(附:由于篇幅原因,这里就不在展示代码了,直接告诉大家思路)
目录
五:交易域订单预处理表
5.1 主要任务
5.2 思路分析
5.3 图解
六:交易域下单事务事实表
6.1 主要任务:
6.2 思路分析:
6.3 图解:
七:交易域取消订单事务事实表
7.1 主要任务:
7.2 思路分析:
7.3 图解:
八:交易域支付成功事务事实表
8.1 主要任务:
8.2 思路分析:
8.3 图解:
九:交易域退单事务事实表
9.1主要任务:
9.2思路分析:
9.3 图解:
十:交易域退款成功事务事实表
10.1 主要任务:
10.2 思路分析:
10.3 图解:
五:交易域订单预处理表
5.1 主要任务
经过分析,订单明细表和取消订单明细表的数据来源、表结构都相同,差别只在业务过程和过滤条件,为了减少重复计算,将两张表公共的关联过程提取出来,形成订单预处理表。
关联订单明细表、订单表、订单明细活动关联表、订单明细优惠券关联表四张事实业务表和字典表(维度业务表)形成订单预处理表,写入 Kafka 对应主题。
本节形成的预处理表中要保留订单表的 type 和 old 字段,用于过滤订单明细数据和取消订单明细数据。
5.2 思路分析
1)知识储备
(1)left join 实现过程
假设 A 表作为主表与 B 表做等值左外联。当 A 表数据进入算子,而 B 表数据未至时会先生成一条 B 表字段均为 null 的关联数据ab1,其标记为 +I。其后,B 表数据到来,会先将之前的数据撤回,即生成一条与 ab1 内容相同,但标记为 -D 的数据,再生成一条关联后的数据,标记为 +I。这样生成的动态表对应的流称之为回撤流。
(2)Kafka SQL Connector
Kafka SQL Connector 分为 Kafka SQL Connector 和 Upsert Kafka SQL Connector
① 功能
Upsert Kafka Connector支持以 upsert 方式从 Kafka topic 中读写数据
Kafka Connector支持从 Kafka topic 中读写数据
② 区别
a)建表语句的主键
i)Kafka Connector 要求表不能有主键,如果设置了主键,报错信息如下
Caused by: org.apache.flink.table.api.ValidationException: The Kafka table
'default_catalog.default_database.normal_sink_topic' with 'json' format doesn't support
defining PRIMARY KEY constraint on the table, because it can't guarantee the semantic of
primary key.ii)而 Upsert Kafka Connector 要求表必须有主键,如果没有设置主键,报错信息如下
Caused by: org.apache.flink.table.api.ValidationException: 'upsert-kafka' tables require to
define a PRIMARY KEY constraint. The PRIMARY KEY specifies which columns should be read
from or write to the Kafka message key. The PRIMARY KEY also defines records in the
'upsert-kafka' table should update or delete on which keys.iii)语法: primary key(id) not enforced
注意:not enforced 表示不对来往数据做约束校验,Flink 并不是数据的主人,因此只支持 not enforced 模式
如果没有 not enforced,报错信息如下
Exception in thread "main" org.apache.flink.table.api.ValidationException: Flink doesn't
support ENFORCED mode for PRIMARY KEY constaint. ENFORCED/NOT ENFORCED controls if the
constraint checks are performed on the incoming/outgoing data. Flink does not own the data
therefore the only supported mode is the NOT ENFORCED modeb)对表中数据操作类型的要求
i)Kafka Connector 不能消费带有 Upsert/Delete 操作类型数据的表,如 left join 生成的动态表。如果对这类表进行消费,报错信息如下
Exception in thread "main" org.apache.flink.table.api.TableException: Table sink
'default_catalog.default_database.normal_sink_topic' doesn't support consuming update and
delete changes which is produced by node TableSourceScan(table=[[default_catalog,
default_database, Unregistered_DataStream_Source_9]], fields=[l_id, tag_left, tag_right])ii)Upsert Kafka Connector 将 INSERT/UPDATE_AFTER 数据作为正常的 Kafka 消息写入,并将 DELETE 数据以 value 为空的 Kafka 消息写入(表示对应 key 的消息被删除)。Flink 将根据主键列的值对数据进行分区,因此同一主键的更新/删除消息将落在同一分区,从而保证同一主键的消息有序。
③ left join 结合 Upsert Kafka Connector 使用范例
说明:Kafka 并行度为 4
a)表结构
left表
id tag
A left
B left
C left right 表
id tag
A right
B right
C rightb)查询语句
select
l.id l_id,
l.tag l_tag,
r.tag r_tag
from left l
left join
right r
on l.id = r.idc)关联结果写入到 Upsert Kafka 表,消费 Kafka 对应主题数据结果展示
{"l_id":"A","tag_left":"left","tag_right":null}
null
{"l_id":"A","tag_left":"left","tag_right":"right"}
{"l_id":"C","tag_left":"left","tag_right":null}
null
{"l_id":"C","tag_left":"left","tag_right":"right"}
{"l_id":"B","tag_left":"left","tag_right":null}
null
{"l_id":"B","tag_left":"left","tag_right":"right"}④ 参数解读
本节需要用到 Kafka 连接器的明细表数据来源于 topic_db 主题,于 Kafka 而言,该主题的数据的操作类型均为 INSERT,所以读取数据使用 Kafka Connector 即可。而由于 left join 的存在,流中存在修改数据,所以写出数据使用 Upsert Kafka Connector。
Upsert Kafka Connector 参数
- connector:指定使用的连接器,对于 Upsert Kafka,使用 'upsert-kafka'
- topic:主题
- properties.bootstrap.servers:以逗号分隔的 Kafka broker 列表
- key.format:key 的序列化和反序列化格式
- value.format:value 的序列化和反序列化格式
2)执行步骤
预处理表与订单明细事务事实表的区别只在于前者不会对订单数据进行筛选,且在表中增加了 type 和 old 字段。二者的粒度、聚合逻辑都相同,因此按照订单明细表的思路对预处理表进行分析即可。
(1)设置 ttl;
订单明细表、订单表、订单明细优惠券管理表和订单明细活动关联表不存在业务上的滞后问题,只考虑可能的数据乱序即可,此处将 ttl 设置为 5s。
要注意:前文提到,本项目保证了同一分区、同一并行度的数据有序。此处的乱序与之并不冲突,以下单业务过程为例,用户完成下单操作时,订单表中会插入一条数据,订单明细表中会插入与之对应的多条数据,本项目业务数据是按照主键分区进入 Kafka 的,虽然同分区数据有序,但是同一张业务表的数据可能进入多个分区,会乱序。这样一来,订单表数据与对应的订单明细数据可能被属于其它订单的数据“插队”,因而导致主表或从表数据迟到,可能 join 不上,为了应对这种情况,设置乱序程度,让状态中的数据等待一段时间。
(2)从 Kafka topic_db 主题读取业务数据;
这一步要调用 PROCTIME() 函数获取系统时间作为与字典表做 Lookup Join 的处理时间字段。
(3)筛选订单明细表数据;
应尽可能保证事实表的粒度为最细粒度,在下单业务过程中,最细粒度的事件为一个订单的一个 SKU 的下单操作,订单明细表的粒度与最细粒度相同,将其作为主表。
(4)筛选订单表数据;
通过该表获取 user_id 和 province_id。保留 type 字段和 old 字段用于筛选订单明细数据和取消订单明细数据。
(5)筛选订单明细活动关联表数据;
通过该表获取活动 id 和活动规则 id。
(6)筛选订单明细优惠券关联表数据;
通过该表获取优惠券 id。
(7)建立 MySQL-Lookup 字典表;
通过字典表获取订单来源类型名称。
(8)关联上述五张表获得订单宽表,写入 Kafka 主题
事实表的粒度应为最细粒度,在下单和取消订单业务过程中,最细粒度为一个 sku 的下单或取消订单操作,与订单明细表粒度相同,将其作为主表。
① 订单明细表和订单表的所有记录在另一张表中都有对应数据,内连接即可。
② 订单明细数据未必参加了活动也未必使用了优惠券,因此要保留订单明细独有数据,所以与订单明细活动关联表和订单明细优惠券关联表的关联使用 left join。
③ 与字典表的关联是为了获取 source_type 对应的 source_type_name,订单明细数据在字典表中一定有对应,内连接即可。
5.3 图解

六:交易域下单事务事实表
6.1 主要任务:
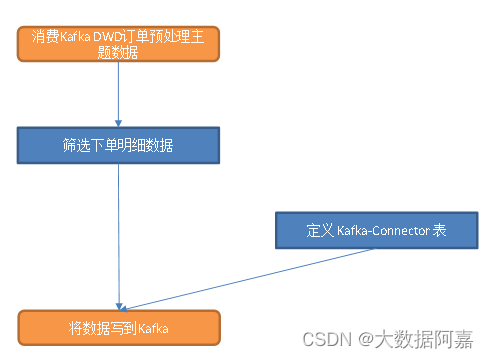
从 Kafka 读取订单预处理表数据,筛选下单明细数据,写入 Kafka 对应主题。
6.2 思路分析:
实现步骤
(1)从 Kafka dwd_trade_order_pre_process 主题读取订单预处理数据;
(2)筛选下单明细数据:新增数据,即订单表操作类型为 insert 的数据即为订单明细数据;
(3)写入 Kafka 下单明细主题。
6.3 图解:
七:交易域取消订单事务事实表
7.1 主要任务:
从 Kafka 读取订单预处理表数据,筛选取消订单明细数据,写入 Kafka 对应主题。
7.2 思路分析:
实现步骤
(1)从 Kafka dwd_trade_order_pre_process 主题读取订单预处理数据;
(2)筛选取消订单明细数据:保留修改了 order_status 字段且修改后该字段值为 "1003" 的数据;
(3)写入 Kafka 取消订单主题。
7.3 图解:

八:交易域支付成功事务事实表
8.1 主要任务:
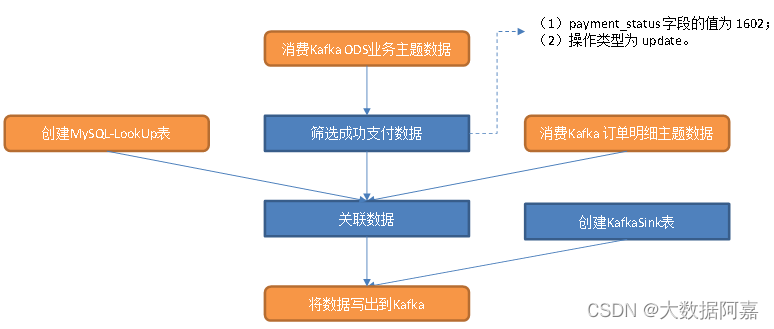
从 Kafka topic_db主题筛选支付成功数据、从dwd_trade_order_detail主题中读取订单事实数据、MySQL-LookUp字典表,关联三张表形成支付成功宽表,写入 Kafka 支付成功主题。
8.2 思路分析:
1)设置 ttl
支付成功事务事实表需要将业务数据库中的支付信息表 payment_info 数据与订单明细表关联。订单明细数据是在下单时生成的,经过一系列的处理进入订单明细主题,通常支付操作在下单后 15min 内完成即可,因此,支付明细数据可能比订单明细数据滞后 15min。考虑到可能的乱序问题,ttl 设置为 15min + 5s。
2)获取订单明细数据
用户必然要先下单才有可能支付成功,因此支付成功明细数据集必然是订单明细数据集的子集。
3)筛选支付表数据
获取支付类型、回调时间(支付成功时间)、支付成功时间戳。
生产环境下,用户支付后,业务数据库的支付表会插入一条数据,此时的回调时间和回调内容为空。通常底层会调用第三方支付接口,接口会返回回调信息,如果支付成功则回调信息不为空,此时会更新支付表,补全回调时间和回调内容字段的值,并将 payment_status 字段的值修改为支付成功对应的状态码(本项目为 1602)。支付成功之后,支付表数据不会发生变化。因此,只要操作类型为 update 且状态码为 1602 即为支付成功数据。
由上述分析可知,支付成功对应的业务数据库变化日志应满足两个条件:
(1)payment_status 字段的值为 1602;
(2)操作类型为 update。
本程序为了去除重复数据,在关联后的宽表中补充了处理时间字段,DWS 层将进行详细介绍。支付成功表是由支付成功数据与订单明细做内连接,而后与字典表做 LookUp Join 得来。这个过程中不会出现回撤数据,关联后表的重复数据来源于订单明细表,所以应按照订单明细表的处理时间字段去重,故支付成功明细表的 row_op_ts 取自订单明细表。
4)构建 MySQL-LookUp 字典表
5)关联上述三张表形成支付成功宽表,写入 Kafka 支付成功主题
支付成功业务过程的最细粒度为一个 sku 的支付成功记录,payment_info 表的粒度与最细粒度相同,将其作为主表。
(1) payment_info 表在订单明细表中必然存在对应数据,主表不存在独有数据,因此通过内连接与订单明细表关联;
(2) 与字典表的关联是为了获取 payment_type 对应的支付类型名称,主表不存在独有数据,通过内连接与字典表关联。下文与字典表的关联同理,不再赘述。
8.3 图解:
九:交易域退单事务事实表
9.1主要任务:
从 Kafka 读取业务数据,筛选退单表数据,筛选满足条件的订单表数据,建立 MySQL-Lookup 字典表,关联三张表获得退单明细宽表。
9.2思路分析:
1)设置 ttl
用户执行一次退单操作时,order_refund_info 会插入多条数据,同时 order_info 表的一条对应数据会发生修改,所以两张表不存在业务上的时间滞后问题,因此仅考虑可能的乱序即可,ttl 设置为 5s。
2)筛选退单表数据
退单业务过程最细粒度的操作为一个订单中一个 SKU 的退单操作,退单表粒度与最细粒度相同,将其作为主表。
3)筛选订单表数据并转化为流
获取 province_id。退单操作发生时,订单表的 order_status 字段值会由1002(已支付)更新为 1005(退款中)。订单表中的数据要满足三个条件:
(1)order_status 为 1005(退款中);
(2)操作类型为 update;
(3)更新的字段为 order_status。
该字段发生变化时,变更数据中 old 字段下 order_status 的值不为 null(为 1002)。
4)建立 MySQL-Lookup 字典表
获取退款类型名称和退款原因类型名称。
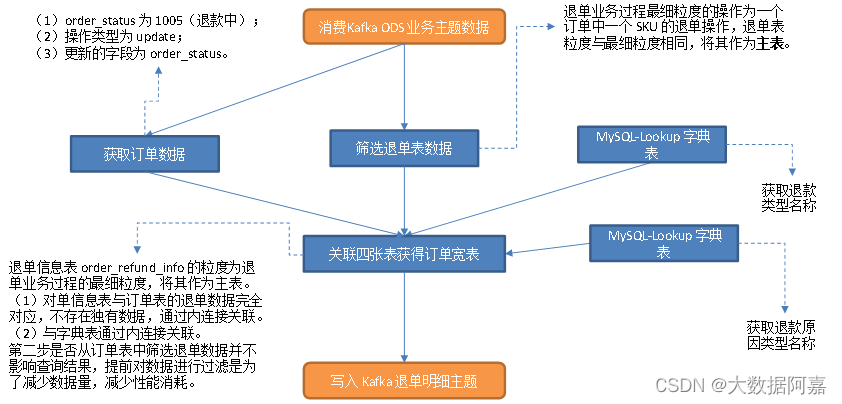
5)关联这几张表获得退单明细宽表,写入 Kafka 退单明细主题
退单信息表 order_refund_info 的粒度为退单业务过程的最细粒度,将其作为主表。
(1)对单信息表与订单表的退单数据完全对应,不存在独有数据,通过内连接关联。
(2)与字典表通过内连接关联。
第二步是否从订单表中筛选退单数据并不影响查询结果,提前对数据进行过滤是为了减少数据量,减少性能消耗。下文同理,不再赘述。
9.3 图解:
十:交易域退款成功事务事实表
10.1 主要任务:
1)从退款表中提取退款成功数据,并将字典表的 dic_name 维度退化到表中
2)从订单表中提取退款成功订单数据
3)从退单表中提取退款成功的明细数据
10.2 思路分析:
1)设置 ttl
一次退款支付操作成功时,refund_payment 表会新增记录,订单表 order_info 和退单表order_refund_info 的对应数据会发生修改,几张表之间不存在业务上的时间滞后。与字典表的关联分析同上,不再赘述。因而,仅考虑可能的数据乱序即可。将 ttl 设置为 5s。
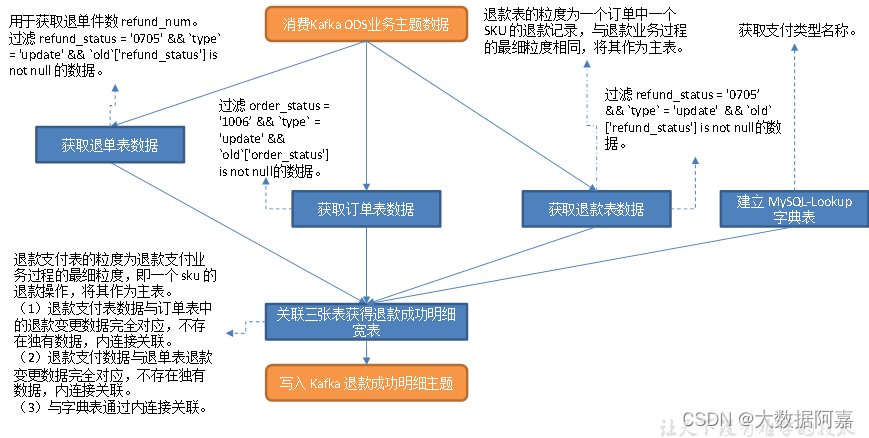
1)建立 MySQL-Lookup 字典表
获取支付类型名称。
2)读取退款表数据,筛选退款成功数据
退款表 refund_payment 的粒度为一个订单中一个 SKU 的退款记录,与退款业务过程的最细粒度相同,将其作为主表。
退款操作发生时,业务数据库的退款表会先插入一条数据,此时 refund_status 状态码应为 0701(商家审核中),callback_time 为 null,而后经历一系列业务过程:商家审核、买家发货、退单完成。退单完成时会将状态码由 0701 更新为 0705(退单完成),同时将 callback_time 更新为退款支付成功的回调时间。
由上述分析可知,退款成功记录应满足三个条件:(1)数据操作类型为 update;(2)refund_status 为 0705;(3)修改的字段包含 refund_status。
3)读取订单表数据,过滤退款成功订单数据
用于获取 user_id 和 province_id。退款操作完后时,订单表的 order_status 字段会更新为 1006(退款完成),因此退单成功对应的订单数据应满足三个条件:(1)操作类型为 update;
(2)order_status 为 1006;(3)修改了 order_status 字段。
order_status 值更改为 1006 之后对应的订单表数据就不会再发生变化,所以只要满足前两个条件,第三个条件必定满足。
4)筛选退款成功的退单明细数据
用于获取退单件数 refund_num。退单成功时 order_refund_info 表中的 refund_status 字段会修改为0705(退款成功状态码)。因此筛选条件有三:(1)操作类型为 update;(2)refund_status 为 0705;(3)修改了 refund_status 字段。筛选方式同上。
5)关联四张表并写出到 Kafka 退款成功主题
退款支付表的粒度为退款支付业务过程的最细粒度,即一个 sku 的退款操作,将其作为主表。
(1)退款支付表数据与订单表中的退款变更数据完全对应,不存在独有数据,内连接关联。
(2)退款支付数据与退单表退款变更数据完全对应,不存在独有数据,内连接关联。
(3)与字典表通过内连接关联。
10.3 图解:
![[数据仓库]分层概念,ODS,DM,DWD,DWS,DIM的概念](https://img-blog.csdnimg.cn/img_convert/523af9b199c957a94f22907cc0df07b1.png)