作者基于多年的大数据处理经验,当前管理着100PB+数据仓库和2000+节点的集群。持续系统化给大家分享一下关于数据仓库建设的经验总结。本系列既有数据仓库的形而上学理论体系,也有结合公司业务的实践,既有大厂如阿里巴巴,京东,头条的分享交流,也有小公司数仓迭代案例的建设分析。感兴趣的小伙伴可以私信交流。
0.数仓建模系列历史篇章回顾
1. 先见森林:数据仓库的前世今生与体系框架
2. 数仓建模本质到底是什么?为什么维度建能模脱颖而出?
1.从小公司到大公司看数仓建模发展
数仓建模到底是什么,你可能看了很多理论知识,面试也知道怎么回答,但是心中还是有很多疑惑。数仓建模/维度建模其实是一整套抽象出来的方法规范体系,发展至今内部细节及其丰富。所以要想透彻了解他,运用它,你可以通过透视他的发展之路,看它是如何抽象总结出来的。这样才能明白当企业什么场景,什么规模,才能应用什么模式,数仓建设到什么程度,而不是照搬大厂或主流的数仓建设体系。
1.1 小公司的数仓建模之路
有小伙伴说,数仓建模其实没那么复杂,在我工作中不就是通过hive/spark等工具开发一张张表吗?说直白点就是把公司各个业务系统数据通过调度系统每天定时抽过来,存储到Hive数据仓库里,然后基于这些数据,定时hive/spark等任务跑了很多业务需要的数据,比如报表,比如业务汇总统计数据。最终把这些数据推送到BI报表平台或者业务库。然后日常工作也就是接点新表到数仓,给业务开发一些新表等等这些。
数仓建模其实没什么高大上的!!!!

我相信很多中小公司的小伙伴也有这些疑惑,现实中很多大数据开发也是这样干的。觉得数仓建模被神话放大了。其实我刚工作时也有这种感觉。但是后来随着去大厂做数据开发,见识了几百PB数据规模,每天几十万个任务的数据仓库。才发现如果还按照之前那套搞法根本行不通。为啥呢?
规模大的公司,PB级别的数据规模,每天上万个任务,业务快速发展,应用场景繁杂且多变,数据时间要求严格,每天新增数据TB级别,几万张甚至几十万张表,跨部门跨子公司开发人员多,大家如何保障统计的数据一致,如何复用数据降低计算成本等等这些问题,如何解决这些问题?这时候你会发现,数据仓库不仅仅是一张张表了,而是一个有着完整体系架构和规范的系统,而是一个系统化的方法体系,一个随着业务的发展,需求增加的不断丰富完善的方法体系。
1.2 大厂的数仓建设之路
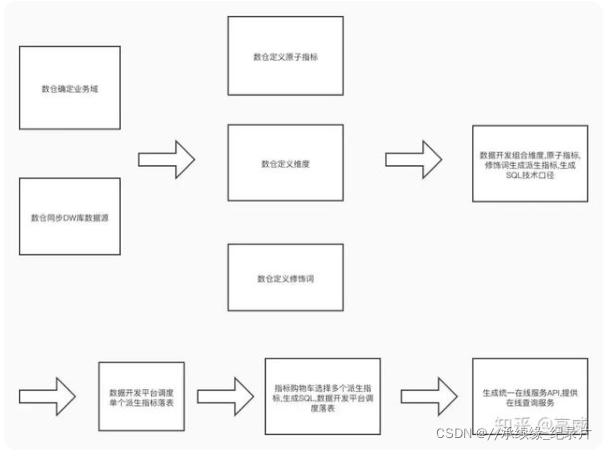
没有哪家公司上来就是王炸四带二开局的,所有公司数仓的建设也都是跟随业务的发展逐步完善的。有需求有应用场景才会有对应的解决方案,而逐步解决这些问题,解决这些需求过程中总结的成熟规范,方法,架构合起来就是一套数仓建设方案。国内如阿里巴巴就抽象出了一套自己的方法体系---OneData。当然它也是以Kimball的维度建模为核心理念基础的模型方法论,同时对其进行了一定的升级和扩展,才构建了阿里集团的数据架构体系——OneData。
因为大厂的头部效应,像阿里巴巴的onedata体系就是国内很多公司数据仓库建设的的参考标杆。如下阿里巴巴OneData体系以及建模过程:


尖叫提示:
如上OneData体系以及数仓建模过程,可谓及其完善但实施起来也很繁琐。对于Alibaba这样海量数据规模,复杂业务场景,庞大开发人员的企业来说,通过这些约束规范的流程,“浪费”人力成本来保障数据质量,最终数学期望值最高。
但是所以对于很多小伙伴来说,没有经历过大厂的开发,去学习大厂完善的数仓建设体系会有所有种“脱离实际的感觉”,有形而上学的嫌疑。毕竟国内95%以上的公司也达不到阿里巴巴这样的数据规模和要求,当然也完全没必要搞这套,不划算。
所以我后面讲数仓建设,维度建模都是抓住本质核心去讲,更多细节没法办法一一展开,因为对于很多公司没用应用场景。所以大家学数仓建设,维度建模只需要抓住Killball大神的核心理念基础即可,其他的旁枝末节知道即可。
2.维度建模核心剖析与实践
2.1.维度模式设计主要四个步骤
- 选择业务过程
- 声明粒度
- 确认维度(也有叫标识维度)
- 确认事实(也有叫标识事实)
前面说到数仓建模的本质,以及维度建模的四个步骤,对于维度建模来说其他所有的细节都是围绕这四个过程展开的。看上去这四个过程很抽象,其实几乎每个大数据开发小伙伴都经历过,只是大家不识庐山真面目,只缘生在此山中。
其实几乎每个大数据开发都搞过数仓建模,维度建模!
举个例子,即使你在一家小公司里,每天的工作就是用hive/spark开发一张张表,业务方需要啥数据给他计算啥数据。但其实数仓建模就藏在你开发的过程中,比如业务让你给他统计个数据,建个报表。下面我们来还原一下你建表开发前做了哪些事。
- 第一步:业务得告诉你开发口径吧,选择统计你们公司的什么数据?哪个业务的数据?甚至精确到哪个业务哪个过程的数据?是公司某个商品的每天交易数据?还是新增会员的信息?统计什么?好吧,我们假设业务最终告诉你统计公司A产品某个过程的浏览人数 。这其实就是维度建模的选择业务过程。
- 第二步:前面业务告诉你统计什么业务数据。那么你还得知道他要统计的数据是按天统计明细,还是按周统计汇总,这样你建表时表里一行存放什么数据,加工什么粒度的数据得知道哇,比如业务要的是每天的交易明细,那你表里存放的数据每行粒度就是天。这个确认数据粒度的过程其实就是声明粒度。
- 第三步:前面业务告诉你统计公司哪个业务线哪个业务过程的数据。也告诉你是按天统计数据,每天给他出数据。但你还得知道按什么维度统计,浏览人数是PV分析,还是按UV分析,还是业务既要UV,也要PV,也要按手机号统计浏览人数。这个其实就是你最终数据的分析维度,从哪些角度分析,是从一个维度分析还是同时多个维度一起分析。这个就是数仓建模的确认维度。
- 第四步:上面这些都确认清楚了,分析哪个业务/过程的数据,分析的粒度是按天还是周,分析的维度有哪些。那么最后你就要考虑的是如何建表了,也就是事实表的建设。根据前面三个要求建设对应的表,通过hive/spark等生产对应的数据到表里。最后业务就可以通过使用你提供的事实表和维表进行关联,查看数据了。(当然也有很多人直接将维度退化到事实表中,省去了关联维表的机会。这个后面在说)。这个过程其实就是数仓建模的确认事实。
尖叫总结:看,是不是我们在无形中完成了数仓粗放型的维度建模,只是大家没有察觉而已。这里我们简单地跟大家介绍了维度建模demo版,其实也是维度建模的核心基础了。
3.维度建模:过程拆解与案例演示
假设我们有一个电信数据源,获取的是手机连接基站等信息的数据,数据是每隔1小时上传一次。现在业务方需要通过手机连接基站的信息情况,分析一下用户手机类型,用户主要分布在哪个城市,用户运营商分类情况,挖掘一下用户工作地,居住地等情况,甚至用户性别等信息做用户画像。
TABLE `base_station_info`(`serdatetime` string COMMENT '服务器时间标准时间戳(13位数字)', `ipaddr` string COMMENT '客户端源IP', `type` string COMMENT '数据类型', `plat` string COMMENT '系统平台', `device` string COMMENT '设备标示', `carrier` string COMMENT '运营商编码', `simopname` string COMMENT '运营商名字:联通,电信,移动,铁通,..', `lac` string COMMENT '基站lac', `datetime` string COMMENT '客户端时间(经过服务端时间矫正标准时间戳(13位数字', `mac` string COMMENT '设备Mac地址', `model` string COMMENT '设备型号', `duid` string COMMENT 'DUID(新版设备标示)', `imei` string COMMENT '设备IMEI手机串号', `serialno` string COMMENT '手机序列号', `networktype` string COMMENT '网络类型', `processtime` string COMMENT '服务器时间', `product` string COMMENT '产品线', `psc` int COMMENT 'UMTS的主要扰码', `lat` int COMMENT '基站纬度', `lon` int COMMENT '基站经度', `nearby` array<map<string,int>> COMMENT '邻区基站信息列表', `language` string COMMENT '手机语言', `cl` map<string,string> COMMENT '安卓缓存的GPS信息,安卓获取缓存经纬度', `strategy_id` string COMMENT '定向调频的策略Id', `moid` string COMMENT '匿名设备标识符,取值deviceinfo表oaid字段的值', `appkey` string COMMENT '应用的key', `apppkg` string COMMENT '应用的包名', `appver` string COMMENT '应用的版本号', `sysver` string COMMENT '系统版本号', `factory` string COMMENT '设备的厂商', `commonsdkver` string COMMENT '公共库的版本号', `token` string COMMENT '唯一ID', `data_network_type` string COMMENT '蜂窝网络类型', `dc` int COMMENT '1为离线包,2为Maven线上包,3为定制包,4为MDC版本,6为GP版本', `useridentity` string COMMENT '请求头')
3.1.选择业务过程
如上,开始建模前我们需要考虑自己有哪些数据源,数据的情况,以及业务方的需求,然后决定对哪种业务过程开展数据建模。这里业务方想通过手机基站连接信息分析用户情况,做用户画像。因此这里我们建模的业务过程是手机基站连接信息。
3.2声明粒度
上面我们知道我们的数据源的粒度是小时级别,数据是每小时更新上传一次。基本数据越详细,粒度越小获取的事实就越多,可以分析的东西也就越多。原子粒度的数据具有更强大的多维性。比如按小时粒度的数据我就可以按小时,天,周,月汇总统计。但是按天的粒度的数据,可以上卷按天,周月统计,但是没法下钻按小时类别聚合了,所以一般为了防止业务变更需求,尽可能的话可以选择原子粒度的数据。这里我们就选择原子粒度的数据。
3.3确认维度
数据粒度选择完以后,维度可以的选择空间也就固定了下来,维度的选择就很简单了。为什么呢?因为数据的详细粒度确认了事实表可以分析的主要维度。比如上面我们确认数据粒度以后,可以分析的维度也就是表里字段的度量值。比如运营商分类,手机类型分类,网络类型,当然具体看业务需要哪些分析维度,因为不需要分析的维度我们完全不用存放这些数据,浪费计算和存储空间等等。
3.4 确认事实
所谓的确认事实,其实就是我们根据业务分析的需求,分析的数据粒度,数据分析的维度决定了最终我们要把哪些数据放到事实表,也就是我们模型(建表)里存放哪些了事实(字段)要确认好,因为你不可能所有字段都保留着,浪费资源。然后基于事实表模型进行建设开发。
基于前面3个过程和业务确认后 ,最终我们事实表存储的字段如下,然后我们开始开发事实表中的数据。注意如下,要求我们的事实表中的数据都可以按照如下6大维度进行汇总统计(可加事实),否则事实表设计的就有问题,后续详细展开。

总结一下,所谓确认事实,首先确认需要将哪些事实放到事实表中。其次就是确认最终数据模型。注意,我这里为了简单举例,事实表的字段没有进行过复杂加工,只是做了一些简单的数据清洗,比如数据格式的清洗,数据的归类转换,时间格式的统一等等。后面在介绍挖掘聚合类数据建模。
尖叫总结:
维度建模4个步骤,简单演示了一下。重点是让大家体会维度建模是如何抽象出来的,以及四个步骤为啥是环环相扣,递进式的关系。后面我们继续展开维度建模。