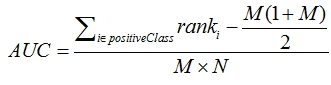| 名称 | 含义 | 公式 |
|---|---|---|
| 真阳率\召回率\查全率\TPR\Recall | 表示正确预测的正样本与全部正样本的比值 | a a + c \frac{a}{a+c} a+ca |
| 假阳性率\FPR | 表示负样本被预测为正样本与全部负样本的比值 | b b + d \frac{b}{b+d} b+db |
| 精确率\查准率\Precision\ | 表示正确预测的正样本与预测为正样本的比值 | a a + b \frac{a}{a+b} a+ba |
| 准确率\accuracy | 表示正确预测的正、负样本与全部样本的比值 | a + d a + b + c + d \frac{a+d}{a+b+c+d} a+b+c+da+d |
| F1\H-mean值 | F1对Precision和Recall都进行了加权 | \frac{}{} |
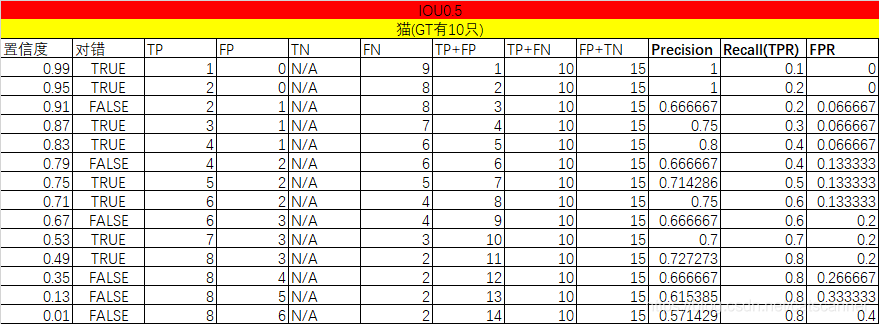
1,ROC曲线
去医院做检查化验单或报告单会出现(+)跟(-),其分别表型阳性和阴性。比如你去检查是不是得了某种病,阳性(+)就说明得了,阴性(-)就说明没事。
科研人员在设计这种检验方法的时候希望知道,如果这个人确实得了病,那么这个方法能检查出来的概率是多少呢(真阳率)?如果这个人没有得病,那么这个方法误诊其有病的概率是多少呢(假阳率)?
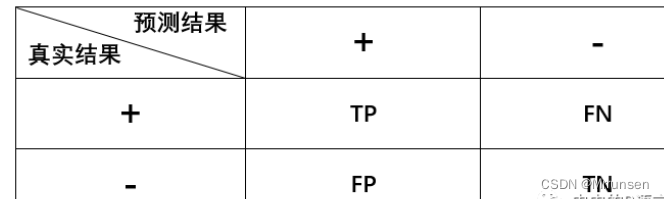
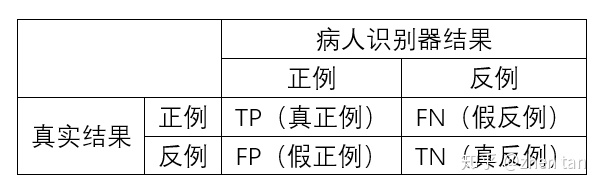
如下表1所示:
金标准就是实际中的病人阳性和阴性的情况,某筛选方法就是我们预测阳、阴性所采用的方法。
TP(True positive):正确预测为正样本
FN(False Negative):错误预测为负样本
FP(False positive):错误预测为正样本
TN(True Negative):正确预测为负样本
真阳率(True Positive Rate, TPR)或者叫召回率:表示正确预测的正样本与全部正样本的比值:
真 阳 率 = a a + c 真阳率 = \frac{a}{a+c} 真阳率=a+ca
表示在所有的阳性病人中被正确预测为阳性的概率。
假阳性率(False Positive Rate, FPR)表示负样本被预测为正样本与全部负样本的比值:
假 阳 性 = b b + d 假阳性=\frac{b}{b+d} 假阳性=b+db
表示在所有的阴性病人中被预测为阳性的概率。
ROC曲线,就是把假阳率当x轴,真阳率当y轴画一个二维平面直角坐标系。通过不断调整检测方法(或机器学习中的分类器)的阈值,即最终得分高于某个值就是阳性,反之就是阴性,得到不同的真阳率和假阳率数值,然后描点。就可以得到一条ROC曲线。
对于ROC曲线做如下说明:
(1)ROC曲线上的每一个点对应于一个threshold,大于这个值的实例划归为正类,小于这个值则划到负类中.
Threshold最大时,把每个实例都预测为负类, TPR=0,FPR=0,对应于原点;
Threshold最小时,,把每个实例都预测为正类,TPR=1,FPR=1,对应于右上角的点(1,1)
假设阈值为thred;带预测的样本x通过某种算法得到的分数为score_x;
if(score_x>thred) x为正样本;
if(score_x<=thred) x为负样本;
那么当thred非常大的时候,所有样本都被预测为负样本,即a=0,b=0 因此:真阳率和假阳性都为0.
那么当thred非常小的时候,所有样本都被预测为正样本,即c=0,d=0 因此:真阳率和假阳性都为1.
可以根据对灵敏度和特异度的特定要求,确定ROC曲线一适当的工作点,确定最好的决策阈值。
(2)理想情况下,TPR应该接近1,FPR应该接近0。
一个好的分类模型应该尽可能靠近图形的左上角,
而一个随机猜测模型应位于连接点(TPR=0,FPR=0)和(TPR=1,FPR=1)的主对角线上。
(3) ROC曲线下方的面积(AUC)提供了评价模型平均性能的另一种方法。如果模型是完美的,那么它的AUG = 1,如果模型是个简单的随机猜测模型,那么它的AUG = 0.5,如果一个模型好于另一个,则它的曲线下方面积相对较大。
ROC曲线可以全面评分类器的性能。
注意:认真的读者也许会感慨左上角的说法有些含糊,所谓“曲线左上角”至少有3种判断方式:a,曲线与斜率为1的切点;b,曲线经过(0,1)和(1,0)两点直线的交点;c,曲线上与(0,1)点绝对距离最近的点。从数学上讲,由于ROC曲线并非规则曲线,这3点未必永远合一。
AUC(Area Under Curve)顾名思义,就是这条ROC曲线下方的面积了。越接近1表示分类器越好。
所以对于多种预测方法的优劣判断可以在一个坐标下画他们的ROC曲线,然后通过计算他们的AUC来进行判断。
2,F1评分
还是依表1为依据,精确(Precision)为:
P r e = a a + b Pre=\frac{a}{a+b} Pre=a+ba
表示预测为阳性的样本中真正为阳性的概率。
而真阳率(True Positive Rate, TPR)又成为召回率(Recall):
R e c = a a + c Rec=\frac{a}{a+c} Rec=a+ca
F1是将准确率和召回率结合在一起,如下所示:
F 1 = 2 P r e ∗ R e c P r e + R e c F1=\frac {2Pre * Rec} {Pre + Rec} F1=Pre+Rec2Pre∗Rec
3,P-R曲线
对于算法的评估来说当然希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下有矛盾的。比如极端情况下,我们只搜索出了一个结果,且是准确的,那么a=1,b=0,所以Precision就是100%;但是c为全部‘全部阳性样本-1’,那么Recall就很低了。
而如果我们把所有结果都返回,即都预测结果都是阳性,那么c=0,a和b都很大,那么Recall是100%,但是Precision就会很低。因此在不同的场合中需要自己判断希望Precision比较高或是Recall比较高。高的recall就是‘宁杀错不放过’
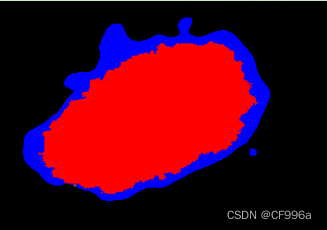
根据同一份数据根据阈值的不同,可以得到下图,其中红色虚线是召回率,暗红色曲线是准确率。

当thres很大时,很多样本都判断为负样本,因此a,b都很小,c很大,因此召回率很低,准确率中a,b都很小,只有分数非常高的样本才会被判定为正样本,a与a+b的比值几乎相等,所以准确率很高。
3,rmse、mape平均绝对百分误差
R M S E = 1 n ∑ t = 1 n ( y t − p r e t ) 2 RMSE=\sqrt{\frac{1}{n}\sum_{t=1}^n(y_t-pre_t)^2} RMSE=n1t=1∑n(yt−pret)2
y t y_t yt表示样本t的真实值, p r e t pre_t pret表示样本t的预测值。
rmse均方根误差,就是误差的平方和再开根号,意义上很好理解。不过有些情况用均方根误差就有些不合情理,比如有两种情况:
a,将价格为100万的房子价格预测为120万;
b,将价格为600万的房子价格预测为620万;
虽然a,b中价格的预测的差值都是20但是可以看出b明显要比a预测的要准一些的。为了改变这种情况就有了mape,公式如下:
M A P E = ∑ t = 1 n ∣ y t − p r e t y t ∣ ∗ 100 n MAPE=\sum_{t=1}^n|\frac{y_t-pre_t}{y_t}|*\frac{100}{n} MAPE=t=1∑n∣ytyt−pret∣∗n100
求取每个样本的误差并除以该样本的真实值,最后除以样本总量做个归一。
以上面a,b为例计算其mape:
M a p e a = 0.2 Mape_a=0.2 Mapea=0.2
M a p e b = 0.034 Mape_b=0.034 Mapeb=0.034
4,例子:
现在有100个病人其中90个是阳性10个是阴性,现在有两个预测方案:
a,100个全部都是阳性;
b,90个阳性中有81个是阳性,剩余的全部为阴性。
分析:
真阳性:
T P R a = 90 / 90 = 1 TPR_a=90/90=1 TPRa=90/90=1
T P R b = 81 / 90 = 0.9 TPR_b=81/90=0.9 TPRb=81/90=0.9
假阳性:
F P R a = 10 / 10 = 1 FPR_a=10/10=1 FPRa=10/10=1
F P R b = 0 / 10 = 0 FPR_b=0/10=0 FPRb=0/10=0
精确度:
P R E a = 90 / 100 = 0.9 PRE_a=90/100=0.9 PREa=90/100=0.9
P R E b = 81 / 90 = 0.9 PRE_b=81/90=0.9 PREb=81/90=0.9
F1:
F 1 a = 2 ∗ T P R a ∗ P R E a / ( T P R a + P R E a ) = 0.947 F1_a=2*TPR_a*PRE_a/(TPR_a+PRE_a)=0.947 F1a=2∗TPRa∗PREa/(TPRa+PREa)=0.947
F 1 b = 2 ∗ T P R b ∗ P R E b / ( T P R b + P R E b ) = 0.9 F1_b=2*TPR_b*PRE_b/(TPR_b+PRE_b)=0.9 F1b=2∗TPRb∗PREb/(TPRb+PREb)=0.9