哎呀,要秋招了啊~
不禁感叹:How time flys~
重新出发~
后期我发现还是需要把相关文章的链接放上来的,方便大家深入理解记忆,如果你没时间就直接看文字,如果有时间记得把链接点开看看哦~都是大佬的精华~
一切为了暑期实习!!!
一切为了暑期实习!!!
一切为了暑期实习!!!
机器学习
SVM(重点)
这个文章讲的不错哟,很详细,考点也很全面!!
https://blog.csdn.net/b285795298/article/details/81977271
1. SVM原理和推导
- 原理:SVM试图寻找一个超平面使正负样本分开,并使得几何间隔最大。
⚠️(注意分清以下这三种情况)
当训练样本线性可分时,通过硬间隔最大化,学习一个线性分类器,即线性可分SVM
当训练样本近似线性可分时,引入松弛变量,通过软间隔最大化,学习一个线性分类器,即线性SVM
当训练样本线性不可分时,通过核技巧和软间隔最大化,学习一个非线性分类器,即非线性SVM
- 硬间隔SVM推导(十分重要)我自己写的,字很随意啦~

- 软间隔SVM推导
https://blog.csdn.net/Dominic_S/article/details/83002153
2. SVM为什么可以用对偶问题求解?对偶问题的解和原始问题的解的关系?这样求解的好处是?
- 首先SVM求解问题是一个凸二次规划问题(基本目标是二次函数,约束条件是线性的这种优化问题被称为凸二次优化问题),应用对偶问题求解更高效。
- 其次在满足KKT条件下,对偶问题和原始问题的解是完全等价的。
- 优点:
- 对偶问题将原始问题中的约束转为了对偶问题中的等式约束;
- 方便核函数的引入;
- 改变了问题的复杂度。由求特征向量w转化为求比例系数a,在原始问题下,求解的复杂度与样本的维度有关,即w的维度。在对偶问题下,只与样本数量有关;
- 求解更高效,因为只用求解alpha系数,而alpha系数只有支持向量才非0,其它全部为0。
3. 为什么要选择最大间隔分类器?
- 从数学上考虑:
误分类次数和几何间隔之间存在下列关系,几何间隔越大,误分类次数越少。
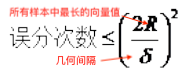
- 感知机利用误分类最小策略,求得分离超平面,不过此时解有无数个;而线性可分SVM利用间隔最大求得最优分离超平面,求得唯一解,而且此时的模型鲁棒性好,对未知样本泛化能力最强。
4. 样本失衡会对SVM的结果产生影响吗?如何解决SVM样本失衡问题?样本比例失衡时,使用什么指标评价分类器的好坏?
- 样本失衡会对结果产生影响,分类超平面会靠近样本少的类别。原因:因为使用软间隔最大化,假设对所有类别使用相同的惩罚因子,而优化目标是最小化惩罚量,所以靠近样本少的类别惩罚量少。
- 解决SVM样本失衡问题方法:
- 对不同的类别赋予不同的惩罚因子(C),训练样本越少,C越大。缺点:偏离原始样本的概率分布。
- 对样本的少的类别,基于某种策略进行采样。
- 基于核函数解决问题。
- 当样本比例不均衡时,使用ROC曲线。
5. SVM如何解决多分类问题
https://www.cnblogs.com/CheeseZH/p/5265959.html
- 直接法:直接修改目标函数,将多个分类面的参数求解合并到一个目标函数上,一次性进行求解。
- 间接法:
- One VS One:任意两个样本之间训练一个分类模型,假设有k类,则需要k(k-1)/2个模型。对未知样本进行分类时,得票最多的类别即为未知样本的类别。libsvm使用这个方法。
- One VS Rest:训练时依次将某类化为类,将其他所有类别划分为另外一类,共需要训练k个模型。训练时具有最大分类函数值的类别是未知样本的类别。
6. SVM适合处理什么样的数据?
高维、稀疏、样本少的数据。
7. SVM为什么对缺失数据敏感?(数据缺失某些特征)
- SVM没有缺失值的处理策略;
- SVM希望样本在特征空间中线性可分,特征空间的好坏影响SVM性能;
- 缺失特征数据影响训练结果。
8. sklearn.svm参数
- 栗子:
class sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', random_state=None)
- 重要参数:(理解含义和对模型的影响)
-
C : float, optional (default=1.0)误差项的惩罚参数,一般取值为10的n次幂,如10的-5次幂,10的-4次幂…10的0次幂,10,1000,1000,在python中可以使用pow(10,n) n=-5~inf
C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样会出现训练集测试时准确率很高,但泛化能力弱。
C值小,对误分类的惩罚减小,容错能力增强,泛化能力较强。 -
kernel : string, optional (default=’rbf’)
svc中指定的kernel类型。
可以是: ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ 或者自己指定。 默认使用‘rbf’ 。 -
degree : int, optional (default=3)
当指定kernel为 ‘poly’时,表示选择的多项式的最高次数,默认为三次多项式。
若指定kernel不是‘poly’,则忽略,即该参数只对‘poly’有作用。 -
gamma : float, optional (default=’auto’)
当kernel为‘rbf’, ‘poly’或‘sigmoid’时的kernel系数。
如果不设置,默认为 ‘auto’ ,此时,kernel系数设置为:1/n_features -
coef0 : float, optional (default=0.0)
kernel函数的常数项。
只有在 kernel为‘poly’或‘sigmoid’时有效,默认为0。
-
9. SVM的损失函数—Hinge Loss(合页损失函数)
https://www.jianshu.com/p/fe14cd066077
- hinge loss图像
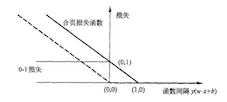
- 表达式
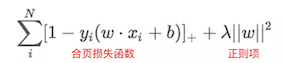
10. SMO算法实现SVM(思想、步骤、常见问题)(我这个还不熟悉,mark)
- 思想:将大的优化问题分解为多个小的优化问题,求解小的优化问题往往更简单,同时顺序求解小问题得出的结果和将他们作为整体求得的结果一致。
- 步骤:1. 选取一对需要更新的变量ai和aj(阿尔法)2. 固定除ai和aj以外的所有变量,求解对偶问题获得更新ai、aj、b。
- 常见问题—如何选取ai和aj和b?
- 选取违反KKT条件最严重的ai,在针对这个ai选择最有可能获得较大修正步长的aj;
- b一般选取支持向量求解的平均值。
11. SVM如何解决非线性问题?你所知道的核函数?
- 当样本在原始空间线性不可分时,可将样本从原始空间映射到一个更高维的特征空间,使得样本在这个特征空间内线性可分。
- 常用核函数(重点sigmoid、RBF(名字一定要记住啦:高斯径向基核函数)、要会写核函数的公式哦~)

12. 线性核与RBF核的区别?
- 训练速度:线性核只有惩罚因子一个参数,训练速度快,RBF还需要调节gamma;
- 训练结果:线性核得到的权重w能反映出特征的重要性,由此进行特征选择,RBF无法解释;
- 训练数据:线性核适合样本特征>>样本数量的,RBF核相反。(揭示了如何选择核函数)
13. SVM和LR的联系和区别
- 联系:
- 都是判别式模型
- 都是有监督的分类算法
- 如果不考虑核函数,都是线性分类算法
- 区别:
- LR可以输出概率,SVM不可以
- 损失函数不同,即分类机制不同
- SVM通过引入核函数解决非线性问题,LR则主要靠特征构造,必须组合交叉特征,特征离散化;
原因:LR里每个样本点都要参与核计算,计算复杂度太高,故LR通常不用核函数。
- SVM计算复杂,效果比LR好,适用于小数据集;LR计算快,适用于大数据集,用于在线学习
- SVM分类只与分类超平面附近的点有关,LR与所有点都有关系
- SVM是结构风险最小化,LR则是经验风险最小化
结构风险最小化就是在训练误差和模型复杂度之间寻求平衡,防止过拟合,减小泛化误差。为了达到结构风险最小化的目的,最常用的方法就是添加正则项。
14. SVM如何防止过拟合?
https://www.jianshu.com/p/9b03cac58966
通过引入松弛变量,松弛变量可以容忍异常点的存在。
15. KKT(Karysh-Kuhn-Tucker)条件有哪些,完整描述?

对应到线性可分SVM分类上其KKT条件为:

对于以上的KKT条件可以看出,对于任意的训练样本总有ai=0或者yif(xi) - 1=0即yif(xi) = 1
1)当ai=0时,代入最终的模型可得:f(x)=b,即所有的样本对模型没有贡献;
2)当ai>=0,则必有yif(xi) = 1,注意这个表达式,代表的是所对应的样本刚好位于最大间隔边界上,是一个支持向量,这就引出一个SVM的重要性质:训练完成后,大部分的训练样本都不需要保留,最终的模型仅与支持向量有关。
集成学习(重点)
1. 决策树和随机森林的区别
决策树 + Bagging + 随机选择特征 = 随机森林,随机森林可以有效防止过拟合。
2. 随机森林里面用的哪种决策树
CART 决策树或其他
3. 随机森林的原理?如何进行调参?树的深度一般如何确定,一般为多少?
- 原理:RF是一种集成算法,属于bagging类,它通过集成多个决策树模型,通过对基模型的结果采用投票法或者取平均来获得最终结果,使得最终模型有较高的准确度和泛化性能。
- 调参:
还是看刘建平老师的这篇:https://www.cnblogs.com/pinard/p/6160412.html
RF和GBDT调参过程类似,可以对比记忆:
无参数拟合–>n_estimators调参–>max_depth, min_sample_split–>min_sample_split, min_samples_leaf–>max_features
- 如何确定树的深度:当训练样本多,数据特征维度多的时候需要限制这个参数,具体取决于数据分布,一般在10-100之间。
3. Bagging 和 Boosting的区别
- 样本选择:Bagging有放回的选取训练集,并且从原始数据集中选取的各轮训练集之间相互独立;Boosting每次都使用全部数据,只是每个样例的权重不同。
- 样例权重:Bagging采用均匀采样,每个样例的权重相同;Boosting每轮训练都依据上一轮训练结果更新样例权重,错误率越大的样例,权重越大。
- 预测函数:Bagging每个基函数的预测结果权重相同;Boosting中预测误差越小的基模型有更大的权重。
- 偏差和方差:Bagging得出的结果低方差,Boosting低偏差。
- 并行计算:Bagging可以并行生成基模型,Boosting各个预测函数只能顺序生成,后一轮模型的参数需要前一轮的预测结果。
4. GBDT调参
我觉得啊,一般面试官如果问我们这种题目,一定是要求我们使用过这个算法,如果使用过就要理解记住,没使用过就坦诚的说没用过,大家可以跟着下面这个链接的刘建平老师学习一遍。
具体实例:https://www.cnblogs.com/pinard/p/6143927.html
- 参数分类:
- Boosting框架参数:n_estimators, learning_rate, subsample
- CART回归树参数(与决策树类似):max_features, max_depth, min_sample_split, min_samples_leaf
- 大致步骤:
无参数拟合–>固定learning_rate,estimators调参–>max_depth, min_sample_split–>min_sample_split, min_samples_leaf–>拟合查看–>max_features–>subsample–>不断减小learning_rate,加倍estimators来拟合
5. RF、GBDT之间的区别(重要)
此问题充分理解,你需要这些:
https://blog.csdn.net/data_scientist/article/details/79022025
https://blog.csdn.net/xwd18280820053/article/details/68927422
https://blog.csdn.net/m510756230/article/details/82051807
- 相同点:都是由多棵树组成,结果由多棵树共同决定。
- 不同点:
- GBDT是回归树,RF可以是回归树也可以是分类树;
- GBDT对异常值特别敏感,RF则没有;
- GBDT只能串行生成多个模型,RF可以并行;
- GBDT的结果有多个结果求和或者加权求和,RF是由投票选出结果;
- GBDT是通过减少偏差来提高模型性能,RF是通过减少方差;
- RF对所有训练集一视同仁,GBDT是基于权值的弱分类器。
6. 随机森林的优缺点
- 优点:
- 相比于其他算法,在训练速度和预测准确度上有很大的优势;
- 能够处理很高维的数据,不用选择特征,在模型训练完成后,能够给出特征的重要性;
- 可以写成并行化方法;
- 缺点:在噪声较大的分类回归问题上,容易过拟合。
7. GBDT的关键?GBDT中的树是什么树?
- 关键:利用损失函数的负梯度方向作为残差的近似值来拟合新的CART回归树。
- CART回归树。
8. GBDT和XGB的区别
- GBDT以CART为基分类器,XGB则支持多种分类器;
- GBDT只用到了一阶导数信息,xgboost则对代价函数进行了二阶泰勒展开,同时用到了一阶与二阶导数,并且可以自定义代价函数,只要一阶二阶可导;
- XGBoost与GDBT都是逐次迭代来提高模型性能,但是XGBoost在选取最佳切分点时可以开启多线程进行,大大提高了运行速度;
- 新增了Shrinkage和column subsampling,为了防止过拟合;
- 对缺失值有自动分裂处理(默认归于左子树);
如何处理的缺失值:
Xgboost 在处理带缺失值的特征时,先对非缺失的样本进行排序,对该特征缺失的样本先不处理,然后在遍历每个分裂点时,将这些缺失样本分别划入左子树和右子树来计算损失然后求最优。如果训练样本中没有缺失值,而预测过程中出现了缺失值,那么样本会被默认分到右子树。
- xgb损失函数加入正则化,控制模型复杂度,使模型简单,防止过拟合。
9. LGB和XGB的区别(抓住主要区别,理解要有深度)
lgb官方文档:http://lightgbm.apachecn.org/#/docs/4
https://www.cnblogs.com/infaraway/p/7890558.html
-
树的切分策略不同:
- xgb基于level-wise,对每一层节点进行无差别分裂,造成不必要的开销;
- lgb基于leaf-wise,在当前所有叶子节点中选择分裂增益最大的节点进行分裂;
-
实现并行方式不同:
- xgb使用基于 pre-sorted 决策树算法;
- lgb使用基于histogram决策树算法,对离散特征进行分裂时,特征的每个取值为一个桶;
-
lgb支持直接输入categorical feature,对类别特征无须进行one-hot处理;
-
优化通信代价不同:lgb支持特征并行、数据并行。
10. GBDT的算法步骤(我没找到推导呢)

10. 随机森林生成过程
https://www.cnblogs.com/liuwu265/p/4690715.html
- 样本集选择:从原始样本中有放回的抽取N个训练集,各个训练集之间相互独立,共进行k轮抽取;
- 决策树生成:假设特征空间共有D个特征,随机选择d个特征,构成新的特征空间,用于训练单棵决策树,共k轮,生成k棵决策树;
- 模型合成:生成的k棵决策树相互独立,各个基模型之间权重相同,如果是分类问题,则使用投票法决定最终结果,如果是回归问题,则使用平均法;
- 模型验证:模型验证本身需要验证集,但在此处我们无须额外设置验证集,只需使用原始样本中没有使用过的即可。
11. xgboost如何确定特征和分裂点的?
XGBoost使用了和CART回归树一样的想法,利用贪婪算法。基于目标函数,遍历所有特征的所有特征划分点,具体做法就是分裂后的目标函数值大于分裂之前的就进行分裂。
12. XGB是如何给出特征重要性评分的?
建议多看下以下链接:
https://blog.csdn.net/waitingzby/article/details/81610495
https://blog.csdn.net/sujinhehehe/article/details/84201415
https://www.cnblogs.com/haobang008/p/5929378.html
- 特征权重(weight):指的是在所有树中,某特征被用来分裂节点的次数;
- 如何计算:一个特征对分裂点性能度量(gini或者其他)的提升越大(越靠近根节点)其权重越大,该特征被越多提升树选择来进行分裂,该特征越重要,最终将一个特征在所有提升树中的结果进行加权求和然后求平均即可。
- 源码片段(加深理解):
主要是对每个特征进行计数操作:if importance_type == 'weight':# do a simpler tree dump to save timetrees = self.get_dump(fmap, with_stats=False)fmap = {}for tree in trees:for line in tree.split('\n'):# look for the opening square bracketarr = line.split('[')# if no opening bracket (leaf node), ignore this lineif len(arr) == 1:continue# extract feature name from string between []fid = arr[1].split(']')[0].split('<')[0]if fid not in fmap:# if the feature hasn't been seen yetfmap[fid] = 1else:fmap[fid] += 1return fmap
13. XGB如何消除残差的,目标函数是什么?
https://www.cnblogs.com/palantir/p/10671119.html
https://blog.csdn.net/guoxinian/article/details/79243307

14. GDBT在处理分类和回归问题时有什么区别?(感觉还有补全的地方)
损失函数不同:
- 分类:指数、对数;
- 回归:均方差、绝对值。
15. XGB如何防止过拟合
- 损失函数中包含正则化项;
- Shrinkage and Column Subsampling。
- Shrinkage方法就是在每次迭代中对树的每个叶子结点的分数乘上一个缩减权重η,这可以使得每一棵树的影响力不会太大,留下更大的空间给后面生成的树去优化模型;
- Column Subsampling类似于随机森林中的选取部分特征进行建树。其可分为两种:
- 按层随机采样,在对同一层内每个结点分裂之前,先随机选择一部分特征,然后只需要遍历这部分的特征,来确定最优的分割点;
- 随机选择特征,则建树前随机选择一部分特征然后分裂就只遍历这些特征。一般情况下前者效果更好。
为什么GBDT中使用cart回归树
GBDT是一种基于前向策略的加法模型, 每阶段使用一个基模型去拟合上一阶段基模型的残差. 残差是连续值, 因此用到的是回归树。
EM算法
1. 采用EM算法求解的模型有哪些?为什么不用牛顿法或者梯度下降法?(感觉第二个问题有点错误,mark)
- 高斯混合模型、协同过滤、KMeans
- 求和的项随着隐变量的数量随指数上升,梯度计算带来麻烦,而EM是非梯度优化算法。
2. 用EM算法推导解释KMeans
KMeans中,每个聚类簇的中心就是隐含变量。
E步:随机初始化k个聚类中心
M步:计算每个样本点最近的质心,并将他聚类到这个质心
重复以上两步,直到聚类中心不发生变化为止。
决策树
1. ID3和C4.5的优缺点
| ID3 | C4.5 | |
|---|---|---|
| 优点 | 实现简单 | 1. 可以处理连续型特征 2. 易于理解,准确率高 |
| 缺点 | 1. 只能处理离散特征 2. 倾向于选择取值较多的特征 | 1. 在构造树的过程中,对数据多次扫描排序,低效 2. 只能够用于驻留在内存中的数据,当数据大到无法在内存容纳时,程序无法执行 |
2. 决策树处理连续值的方法
连续属性离散化,常用的离散化策略是二分法(C4.5):

3. 决策树的剪枝策略
- 目的:简化决策树模型,提高模型泛化能力;
- 基本思想:减去某些子树和叶节点,将其根节点作为新的叶子节点,实现简化模型。
- 损失函数:

- 剪枝策略:
- 预剪枝:在构造决策树的过程中,在对节点划分之前进行估计,若划分后不能带来决策树性能和泛化能力的提升,则不进行划分,并将此节点作为叶节点。
- 后剪枝:构造完决策树之后,自底向上搜索,对每个非叶节点进行考察,若将该子树去除变为叶节点能带来决策树泛化性能的提升,则将该节点作为叶节点。
- 对比:后剪枝的分支比预剪枝的分支要多一些,不容易欠拟合,泛化能力强,但是由于后剪枝在构造完成决策树之后,而且还需要自底向上进行搜索故时间开销大。
4. 决策树的构造过程
https://shuwoom.com/?p=1452
- 特征选择:在所有特征中选择一个特征,作为当前节点的划分标准:ID3(信息增益)、C4.5(信息增益比)、CART(gini系数);
- 决策树生成:依据特征评估标准,从上到下的递归的生成子节点,直到数据集不可分时,停止生长;
- 剪枝:决策时容易过拟合,通过剪枝,简化模型,降低过拟合。
5. 基于树的模型有必要做标准化吗?
https://blog.csdn.net/answer3lin/article/details/84961694
不必要;概率模型(树模型)不关系变量的值,只关心变量的分布和变量之间的条件概率。
6. CART回归树和CART决策树的构造过程
特征选择+决策树构造+决策树剪枝
- cart回归树
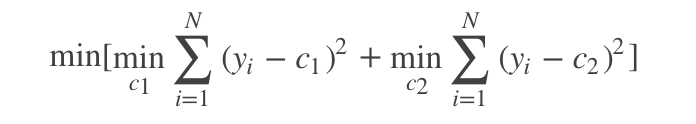
cart回归树对某个特征的每个分量,将数据集划分为大于该分量和小于该分量两部分,同时计算对应y的均值,并计算均方误差函数的值,选择具有最小误差值的分量,并将其作为划分标准,重复该流程知道数据集为空或者前后均方误差下降值小于给定阈值则停止。 - cart分类树
选择具有最小的GINI系数的属性和属性值,作为最优分裂属性和最优分裂属性值。
7. 熵
- 概念:信息所包含不确定大小的度量,一个信息的所包含的不确定性越大,其所含的信息越多。
- 计算题:
https://blog.csdn.net/guomutian911/article/details/78599450
熵的计算公式: H ( X ) = − ∑ i = 1 N p i l o g 2 p i H(X) = -\sum_ {i=1}^{N}p_i log_2 p_i H(X)=−∑i=1Npilog2pi
信息增益 = 划分前的熵 - 划分后的熵
朴素贝叶斯
1. 朴素贝叶斯的公式
“朴素”的含义:假设各个特征之间相互独立。

2. NB原理及其分类
- 原理:基于贝叶斯定理与特征条件独立假设的分类方法,首先基于特征条件独立假设学习输入/输出的联合概率分布,然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y。
- 分类:(根据变量的分布不同)
- NB的伯努利模型,特征是布尔变量,符合0/1分布,在文本分类中,特征就是词是否出现;
- NB的多项式模型,特征是离散值,符合多项式分布,在文本分类中,特征就是词出现的次数;
- NB的高斯模型,特征是连续值,符合高斯分布(高斯分布又名正态分布),在文本分类中,特征就是词的TF-IDF值。
3. NB的优缺点
- 优点:
- 算法原理简单;
- 所估计的参数少;
- 假设条件概率计算是彼此独立的,因此可以用于分布式计算;
- 属于生成式模型,收敛速度比判别式模型要快;
- 对缺失数据不太敏感;
- 天然可以处理多分类问题。
- 缺点:
- 假设各个特征之间相互独立这一条件在实际应用中往往是不能成立的;
- 不能学习到特征之间的相互作用;
- 对输入数据的表达形式敏感。
4. LR和朴素贝叶斯(NB)之间的区别
https://www.cnblogs.com/wangkundentisy/p/9193217.html
暂时不看。
5. 适用场景
- 支持大规模数据,并且支持分布式实现;
- 特征维度可以很高;
- 可以处理数值型特征和类别型特征;
6. 先验概率、后验概率和似然估计
- 先验概率:
事情还没有发生,根据以往的经验来判断事情发生的概率。是“由因求果”的体现。 - 后验概率:
事情已经发生了,有多中原因,判断事情的发生是由哪一种原因引起的。是“由果求因”。 - 似然估计:
根据原因推测该原因导致结果发生的概率。
线性回归与逻辑回归
1. LR推导(重要)

几个小问题:
- 极大似然的概念:找到参数θ的一个估计值,使得当前样本出现的可能性最大。
- 为什么极大似然的时候可以相乘:特征之间是独立同分布。
- LR的参数计算方法:梯度下降、牛顿法。
- 为什么我们要在LR的损失函数中手动添加一个负号呢?
为了应用梯度下降法,引入的。不加负号也可以,即使用梯度上升法。
2. 逻辑回归和线性回归的区别
| 线性回归 | 逻辑回归 |
|---|---|
| 对连续值预测 | 分类 |
| 最小二乘法 | 最大似然估计 |
| 拟合函数 | 预测函数 |
3. 最小二乘法和最大似然法的区别(没太明白,mark)
https://blog.csdn.net/lu597203933/article/details/45032607
4. 为什么用最小二乘而不是最小四乘(没太明白,mark)

5. 介绍一下逻辑回归?它的损失函数是什么?
- 一句话介绍逻辑回归:逻辑回归假设数据服从伯努利分布,通过极大化似然函数估计损失函数,利用梯度下降算法来求得参数,实现数据的二分类;
- 它的损失函数是对数损失函数:

6. LR 损失函数为什么用极大似然函数?
https://blog.csdn.net/aliceyangxi1987/article/details/80532586
- LR的目标是使每个样本的预测都有最大概率,即将所有样本预测后的概率相乘概率最大,这就是极大似然函数;
- 极大似然函数取对数即为对数损失函数,对数损失函数的训练求解参数比较快,更新速度也稳定;
LR为什么不用平方损失函数
https://blog.csdn.net/Beyond_2016/article/details/80030407
- 因为逻辑回归是分类算法,输出值y是离散的,而且是二值的,只有0或者1,用对数损失函数更直观;
- 平方损失函数是非凸的,不容易求解,很容易陷入局部最优,如果使用对数似然函数,可以证明它是关于(w,b)的高阶连续可导凸函数,可以方便通过一些凸优化算法求解,比如梯度下降法、牛顿法等。(证明方法见这博客:https://blog.csdn.net/u012421852/article/details/79620810)
7. LR的参数计算方法:梯度下降法,请介绍三种GD的区别
多看:https://www.cnblogs.com/wyuzl/p/7645602.html
https://blog.csdn.net/ai_bigdata_wh/article/details/78013783
- 批梯度下降:可以得到全局最优解,缺点是更新每个参数都需要遍历所有数据,计算量大,还有很多冗余计算,在数据非常大的时候,每个参数的更新都是非常慢的;
- SGD:随机梯度下降是小批量梯度下降的一个极端:m=1,即每次更新时只用训练集中的一个样本来计算梯度,将参数更新时所需的梯度计算量大大地降低,保证了较高的更新效率。SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向。
- mini-batch SGD:结合了二者的优点,每次选取N个样本,减少了参数更新的次数,可以达到更加稳定的收敛结果。
8. LR的优缺点
http://www.cnblogs.com/ModifyRong/p/7739955.html
-
优点:
- 形式简单,模型可解释性非常好,特征权重可以看出不同特征最后结果的影响;
- 效果不错,可以作为baseline;
- 占用资源少,特别是内存;
- 方便输出结果调整;
- 训练速度快。
-
缺点:
- 准确率不高;
- 对样本不均衡问题无法很好的解决;
- 对非线性分类问题也是;
- 本身无法筛选特征,可以和GBDT结合使用。
9. 逻辑斯特回归为什么要对特征进行离散化
- 稀疏向量做内积乘法运算速度快,计算结果方便存储,易于扩展
- 离散化后的特征对异常数据有更强的鲁棒性
- 特征离散化后模型更稳定
- LR属于广义线性模型,表达能力有限,特征离散化为N个后,每个变量有自己的权重,相当于引入非线性,表达能力增强,加大拟合
- 特征离散化后还可以做特征交叉,由M+N个变为M*N个,进一步引入非线性
10. LR为什么用sigmoid函数,这个函数有什么优点和缺点?
- 为什么:
- Sigmoid 函数自身的性质
- sigmoid 函数连续,单调递增
- sigmiod 函数关于(0,0.5) 中心对称
- 计算sigmoid函数的导数非常的快速
- 将输入变量的范围从负无穷到正无穷,映射到(0,1),而概率要求正是(0,1)。
- 逻辑回归认为函数其概率服从伯努利分布,将其写成指数族分布的形式,能够推导出sigmoid函数的形式。
- Sigmoid 函数自身的性质
https://blog.csdn.net/a1628864705/article/details/62233395
https://blog.csdn.net/qq_19645269/article/details/79551576
- 优缺点:
- 优点:
- 可以看到sigmoid函数处处连续 ->便于求导;
- 可以将函数值的范围压缩到[0,1]->可以压缩数据,且幅度不变;
- 便于前向传输。
- 缺点:
- 在趋向无穷的地方,函数值变化很小,容易缺失梯度,不利于深层神经网络的反馈传输;
- 幂函数还是比较难算的;
- 函数均值不为0,当输出大于0时,则梯度方向将大于0,也就是说接下来的反向运算中将会持续正向更新;同理,当输出小于0时,接下来的方向运算将持续负向更新。
- 优点:
11. LR伪代码
读取文件、写入文件以及计算准确率等之前实验做过的或者过于简单的函数功能不列出。
int main()
{读取训练集和测试集,其中训练集每三个样本取前两个作为训练集,第三个作为验证集。初始化w:for(int i=0;i<Length;i++) w[i]=1;for(int k=0:7)for(int i=0:traincnt)//遍历训练集样本{CalWeight(i);//计算样本i的权重分数CalCost(i);//每一维的梯度(代价)计算Updatew(); //更新wif(i%20==0) //每更新w20次计算一次准确率{Predict();//预测验证集样本Cal_acc();//计算准确率 ac[cnt]=accuracy; cnt++;} }output_result();//输出验证集准确率以供调试output_test_result();//输出测试集预测结果
}
void CalWeight(int index){weight = 当前向量w的转置*样本i向量;
}
void CalCost(int index){计算每一维的梯度,存储在向量数组Cost[]中;
}
void Updatew(){使用w = w - alpha x gradient来更新回归系数(w)
}
void Predict(){P = 1/(1+exp(-1* w^T *样本i向量);if(P>0.5) p_label=1;else p_label=0;
}
PCA
1. PCA原理
具体推导看这里: https://blog.csdn.net/u012421852/article/details/80458340
- 用于:特征降维,去除冗余和可分性不强的特征;
- 目标:降维后的各个特征不相关,即特征之间的协方差为0;
- 原理:基于训练数据X的协方差矩阵的特征向量组成的k阶矩阵U,通过XU得到降维后的k阶矩阵Z;
- 算法步骤
- 计算训练样本的协方差矩阵C;
- 计算C的特征值和特征向量;
- 将C的特征值降序排列,特征值对应特征向量也依次排列;
- 假如要得到X的k阶降维矩阵,选取C的前k个特征{u1,u2…uk},组成降维转换矩阵U;
- Z = XU,Z即为降维后的矩阵;
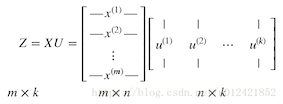
KMeans
1. K-means 的原理,时间复杂度,优缺点以及改进
- 原理:对于给定样本集,按照样本之间的距离大小,将样本划分为若干个簇,使簇内距离尽可能小,簇间距离尽可能大;
- 步骤:
- 随机选择k个样本作为初始聚类中心;
- 计算样本到各聚类中心的距离,把它划到距离最小的簇;
- 计算新的聚类中心;
- 迭代,直至聚类中心未更新或到达最大次数。
- 时间复杂度:O(knd*t) | k:类别,n:样本数,d:计算样本之间距离的时间复杂度,t:迭代次数;
- 优缺点:
- 优点:1. 原理易懂、实现简单、收敛速度快、效果好 2. 可解释性强 3. 可调参数只有少,只有k;
- 缺点:1. 聚类效果受k值影响大 2. 非凸数据集难以收敛 3. 隐含类别不均衡时,效果差 4. 迭代算法,得到的只是局部最优 5. 对噪音和异常数据敏感。
- 改进:随机初始化K值影响效果 + 计算样本点到质心的距离耗时这两方面优化
KMeans++算法
KMeans随机选取k个点作为聚类中心,而KMeans++采用如下方法:
假设已经选取好n个聚类中心后,再选取第n+1个聚类中心时,距离这n个聚类中心越远的点有越大的概率被选中;选取第一个聚类中心(n=1)时也是需要像KMeans一样随机选取的。
2. K-means聚类个数选择
https://blog.csdn.net/weixin_39875181/article/details/78601403
由于KMeans的聚类效果评估函数是SSE(和方差),即计算所有点到聚类中心距离差的平方和,K越大,SSE越小,我们要做的就是求出随着K值变化,SSE的变化规律,找出SSE减幅最小的K值。
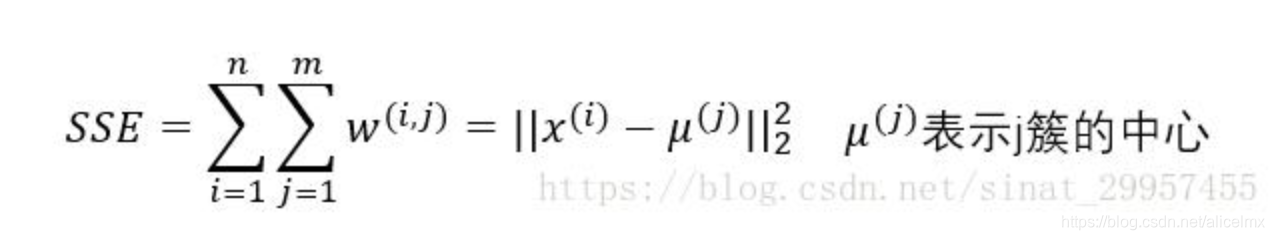
其他
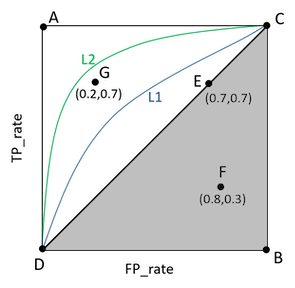
1. 机器学习性能评价指标
- Precision (精确率)和Recall(召回率)
你给出的结果多少是正确的:P = TP / (TP + FP)
有多少正确的结果,被你给出了:R = TP / (TP + FN)
注意区分准确率和精确率:
准确率(accuracy) = 预测对的/所有 = (TP+TN)/(TP+FN+FP+TN) - F1值
F1 = 2PR / (P + R) - ROC 和 AUC
2. 奥卡姆剃刀(Occam’s Razor)
如无需要,勿增实体。
简单有效原理。
具体到机器学习上,能够拟合数据的简单模型才是我们需要的。
3. L1范数与L2的作用,区别
在机器学习中,通常损失函数会加上一个额外项,可看作损失函数的惩罚项,是为了限制模型参数,防止过拟合。
(自己注意下图!)
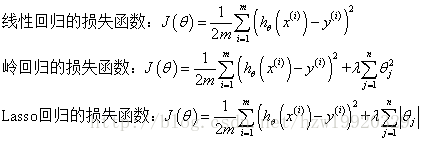
| L1范数 | L2范数 |
|---|---|
| 各个参数的绝对值之和 | 各个参数的平方和的开方 |
| 先验分布是拉氏分布 | 高斯(正态)分布 |
| 使参数稀疏化,有特征选择的功能 | 使参数接近于0,防止过拟合 (模型越简单,越不容易过拟合) |
| Lasso回归 | Ridge回归 |
4. L1正则为什么可以把系数压缩成0?
https://blog.csdn.net/jinping_shi/article/details/52433975

5. 正则化为什么能防止过拟合?添加正则项后依旧过拟合如何调节参数lambda?
4. 过拟合的原因和防止过拟合的方法
- 原因:1. 数据有噪声; 2. 训练数据不足,有限的训练数据; 3. 过度训练导致模型复杂。
- 防止过拟合的方法:
- 早停止:在模型对训练数据迭代收敛之前停止迭代。
具体做法:在每一个Epoch结束时,计算validation_data的accuracy,当accuracy不再提高时,就停止训练。(注意多次观察,多次精度未提升时则停止迭代)
- dropout:在训练时,以一定的概率忽略隐层中的某些节点。
插播:为什么dropout能有效防止过拟合,请解释原因?
详细解答看这个:https://www.cnblogs.com/wuxiangli/p/7309501.html- 取平均的作用;
- 减少神经元之间复杂的共适应关系:因为dropout程序导致两个神经元,不一定每次都在一个网络中出现,避免了有些特征只有在特定特征条件下才有效的情况,迫使网络去学习更加鲁棒的特征。
- 正则化
- 数据集扩充:1. 从源头上获取更多数据;2. 数据增强(通过一定规则扩充数据);3. 根据当前数据估计分布参数,利用该分布获得更多数据。
- 集成学习
- 早停止:在模型对训练数据迭代收敛之前停止迭代。
5. 特征选择的方法
什么样的特征是好特征:特征覆盖率高,特征之间相关性小,不能改变原始特征分布
- wrapper(根据目标函数,每次选择若干特征,活着排除若干特征)
递归特征消除法:使用基模型进行多轮训练,每轮训练结束后,消除若干权值系数的特征,再使用新的特征进行下一轮训练。 - embedded(先使用某些机器学习算法训练模型,得到各个特征的权值系数,再有大到小进行特征选择)
- 基于惩罚项的特征选择法
- 基于树的特征选择法
- filter(根据发散性活着相关性对各个特征进行评分,设定阈值或者特征个数,选择特征)
- 卡方检验
- 互信息
- 方差选择法:计算每个特征的方差,根据阈值,选择方差大于阈值的特征进行训练;
- 相关系数
6. 说一说你知道的损失函数
- 0-1损失函数(感知机)
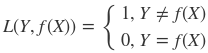
- 平方损失函数(线性回归)
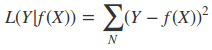
- 绝对值损失函数
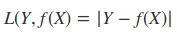
- 指数损失函数(adaBoost)
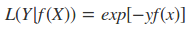
- Hinge Loss(SVM)
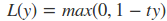
- 对数损失函数(逻辑回归)
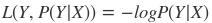
7. 数据预处理的方法
- 数据清洗:异常值和缺失值;
- 数据集成:实体识别,冗余属性识别;
- 数据转换:简单函数转换,连续特征离散化,规范化,构造属性
- 数据规约:数值规约,属性规约
8. 偏差和方差是什么,高偏差和高方差说明了什么
- 偏差:是指预测值和真实值之间的差,偏差越大,预测和真实值之间的差别越大,衡量模型的预测能力。
- 方差:描述预测值的变化范围和离散程度,方差越大,表示预测值的分布越零散,对象是多个模型,使用不同的训练数据训练出的模型差别有多大。
- 当训练误差和交叉验证误差或测试误差都很大,且值差不多时,处于高偏差,低方差,欠拟合状态;当训练误差和交叉验证误差差别很大,且测试集误差小,验证集误差大时,处于高方差,低偏差,过拟合状态。
9. 优化算法有那些?
具体算法原理、优缺点看这个:https://www.cnblogs.com/xinbaby829/p/7289431.html
梯度下降法、牛顿法和拟牛顿法、共轭梯度法、
启发式方法、解决约束优化问题的拉格朗日乘数法
10. 梯度下降算法和牛顿法的区别
https://www.cnblogs.com/lyr2015/p/9010532.html
- 牛顿法:
- 通过求解目标函数一阶导数为0的参数来求解目标函数最小值时的参数;
- 收敛速度快;
- 迭代过程中,海森矩阵的逆不断减小,相当于逐步减小步长;
- 海森矩阵的逆,计算复杂,代价较高,因此有了拟牛顿法。
- 梯度下降算法:
- 通过梯度方向和步长,直接求得目标函数最小值的参数;
- 越靠近最优值,步长应该逐渐减小,否则会在最优值附近震荡。
11. 如何解决类别不均衡问题?
https://blog.csdn.net/program_developer/article/details/80287033
https://www.cnblogs.com/zhaokui/p/5101301.html
- 采样:其中采样又分为上采样(将数量少的类别的数据复制多次),和下采样(将数量多的类别的数据剔除一部分)。
https://www.jianshu.com/p/9a68934d1f56
smote算法:
- 用途:合成新的少数样本;
- 基本思路:对每一个少数样本a,从a的k个最近邻中随机挑选一个样本b,从a、b连线上随机选择一个点,作为新合成的少数样本。
- 步骤:
1)对每一个少数样本a,基于欧式距离,计算它到其他少数样本的距离,找到他的k个最近邻;
2)根据样本不平衡比例设置一个采样比例进而得到采样倍率N,对于每一个少数样本a,从他的最近邻中选择若干样本,假设选择的样本为b;
3)基于以下公式得到新合成的少数样本 c = a * random(0,1)*|b-a|。
- 数据合成:利用现有的数据的规律生成新的数据。
- 一分类:当数据样本极不平衡时,将它看作一分类,这样我们的重点就在于将它看成对某种类别进行建模。
- 对不同的类别给予不同的分错代价。
12. 梯度下降算法的过程
首先我们有一个可微分的函数,这个函数就好像一个山,我们的目标是找到函数的最小值(即山底)。根据经验可知,我们从最陡峭的地方走,可以尽快到达山底。对应到函数就是找到给定点的梯度,并且沿着梯度相反的方向就能让函数值下降最快(因为梯度方向就是函数值变化最快的方向)。重复利用这个方法,反复求取梯度,最后就能到达局部最小值。
13. 为什么我们还是会在训练的过程当中将高度相关的特征去掉?
- 使得模型的解释性更强;
- 大大提高训练速度。
14. 最大似然估计与贝叶斯估计的区别
15. 判别式和生成式的算法各有哪些,区别是什么?
https://blog.csdn.net/amblue/article/details/17023485
https://blog.csdn.net/qq_41853758/article/details/80864072
- 区别:二者最本质的区别是建模对象的不同。
判别式模型的评估对象是最大化条件概率P(Y|X)并对此进行建模,特点是准确率高;
生成式模型的评估对象是最大化联合概率P(X,Y)并对此进行建模,特点是收敛速度快。 - 判别式模型:线性回归、决策树、支持向量机SVM、k近邻、神经网络等;
- 生成式模型:隐马尔可夫模型HMM、朴素贝叶斯模型、高斯混合模型GMM、LDA。
16. 最大似然估计
https://www.cnblogs.com/zyxu1990/p/3209407.html
- 条件:假设样本独立同分布;
- 目标:估计出这个分布中的参数theta;
- 方法:这一组样本的概率最大时就对应了该模型的参数值。

17. 请用一句话说明AUC的本质和计算规则?AUC高可以理解为精确率高吗?
- 本质:一个正例,一个负例,预测为正例的概率值大于预测为负的概率值的可能性;
计算规则:ROC曲线下的面积:
AUC = ∫ t = ∞ − ∞ y ( t ) d x ( t ) \text{AUC} = \int_{t=\infty}^{-\infty} y(t) d x(t) AUC=∫t=∞−∞y(t)dx(t) - 不可以,精确率是基于某个阈值进行计算的,AUC是基于所有可能的阈值进行计算的,具有更高的健壮性。AUC不关注某个阈值下的表现如何,综合所有阈值的预测性能,所以精确率高,AUC不一定大,反之亦然。
参考:https://blog.csdn.net/legendavid/article/details/79063044
18. 二分类时,为什么AUC比accuracy更常用?为什么AUC对样本类别比例不敏感?
19. 如何绘制ROC曲线?
https://www.cnblogs.com/zjutzz/p/9315350.html
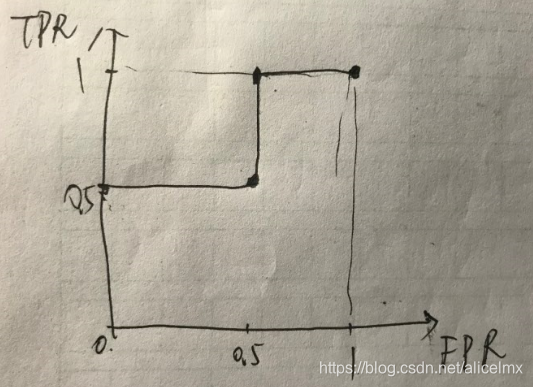
以真正例率为纵坐标,假正例率为横坐标绘制的曲线。
TPR = TP /(TP + FN)真
FPR = TN / ( TN + FP) 假
举个栗子:
gt: [0, 1, 0, 1].
pred: [0.1, 0.35, 0.4, 0.8]
那么在阈值分别取{0.1, 0.35, 0.4, 0.8}的时候,分别判断出每个pred是TP/FP/TN/FP中的哪个,进而得出当前阈值下的TPR和FPR,也就是(FPR, TPR)这一ROC曲线图上的点;对于所有阈值都计算相应的(FPR, TPR),则得到完整的ROC曲线上的几个关键点,再连线(稍微脑补一下?)就得到完整ROC曲线。(再进一步,AUC也可以计算了,不是嘛?)

20. 梯度下降的改进算法有哪些?梯度消失的概念?
如何解决梯度下降法陷入局部最优的问题?
参考 https://blog.csdn.net/maqunfi/article/details/82634529
- 使用随机梯度下降法替代真正的梯度下降算法;
- 设置冲量;
- 使用不同的初始权值进行训练。
21. VC维的理解
这个感觉不太可能会碰到~
https://www.cnblogs.com/wuyuegb2312/archive/2012/12/03/2799893.html
- 分散:对于一个给定集合S={x1, … ,xd},如果一个假设类H能够实现集合S中所有元素的任意一种标记方式,则称H能够分散S。
- VC维的定义:H的VC维表示为VC(H) ,指能够被H分散的最大集合的大小。若H能分散任意大小的集合,那么VC(H)为无穷大。
22. 判断模型线性与非线性
https://zhuanlan.zhihu.com/p/37866896
只需要判别决策边界是否是直线,也就是是否能用一条直线来划分,如果可以则为线性。