机器学习
回归和分类的相同点和不同点?
相同点:都是对输入做预测,属于有监督学习。
不同点:输出不同、目的不同、结果不同。
分类的输出是离散的、是所属类别、是定性的,回归的输出是连续的、是值、是定量的。
分类的目的是为了寻找决策边界,回归的目的是找到最优拟合。
分类的结果是确定的,回归的的结果是对真实值的逼近预测。
随机森林和GDBT的相同点和不同点?
相同点:都是由多棵树组成,最终的结果都是由多棵树一起决定。
不同点:
随机森林采取的是Bagging思想,即采用有放回的均匀取样,GDBT采用的是Boosting思想,即根据有放回的根据错误率来取样(Boosting初始化时对每一个训练样例赋相等的权重1/n,然后用该算法对训练集训练t轮,每次训练后,对训练失败的样例赋以较大的权重),因此Boosting的分类精度要优于Bagging。
组成随机森林的树可以是分类树和回归树,GDBT只能是回归树。
组成随机森林的树是并行生成,GDBT是串行生成。
随机森林采用多数投票得到最终结果(回归是对输出值进行简单平均,分类是对输出值进行简单投票),GDBT采用累加或加权的方式得到最终结果。
随机森林对异常值不敏感,GDBT对异常值敏感。
随机森林对训练集一视同仁,GDBT是基于权值的弱分类器的集成。
随机森林通过减少模型方差提高性能,GBDT是通过减少模型偏差提高性能。
GDBT和XGBoost的联系和不同点?
GBDT是机器学习算法,XGBoost是该算法的工程实现。
正则项: 在使用CART作为基分类器时,XGBoost显式地加入了正则项来控制模型的复杂度,有利于防止过拟合,从而提高模型的泛化能力。
导数信息: GBDT在模型训练时只使用了代价函数的一阶导数信息,XGBoost对代价函数进行二阶泰勒展开,可以同时使用一阶和二阶导数。
基分类器: 传统的GBDT采用CART作为基分类器,XGBoost支持多种类型的基分类器,比如线性分类器。
子采样: 传统的GBDT在每轮迭代时使用全部的数据,XGBoost则采用了与随机森林相似的策略,支持对数据进行采样。
缺失值处理: 传统GBDT没有设计对缺失值进行处理,XGBoost能够自动学习出缺失值的处理策略。
并行化: 传统GBDT没有进行并行化设计,注意不是tree维度的并行,而是特征维度的并行。XGBoost预先将每个特征按特征值排好序,存储为块结构,分裂结点时可以采用多线程并行查找每个特征的最佳分割点,极大提升训练速度。
随机森林和XGBoost的损失函数有什么不同?
分类RF对应的CART分类树默认是基尼系数gini,另一个可选择的标准是信息增益;回归RF对应的CART回归树默认是均方差mse,另一个可以选择的标准是绝对值差mae。
boosting类算法的损失函数的作用: Boosting的框架, 无论是GBDT还是Adaboost, 其在每一轮迭代中, 根本没有理会损失函数具体是什么, 仅仅用到了损失函数的一阶导数通过随机梯度下降来参数更新。
二阶导数:GBDT在模型训练时只使用了代价函数的一阶导数信息,XGBoost对代价函数进行二阶泰勒展开,可以同时使用一阶和二阶导数。
牛顿法梯度更新:XGBoost是用了牛顿法进行的梯度更新。通过对损失进行分解得到一阶导数和二阶导数并通过牛顿法来迭代更新梯度。
基于python三方模型库xgboost调参,调整“objective”参数可选损失函数。
“ binary:logistic ”:用于二进制分类的 XGBoost 损失函数。
“ multi:softprob “:用于多类分类的 XGBoost 损失函数。
“reg:squarederror”:回归预测建模问题的损失函数。
随机森林的随机性表现在哪几个方面?
数据集随机选取:从原始的数据集中采取有放回的抽样(bagging),构造子数据集,子数据集的数据量是和原数据集相同的。不同子数据集的元素可以重复,同一个子数据集中的元素也可以重复。
特征随机选取:随机森林中的子树的每一个分裂过程并未用到所有的待选特征,而是从所有的待选特征中随机选取一定的特征,之后再在随机选取的特征中选取最优的特征。
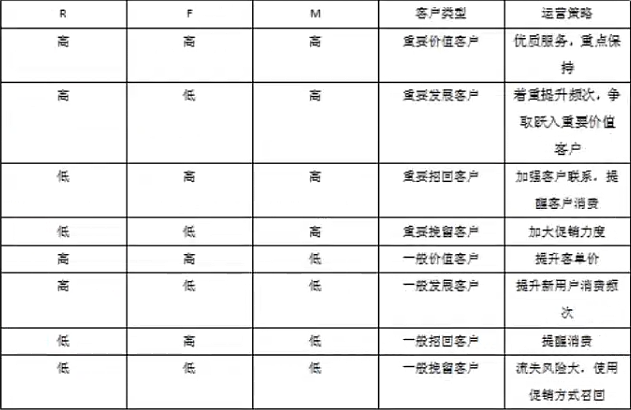
对于RFM模型的理解?
R(Recency):最近一次消费的时间。
F(Frequency): 某段时间内消费的频率次数。
M(Monetary): 某段时间内消费的金额。
可以先计算出来R、F、M三个值的平均值,然后对客户的每个维度与该维度的平均值进行比较,如果超出平均值就是高,否则就是低。
衡量聚类结果的标准是什么?
内部评估法是不借助于外部信息,仅仅只是根据聚类结果来进行评估,常见的有轮廓系数(Silhouette Coefficient)、Calinski-Harabasz Index等
外部评估方法是指在知道真实标签(ground truth )的情况下来评估聚类结果的好坏,例如纯度(Purity)、兰德系数(Rand Index, RI)、F值(F-score)和调整兰德系数(Adjusted Rand Index,ARI)。
kmeans算法的原理?
随机选取k个点,作为聚类中心;
计算每个点分别到k个聚类中心的聚类,然后将该点分到最近的聚类中心,这样就行成了k个簇;
再重新计算每个簇的质心(均值);
重复以上2~4步,直到质心的位置不再发生变化或者达到设定的迭代次数。
XGBoost算法的原理?
构造目标函数。
将目标函数进行泰勒二阶展开。
将目标函数参数化,将树结构引入目标函数。
根据最优目标函数,构建最优树。
jieba分词的原理?
依据统计词典(模型中这部分已经具备,也可自定义加载)构建统计词典中词的前缀词典。
依据前缀词典对输入的句子进行DAG(有向无环图)的构造。
使用动态规划的方法在DAG上找到一条概率最大路径,依据此路径进行分词。
对于未收录词,使用HMM(隐马尔克夫模型)模型,用Viterbi(维特比)算法找出最可能出现的隐状态序列。
参考链接:
https://zhuanlan.zhihu.com/p/189410443
特征选择的依据?
特征选择主要有过滤器,包装器和嵌入式。
filter(过滤器):
卡方检验:检验定性变量对定性因变量的相关性。适用于分类问题的分类变量;
信息增益:衡量标准是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。适合用来做所谓“全局”的特征选择(指所有的类都使用相同的特征集合),而无法做“本地”的特征选择(每个类别有自己的特征集合,因为有的词,对这个类别很有区分度,对另一个类别则无足轻重)。
相关系数法:首先要检验相关系数的显著性,相关系数显著,再去看相关系数的大小。如果相关系数不显著,意味着相关系数可能是随机因素造成的,再次测试其效果可能不一样。
方差选择法:方差主要衡量一个变量的离散程度,变量的方差越大,我们认为该变量包含的有效信息越多。反之,如果变量的方差趋向于0,说明该变量不包含有用的信息。
Wrapper (包装器)
将子集的选择看作是一个搜索寻优的问题,生成不同的组合,然后对组合进行评价,再与其他的组合进行比较。
逐步回归法(Stepwise regression):
向前选择(Forward selection):
向后选择(Backward selection)
Embedded(嵌入法)
先使用机器学习的算法进行训练,得到各个特征的权重值系数,根据系数从大到小选择特征。
正则化
决策树
线性模型
模型评价标准有哪些?分别用在什么类型的算法里?
混淆矩阵
指标 | T(预测正类) | F(预测负类) |
Positive(正类) | TP | FP |
Negative(负类) | TN | FN |
分类模型评估指标
Accuracy(准确率):(TP+TN)/(TP+FN+FP+TN),即正确预测的正反例数 /总数。
Precision (精确率/查准率):TP/(TP+FP),即正确预测的正例数 /预测正例总数。
Recall (召回率/查全率):TP/(TP+FN),即正确预测的正例数 /实际正例总数。
F-score :2*Precision*Recall/(Precision+Recall),主要评估模型稳健性。
ROC曲线:根据阈值界定正负例,根据分类结形成的曲线,横坐标为False Positive Rate(FPR假正率),纵坐标为True Positive Rate(TPR真正率)。ROC曲线越接近左上角,该分类器的性能越好。而且一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting。
AUC曲线:ROC曲线下的面积(ROC的积分),通常大于0.5小于1。
Pr曲线 :PR曲线的横坐标是精确率P,纵坐标是召回率R。
分类模型评估指标
平均绝对误差(MAE)
平均平方误差(MSE)
均方根误差(RMSE)
解释变异 (Explained variance)
决定系数R2(Coefficient of determination)
聚类模型评估指标
兰德指数
互信息
轮廓系数
多个查询的评价指标
宏平均(Macro Average):对每个查询求出某个指标,然后对这些指标进行算术平均。
微平均(Micro Average):将所有查询视为一个查询,将各种情况的文档总数求和,然后进行指标的计算。
参考链接:
https://zhuanlan.zhihu.com/p/400239526
衡量距离的方法有哪些?
欧几里得距离(欧氏距离)
余弦相似度
汉明距离
曼哈顿距离
切比雪夫距离
杰卡德指数
半正弦
参考链接:
https://zhuanlan.zhihu.com/p/405934860
对决策树的理解?
策略:自上而下,分而治之
自根至叶的递归过程, 在每个中间结点寻找一 个“划分” 属性。
开始:构建根节点;所有训练数据都放在根节点,选择-个最优特征,按着这一特征将训练数据集分割成子集,进入子节点。
所有子集按内部节点的属性递归的进行分割。
如果这些子集已经能够被基本正确分类,那么构建叶节点,并将这些子集分到所对应的叶节点去。
每个子集都被分到叶节点.上,即都有了明确的类,这样就生成了一颗决策树。
分而治之停止条件:
当前结点包含的样本全属于同一类别,无需划分;
当前属性集为空,或是所有样本在所有属性.上取值相同,无法划分;
当前结点包含的样本集合为空,不能划分.
参考链接:
https://blog.csdn.net/qingxiao__123456789/article/details/122530376
决策树中C4.5和ID3哪种是信息增益比?
ID3的衡量指标使用的是信息增益,C4.5使用的是信息增益比。
有监督、无监督、半监督、自监督、弱监督的区别?
有监督(Supervised): 监督学习是从给定的带标签训练数据集中学习出一个函数(模型参数),在输入新的测试数据时,可以根据这个函数预测结果;
无监督(Unsupervisedg): 无监督学习是从无标签数据中分析数据本身的规律性等解析特征。无监督学习算法分为两大类:基于概率密度函数估计的方法和基于样本间相似性度量的方法;
半监督:半监督介于监督学习和无监督之间,即训练集中只有一部分数据有标签,需要通过伪标签生成等方式完成模型训练;
自监督:对于无标签数据 ,通过设计 辅助任务(Proxy tasks) 来挖掘数据自身的表征特性作为监督信息,来提升模型的特征提取能力
弱监督:弱监督是指训练数据只有不确切或者不完全的标签信息,比如在目标检测任务中,训练数据只有分类的类别标签,没有包含Bounding box坐标信息。
有监督和无监督区别:使用的数据有无标签。
无监督和自监督的区别:无监督和自监督学习相似性最大,两者的训练数据都是无标签,但自监督学习会通过构造辅助任务来获取监督信息,这个过程中有学习到新的知识;而无监督学习不会从数据中挖掘新任务的标签信息。。
对过拟合和欠拟合的理解?
过拟合:训练集效果好,测试集效果差。
欠拟合:训练集和测试集效果都差。
处理过拟合:
数据层:增加训练数据,使得模型学习到更多有效的特征,减小噪声影响。
模型层面:降低模型复杂度。神经网络中减少神经层数,神经元个数;决策树中减少树的深度,剪枝等。
正则化:使用L1或者L2正则。给模型的参数加约束,避免权重值过大带来的过拟合风险。
集成学习方法:Boosting,Bagging,Stacking。
处理欠拟合:
增加新特征:但特征不足或者表现不好时就会出现欠拟合现象,通过增加新的特征,或者使用特征交叉方法等等,比如FM,GBDT,Deep Crossing等深度学习方法。
增加模型复杂度:神经网络中增加层数和单元数,线性模型增加高次项等等。
减小正则化系数
python
pandas相关
pandas有哪些窗口函数?
窗口函数
rolling:移动窗口函数
expanding:扩展窗口函数
ewm(Exponentially Weighted Moving):指数加权移动
aggragate和transform的区别?
transform 转换,需要把DataFrame中的值传递给一个函数, 而后由该函数"转换"数据。
aggregate(聚合) 返回单个聚合值,但transform 不会减少数据量(返回的是列向量)。
aggregate传入的是列向量,但是返回的是数。transform传入的是列向量,返回的也是列向量。
aggregate传入的是列向量,内部免不了的使用for循环遍历向量中的每个值,但是tarnsfrom不用。transfrom可以使用聚合函数,因为是对列向量进行操作。
目的不同:aggregate目的是拿到分组后的,有关分组的整体数据(行数变成分组后的组数)。transform目的还是拿到原有行的数据(行数不会改变),分组的目的,只不过是函数中可能要用到组有关的信息,比如组内的平均值,中位数等等。
两张表链接的函数有哪些?
join:主要用于基于索引的横向合并拼接;
merge:主要用于基于指定列的横向合并拼接;
concat:可用于横向和纵向合并拼接;
append:主要用于纵向追加;
combine:可以通过使用函数,把两个DataFrame按列进行组合。
numpy相关
numpy中的list是什么?和python原生的list有什么区别?
np.array。区别是python原生的list的值可以是不同类型,np.array的值只能是相同的类型。
python基础相关
进程、线程、协程的区别?
运行方式:
进程不能单独执行,它只是资源的集合。
进程要操作CPU,必须要先创建一个线程。
所有在同一个进程里的线程,是同享同一块进程所占的内存空间。
协程由编程者控制,协程之间可以有优先级。
关系:
进程中第一个线程是主线程,线程之间是平等的。
进程有父进程和子进程,独立的内存空间,唯一的标识符:pid。
速度:
启动线程比启动进程快。
运行线程和运行进程速度上是一样的,没有可比性。
线程共享内存空间,进程的内存是独立的。
协程几乎比线程快一个数量级
创建:
父进程生成子进程,相当于复制一份内存空间,进程之间不能直接访问
创建新线程很简单,创建新进程需要对父进程进行一次复制。
一个线程可以控制和操作同级线程里的其他线程,但是进程只能操作子进程。
协程相比与线程而言,调度损耗更小,所以真实可创建且有效的协程数量可以比线程多很多。
交互:
同一个进程里的线程之间可以直接访问。
两个进程想通信必须通过一个中间代理来实现。
协程可以控制内存占用量,灵活性更好;线程是由系统控制
线程和进程共用内存吗?
所有在同一个进程里的线程,是同享同一块进程所占的内存空间
怎么解决两个线程同时申请资源?
通过互斥锁(lock)解决数据不同步的问题。
当多个线程都对某项数据进行修改时,需要进行同步操作,线程同步能够保证多个线程安全的访问竞争资源,其中最简单的同步机制就是引入互斥锁。
互斥锁为资源引入一个状态,即锁定和非锁定。当某个线程要改共享的数据时,先将其锁定,其他进程不能进行修改,直到该线程释放资源。使用互斥锁每次只能有一个线程写入操作,从而保证了多线程的数据的正确性。
具体分为三步骤
创建对象
lock=threading.Lock()
锁定资源
lock.acquire([blocking])
释放资源
lock.release()
通信有哪些协议?
传输层:TCP 和 UDP
应用层:
基于Web的HTTP、HTTPS
用于文件传输的FTP
基于email的IMAP
网络协议Telnet、SNMP
熟悉docker吗?
一个成熟的python项目可能会依赖很多特定的环境,然而项目运行的结果不仅取决于代码,和运行代码的环境也息息相关。这很有可能会造成,开发环境上的运行结果和测试环境、线上环境上的结果都不一致的现象。
为了解决这个问题,我们可以将python项目打包成docker镜像,这样即使在不同的机器上运行打包后的项目,我们也能够得到一致的运行结果。因为docker打包是会将项目的代码和环境一起打包。
打包python项目文件和目录介绍:
docker_demo :项目顶级目录。
Dockerfile :后面根据Dockerfile创建docker镜像。
logs :日志目录,主要用来演示如何将容器中的数据同步到宿主机中去
README :介绍整个项目的背景和使用方法。
requirements.txt :该文件描述了python项目的依赖环境.
src: 该目录下放置函数入口文件。
main.py :该文件简单地验证docker是否成功安装好环境依赖、容器是否能和宿主机进行数据同步。
参考链接:
https://zhuanlan.zhihu.com/p/430989391
python中的is和==有什么区别?
is是判断地址是否相同,==是判断值是否相等。
MySQL
左连接和右链接有什么区别?
1、意思不一样
左连接:只要左边表中有记录,数据就能检索出来,而右边有的记录必要在左边表中有的记录才能被检索出来。
右连接:右连接是只要右边表中有记录,数据就能检索出来。
2、用法不一样
右连接与左连接相反,左连接A LEFT JOIN B,连接查询的数据,在A中必须有,在B中可以有可以没有。内连接A INNER JOIN B ,在A中也有,在B中也有的数据才能查询出来。
3、空值不一样
左连接是已左边表中的数据为基准,若左表有数据右表没有数据,则显示左表中的数据右表中的数据显示为空。
右联接是左向外联接的反向联接。将返回右表的所有行。如果右表的某行在左表中没有匹配行,则将为左表返回空值。
varchar和char有什么区别?
1、最大长度:
char最大长度是255字符,varchar最大长度是65535个字节。
2、定长:
char是定长的,不足的部分用隐藏空格填充,varchar是不定长的。
3、空间使用:
char会浪费空间,varchar会更加节省空间。
4、查找效率:
char查找效率会很高,varchar查找效率会更低。
5、尾部空格:
char插入时可省略,vaechar插入时不会省略,查找时省略。
union与union all的区别?
一、区别1:取结果的交集
1、union: 对两个结果集进行并集操作, 不包括重复行,相当于distinct, 同时进行默认规则的排序。
2、union all: 对两个结果集进行并集操作, 包括重复行, 即所有的结果全部显示, 不管是不是重复。
二、区别2:获取结果后的操作
1、union: 会对获取的结果进行排序操作。
2、union all: 不会对获取的结果进行排序操作。
三、总结
union all只是合并查询结果,并不会进行去重和排序操作,在没有去重的前提下,使用union all的执行效率要比union高。
事务的四大特性?
原子性: 事务中所有操作是不可再分割的原子单位。
一致性: 事务执行后,数据库状态与其它业务规则保持一致。
隔离性: 事务和事务之间是隔离开的.。
持久性: 一旦事务提交成功,事务中所有的数据操作都必须被持久化到数据库中,即使提交事务后,数据库马上崩溃,在数据库重启时,也必须能保证通过某种机制将数据恢复到提交后的状态。
怎么保证数据库主备一致性?
强行走主库方案
对于必须要拿到新结果的数据强行发到主库上,对于可以容忍短暂延迟的数据发到从库上执行。
sleep方案
以卖家发布商品为例,商品发布后,用 Ajax(Asynchronous JavaScript + XML,异步 JavaScript 和 XML)直接把客户端输入的内容作为“新的商品”显示在页面上,而不是真正地去数据库做查询。这样,卖家就可以通过这确认是否已经发布成功。等下一次刷新页面时再查数据库。
判断主备无延迟方案,判断主库位点方案,等GTID方案
配合semi-sync方案
https://blog.csdn.net/dajunstan/article/details/107331889?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-107331889-blog-128039578.pc_relevant_default&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-107331889-blog-128039578.pc_relevant_default&utm_relevant_index=1
mysql的索引结构是基于什么数据结构?
基于B+树。
mysql的视图有什么作用?
视图相当于一个虚拟表,最主要的作用通过筛选提高数据处理的效率。
其主要用途如下:
提高重用性,减少复杂sql语句的使用频次。
重构数据库,可以对不同的数据表进行关联。
提高安全性,有选择的对数据进行查询处理。
查询每个人最近一次登录距离第一次登录的天数?
思路:按id分组,最近一次登录是max(), 第一次登录是min(),使用datediff()函数计算差值。
select user_id, datediff(max(date), min(date)) from login group by user_id查询每个人连续登录的最大天数?
思路:连续登陆天数最多的人,一个是连续,一个是最多的人,也就是时间特征是连续的,并且要对不同的人统计其连续登陆的天数后再比较。
可以使用开窗函数中的 row_number(),对连续的时间进行升序排序。只要登陆时间是连续的,同一个人下不同的登陆时间减对应的排序序号,出来的值都会是一样的。
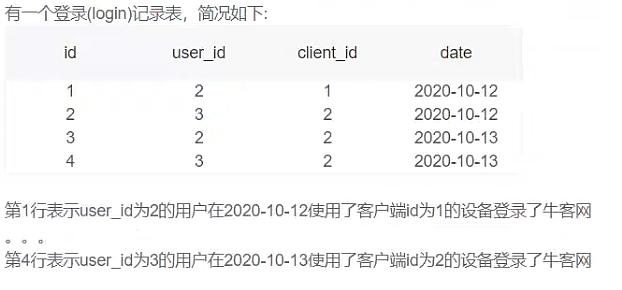
select t1.user_id, t1.day
from(select a.user_id, count(*) day, dense_rank() over(partition by a.user_id order by count(*) desc) num_rfrom(select t.user_id, t.date, date_sub(t.date, INTERVAl t.num DAY) date_resultfrom(select user_id, date,row_number() over(partition by user_id order by date ) numfrom login) t) agroup by a.user_id, a.date_result) t1
where t1.num_r = 1参考来源:
https://blog.csdn.net/weixin_43596734/article/details/128192959
https://www.zhihu.com/question/64427326/answer/2789458792?utm_id=0
Linux
查看内存的命令?
利用 'top -i' 检查有多少进程为 Running 状态,可能系统存在内存或 I/O 瓶颈,再用 free 检查系统内存使用情况,swap 有没有被占用太多,之后用 iostat 检查I/O 负载情况。也可以用ps -ef | sort -k7 ,把进程按运行时间排序,查看哪个进程消耗的cpu时间最多。
查看文件行数的命令?
wc -l filename 就是查看文件里有多少行。
wc -w filename 看文件里有多少个word。
wc -L filename 文件里最长的那一行是多少个字。
wc - c filename 统计字节数。
删除文件命令?
删除单个文件:rm filename.后缀
删除多个文件:rm filename1.后缀 FileName2.后缀
删除具有特定文件名的文件: rm *FileName* , 删除所有包含星号之间名称的文件。
删除文件夹中的所有文件:rm -r FilesName/*