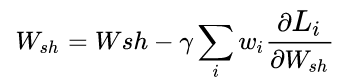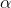在2017年有一篇关于在深度神经网络中多任务学习概述的论文:《An Overview of Multi-Task Learning in Deep Neural Networks》,论文链接为:https://arxiv.org/pdf/1706.05098.pdf,它介绍了在深度学习中多任务学习(Multi-task Learning, MTL)的两种最常用的方法。以下截图均来自此论文。
传统的机器学习方法主要是基于单任务的学习(Single-task Learning)模式进行学习,对于复杂的学习任务也可将其分解为多个独立的单任务进行学习,然后对学习得到的解决进行组合,得到最终的结果。
多任务学习的关键就在于寻找任务之间的关系,如果任务之间的关系衡量恰当,那么不同任务之间就能相互提供额外的有用信息,利用这些额外信息,可以训练出表现更好、更鲁棒的模型。反之,如果关系衡量不恰当,不仅不会引入额外的信息,反而会给任务本身引来噪声,模型学习效果不升反降。当单个任务的训练数据集不充分的时候,此时多任务学习的效果能够有比较明显的提升,这主要是因为单个任务无法通过自身的训练数据集得到关于数据分布的足够信息。如果有多个任务联合学习,那么这些任务将能从相关联的任务中得到额外的信息,因此学习效果将有显著的提升。目前,多任务学习已经在多个领域得到广泛的应用,比如人脸属性的相关研究、人类疾病的研究、无人驾驶的研究等。
多任务学习是机器学习的一个重要组成部分,是迁移学习的一种。多任务学习作为迁移学习的一个分支有着其自己独特的学习背景和应用。在给定几个相关联任务的输入数据和输出数据的情况下,多任务学习能够发挥任务之问的关系,同时学习多个模型。与单任务学习相比,主要有以下几个方面的优势:A.多任务学习通过挖掘任务之间的关系,能够得到额外的有用信息,大部分情况下都要比单任务学习的效果要好。在有标签样本比较少的情况下,单任务学习模型往往不能够学习得到足够的信息,表现较差,多任务学习能克服当前任务样本较少的缺点,从其他任务里获取有用信息,学习得到效果更好、更鲁棒的机器学习模型。B.多任务学习有更好的模型泛化能力,通过同时学习多个相关的任务,得到的共享模型能够直接应用到将来的某个相关联的任务上。相比于单任务学习,上面的优点使得多任务学习在很多情况下都是更好的选择。现实生活中有很多适合多任务学习的场景,以下举例说明(1).自然语言处理相关的研究,比如把词性标注、句子句法成分划分、命名实体识别、语义角色标注等任务放在一起研究。(2).人脸识别中,人脸的属性的研究、人脸识别、人脸年龄预测等任务也可以通过多任务学习进行解决。(3).图像分类,不同光照下、拍摄角度、拍摄背景下等分类任务的研究,也可以在多任务研究的框架下完成。除了上述举例的三种不同应用之外,现实生活中还有很多类似的多任务学习的例子。
深度学习中的两种MTL方法:
(1).基于硬约束的多任务学习方法,如下图所示:表示的是不同任务通过分享一些底部的层学习一些共有的低层次的特征,为了保证任务的独特性,每个任务在顶部拥有自己独特的层学习高层次的特征。这种方法底层共享的参数是完全相同的。

多个任务之间共享网络的同几层隐藏层,只不过在网络的靠近输出层的网络开始分叉去做不同的任务。不同任务通过共享网络底部的几层隐藏层来学习一些共有的抽象层次低的特征,这种方法的底层共享的参数是完全相同的。同时针对各个任务的特点,各个任务都设计各自的任务特有层来学习抽象层次更高的特征。所有任务在保留任务特有的输出层的同时可以共享一些相关的隐藏层。这种多任务学习的方法通过平均噪声能有效地降低过拟合的风险。而且相关的任务越多,目标任务的过拟合风险越小。
(2).基于软约束的多任务学习方法,如下图所示:该方法不要求底部的参数完全一样,而是对不同任务底部的参数进行正则化。相对于硬参数约束的多任务深度学习模型,软约束的多任务学习模型的约束更加宽松,当任务关系不是特别紧密的时候,有可能学习得到更好的结果。多任务深度学习模型需要同时学习一个适合多个任务的网络构架,一般来说模型具有更好的鲁棒性,不容易过拟合。

软约束的多任务学习方法是隐藏层参数软共享,不同的任务使用不同的网络,但是不同任务的网络参数,采用正则化作为约束,与硬约束的多任务学习不同的是,底层的参数不一定完全一致,而是鼓励参数相似化。
为什么多任务学习有效:假定有两个相关的任务A和B,它们依赖共享隐藏层。
(1).隐式数据扩充(Implicit data augmentation):MTL有效地增加了我们用于训练模型的样本量。由于所有任务或多或少存在一些噪音,因此在针对某个任务A训练模型时,我们的目标是得到任务A的一个好的表示,忽略与数据相关的噪声。由于不同的任务具有不同的噪声模式,因此同时学习两个任务的模型可以得到一个更为泛化的表示。如果仅学习任务A要承担对任务A过拟合的风险,然而同时学习任务A和任务B则可以对噪声模式进行平均,可以使模型获得更好的表示。
(2).注意力机制(Attention focusing):如果一个任务非常嘈杂或数据量有限且维数很高,则模型很难区分相关和不相关特征。MTL可以帮助模型将注意力集中在重要的特征上,因为其他任务将为这些特征的相关性或不相关性提供更多证据。
(3).窃听(Eavesdropping):一些特征G很容易被任务B学习,但是对于其他任务A则很难学习。这可能是因为A以更复杂的方式与特征进行交互,或者是因为其他特征阻碍了模型学习G的能力。通过MTL,我们可以允许模型进行”窃听”,即通过任务B学习G。最简单的方法是通过”提示”,即直接训练模型来预测最重要的特征。
(4).表征偏置(Representation bias):MTL biases the model to prefer representations that other tasks also prefer。这也将有助于该模型将来泛化到新任务,因为在足够多的训练任务上表现良好的假设空间,只要它们来自相同环境,对于学习新任务也将表现良好。
(5).正则化(Regularization):MTL通过引入归纳偏置(inductive bias)作为正则化项。因此,它降低了过拟合的风险以及模型的Rademacher复杂度,即拟合随机噪声的能力。
深度学习中的MTL:
(1). Deep Relation Networks:如下图所示:计算机视觉中,MTL通常共享卷积层,同时用全连接层学习特定的任务。通过对任务层设定先验,使模型学习任务间的关系。

(2). Fully-Adaptive Feature Sharing:如下图所示:一种自下而上的方法,从瘦网络开始,贪心地动态加宽网络。贪心方法可能无法做到全局最优。
(3). Cross-stitch Networks:如下图所示:用软约束的方式将两个独立的网络连接起来,然后使用”cross-stitch units”允许模型通过线性组合学习前一层的输出。

(4). Low supervision:主要应用在自然语言处理(Natural Language Processing, NLP)中,如词性标注、命名体识别等。
(5). A Joint Many-Task Model:如下图所示:由多个NLP任务组成分层结构,然后将其作为多任务学习的联合模型。

(6). Weighting losses with uncertainty:如下图所示:不考虑学习共享结构,采用正交方法考虑每个任务的不确定性。通过基于具有任务相关不确定性的高斯似然性最大化得出多任务损失函数(loss function),来调整成本函数(cost function)中每个任务的相对权重。

(7). Tensor factorisation for MTL:对模型中的每层参数使用张量分解分为共享参数和特定于任务的参数。
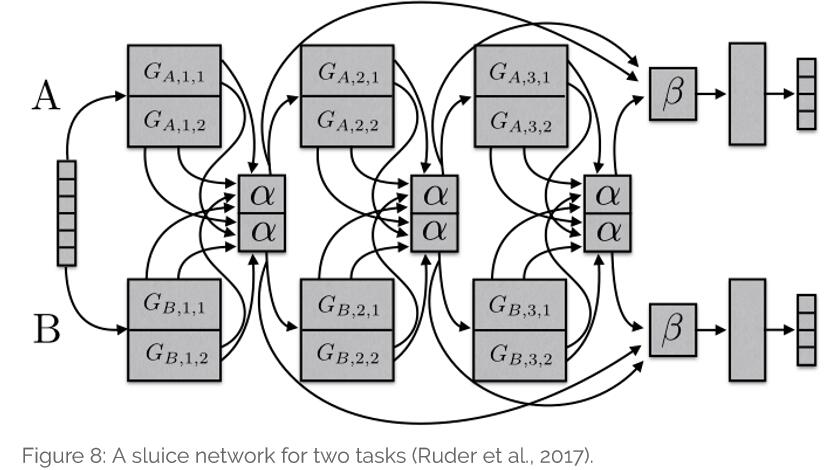
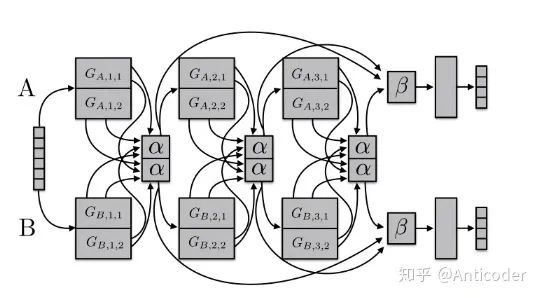
(8). Sluice Networks:如下图所示:该模型概况了基于深度学习的MTL方法:hard parameter sharing + cross-stitch networks + block-sparse regularization + task hierarchy(NLP)

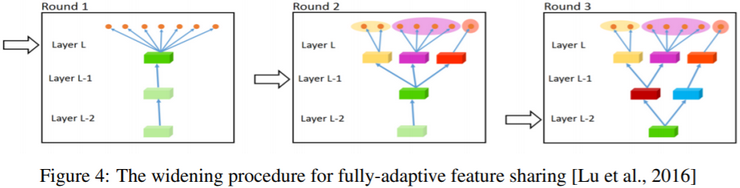
在迁移学习中,你的步骤是串行的,你从任务A中学到的,然后迁移到任务B。在多任务学习中,你是开始学习试图让一个神经网络同时做几件事情,然后希望这里的每个任务都能帮到其它所有任务。例如,在研发无人驾驶车辆,如下图,那么你的无人驾驶车可能需要同时检测不同的物体,比如检测行人、车辆、停车标志、交通灯等其它物体,输入图像x,输出将不是一个标签,而是四个标签,因为四个物体可能同时出现在一张图里。那么你现在可以做的是训练一个神经网络来预测这些y值。另外你也可以训练四个不同的神经网络,而不是训练一个神经网络做四件事,但神经网络一些早期特征在识别不同物体时都会用到,你会发现,训练一个神经网络做四件事会比训练四个完全独立的神经网络分别做四件事性能会更好,这就是多任务学习的力量。
多任务学习什么时候有意义:第一,如果你训练的一组任务,可以共用低层次特征;第二,每个任务的数据量很接近;第三,可以训练一个足够大的神经网络同时可以做好所有的工作。多任务学习的替代方法是为每个任务训练一个单独的神经网络。多任务学习会降低性能的唯一情况就是你的神经网络还不够大。
注:以上所有的内容的整理均来自网络,主要参考:
1. https://arxiv.org/pdf/1706.05098.pdf
2. 《多任务学习的研究》,2018,博论,中国科学技术大学
GitHub:https://github.com/fengbingchun/NN_Test