维度建模
维度模型简介
维度建模被广泛接受为数据分析的首选技术,因为它同时满足了两个需求:
1.向用户交付可以理解的数据
2.提供快速查询的性能
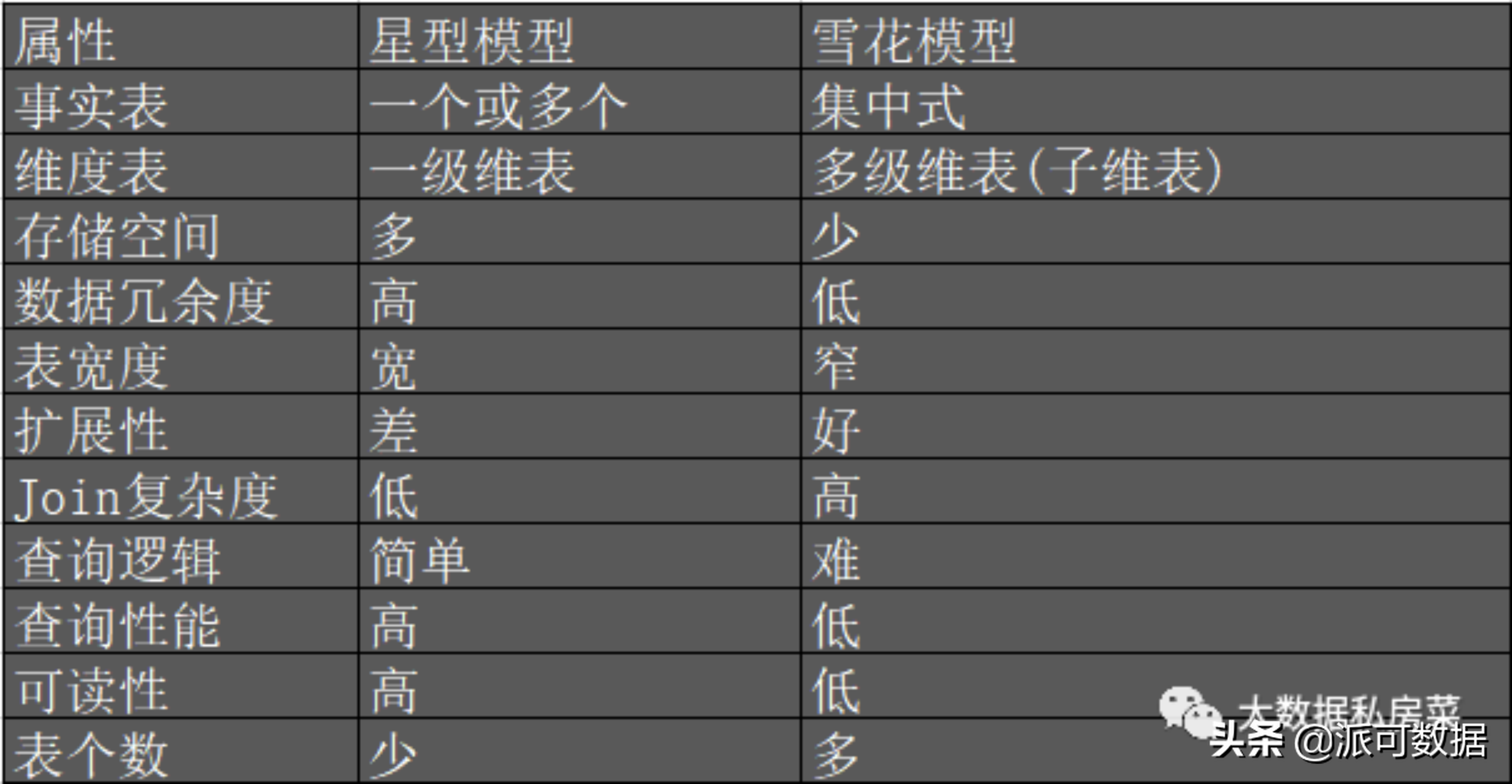
| 维度建模 | 实体建模 | 第三范式(3NF)建模 |
|---|---|---|
| 适合表连接以及聚合计算的查询请求;易用,易理解,查询效率高,更适合作为分析性应用(OLAP、BI)的基础 | 抽象客观世界的方法,局限于业务建模和领域概念建模 | 适用于频繁的update、insert这种(事务型应用);规范化模型过于复杂,无法得到直观的、高性能的数据检索 |
维度建模的两种模型:
- 星型模型
维度建模是数据仓库建设中的一种数据建模方法。Kimball最先提出这一概念。其最简单的描述就是,按照事实表,维度表来构建数据仓库,数据集市。这种方法被人广泛知晓的名字就是星型模型(Star-schema)。

- 雪花模型
当星型模型的维度表进一步层次化,就形成了雪花模型。

维度建模的优点
- 直观
- 围绕业务模型
- 反应业务问题
- 不需要抽象处理
维度建模的缺点
- 由于在构建星型模式之前需要进行大量的数据预处理,因此会导致大量的数据预处理工作。
- 当业务发生变化,需要重新进行维度的定义时,往往需要重新进行维度数据的预处理。而在这些预处理过程中,会导致大量的数据冗余。
- 如果只是依靠单纯的维度建模,不能保证数据来源的一致性和准确性。
- 在数据仓库的底层,不是特别适用于维度建模的方法。
维度建模的基本原则
- 将详细的原子数据载入到维度结构中
- 围绕业务流程构建维度模型
- 确保每个事实表都有一个与之关联的日期维度表
- 确保每个事实表中的事实具有相同的粒度或同级的详细程度
- 避免事实表中出现多对多的关系
- 避免维度表中出现多对一的关系
- 避免在事实表中存储神秘的编码字段或庞大的描述符字段
- 确保维度表使用了代理键(无业务意义的主键)
- 创建一致的维度集成整个企业的数据
- 不断平衡需求和现实,提供DW/BI解决方案
维度表技术基础
维度表结构
维度表是在事实各维度上所建立的表。维度表可以看做是用户来分析数据的窗口。

维度表示例

键属性
维度表包含了维度的每个成员的特定名称。维度成员的名称称为“属性”(Attribute)。拿产品维度表作为示例。
在数据仓库中,维度表中的键属性必须为维度的每个成员包含一个对应的唯一值。用关系型数据库术语描述就是,键属性称为主键列。

原则1+原则2
把维度信息移动到一个单独的表中,除了使得事实表更小外,还有额外的优点,就是可以为每个维度成员添加额外的信息

维度表特点
- 表形状 宽的、扁平的
- 表性质 非规范化的表,具有许多低粒度的文本属性
- 表特点 维度表属性
维度键代理
- 自然键==>自然键是现实世界中已经存在的一个或多个属性,它在业务概念中唯一。
- 代理键==>而代理键通常是数据库系统赋予的一个数值,是自增型的,按顺序分配,没有内置含义但也可以唯一地标识一条维度信息。
代理键实现方法
- 使用数据库赋值—— 大多是主要的数据库供应商实现了被称为递增键的代理键策略。即,数据库中的表主键设为自增键。
- MAX()+1—— 一个常用的策略是使用整数列,第一条记录从1开始,然后新行的值设置为该列的最大值加1,最大值用SQL函数MAX获得。
- 全局唯一标识符(UUIDs)—— UUIDs是128位值,来自以太网卡ID或等价的软件表示以及系统当前时间的哈希值。该算法是由开放软件基金会定义的。
- 全球唯一标识(GUIDs)—— GUIDs是微软扩展UUIDs后的标准,遵从相同的策略,如果存在以太网卡使用网卡ID,如果不存在,使用软件ID与当前时间计算一个哈希值,确保在机器内部唯一。
- 高低位策略—— HIGH-LOW发生器,分为两个逻辑部分:从指定来源获取的唯一HIGH值和应用自身分配的N为LOW值。如:应用请求一个HIGH值并被赋予1701。假设LOW值的位数N为4,那么赋予对象的POID将会由17010000、17010001、17010002等等直到17019999组成。只要HIGH值唯一,所有的POID值将会唯一。
多维体系结构
维度建模的数据仓库中,Kimball的多维体系结构(MD)包含三个关键性概念:
- 总线架构(Bus Architecture)
- 一致性维度(Conformed Dimension)
- 一致性事实(Conformed Fact)

总线结构

很明显,要将图3-1中的业务价值链组合成数据仓库,就不能对各业务处理分别进行维度建模、建数据集市,因为如果那样的话,数据集市之间没有共享的公共维度,数据集市就会变成独立的集市,会出现问题,不能组合成数据仓库。要成功建立数据仓库,并使得数据仓库能够长期地正常运转,就需要有一种方法,可以在体系结构上按增量方式建造企业数据仓库。这里提倡使用的一种方法就是数据仓库总线结构。
如果为数据仓库环境定义标准的总线接口,那么不同的小组在不同的时间可以实现独立的数据集市。只要遵循这个标准,独立的数据集市就可以集成到一起并有效地共存。所有业务处理将创建一个维度模型系列,这些模型共享一组维度,这组公用维度具有一致性,如图3-2所示。

简单来说,总线结构提供分解企业数据仓库规划任务的方法:
- 首先,设计出一整套具有统一解释的标准化维度与事实。
- 然后,迭代开发数据集市
总线结构使数据仓库管理人员获取两个方面的优势:
- 他们有了指导总体设计的体系框架,将问题分成了数据集市块。
- 各数据集市开发团队可以相对独立地异步地开展工作。
一致性维度
当不同的维度表属性具有相同的列名和领域内容时,称维度表具有一致性。下图给出了这种维度共享情形的逻辑表示形式。
- 一致性维度分为两种:一种是在不同数据集市维度保持一致;还有就是在同一个集市内维度一致。
- 在后台建立好的维度同步复制到各个数据集市。
- 在同一个集市内,一致性维度的意思是两个维度如果有关系,那么就是完全一样的,要么就是一个维度在数学意义上是另一个维度的子集。

数据整合的关键就是生成一致性维度,再通过一致性维度将来自不同数据源的事实数据合并到一起,供分析使用。通常来说,生成一致性维度有如下三个步骤:
- 标准化==>匹配==>筛选
一致性事实
定义:当不同的事实表具有相同的事实,且这些事实具有相同的定义域方程(公式)时,称事实表具有一致性。
描述:一般来说,事实表数据并不在各个数据集市之间明确地进行复制。不过,如果事实确实存在于多个位置,那么支撑这些事实的定义与方程(公式)都必须是相同的。
缓慢维度变化
缓慢维度变化(Slow Changing Dimensions)(SCD)指随着时间缓慢变化的维度。如产品类别维度,地区维度等。在相同的维度表中,使用不同的更改跟踪技术处理属性是非常常见的。SCD可根据是否/如何保留维度的变化历史,分为不同类别。

- 类型0:保留原来的
对于类型0,维度属性永远不会改变,所以事实总是按照这个原始值分组。
- 类型1:覆盖
对于类型1,维度行中的旧属性值被新值覆盖。

- 类型2:添加新行
类型2在维度中新增一行数据,此数据具有更新的属性值,并将旧数据行标记为“过期”。

- 类型3:添加新属性
类型3在维度中添加一个新属性以保存旧属性值;新值覆盖了主属性。

- 类型4:添加微信维度
当维度中的一组属性快速变化并被分割为一个小维度时,使用类型4技术。

- 类型5:添加微型维度和类型1支架
类型5技术用于精确地保存历史属性值,并根据当前属性值报告历史事实。

- 类型6:向类型2维度中添加类型1属性
类型6也提供历史和当前维度属性值,它相当于类型2和类型1的结合。

- 类型7:双类型1和类型2型的维度
类型7是最后一种混合技术,用于支持原有和现有的报表。

事实表技术基础
事实表结构
在多维数据仓库中,保存度量值的详细值或事实的表称为“事实表”。
实时数据表的主要特点:
- 通常包含大量的行;
- 包含数字数据(事实);
- 数字信息可以汇总;
- 每个事实数据表包含一个由多个部分组成的索引;
- 索引包含作为外键的相关性维度表的主键。
“事实”这一术语表示某个业务度量,而事实表则是由“事实”转化而来。

从另一个角度来看销售事实表的一个实例。

事实表几乎总会使用一个整数值来表示(维度)成员,而不是用描述性的名称。

事实表的三类事实
将事实相加以获得对单个事实汇总的能力被称为可加性。
根据可加性可以将事实表中的数字度量分为三类:可加、半可加、不可加。
完全可加事实
- 完全可加度量是最灵活、最有用的事实,它可以按照与事实表关联的任意维度汇总。









![[OpenCV实战]52 在OpenCV中使用颜色直方图](https://img-blog.csdnimg.cn/img_convert/925e455f72c7db6bc7dcab40a7b88cd3.jpeg)