五、Netty实战技巧:
(一) 多线程编程实践:
1. Netty中使用多线程的技巧:
创建两个NioEventLoopGroup,用于逻辑隔离NIO Acceptor和NIO IO线程。
尽量不要在ChannelHandler中启动用户线程(解码后用于将POJO消息派发到后端业务线程的除外)。
解码要放在NIO线程,在调用解码的Handler中进行,不要切换到用户线程中,完成消息解码。
如果业务逻辑操作非常简单,没有复杂的业务逻辑计算,没有会导致线程被阻塞的磁盘操作、数据库操作、网路操作等,可以直接在NIO线程上完成业务逻辑编排,不需要切换到用户线程。
如果业务逻辑处理复杂,不要在NIO线程上完成,建议将解码后的POJO消息封装成Task,派发到业务线程池中,由业务线程执行,以保证NIO线程尽快被释放,处理其他的I/O操作。
2. Netty框架对多线程的应用:
2.1 对共享的可变数据进行正确的同步:
使用synchronized关键字。
2.2 正确使用锁:
很多刚接触多线程编程的开发者,虽然意识到并发访问可变变量需要加锁,但是对锁定范围,加锁时机和所得协调缺乏认识,往往会导致出现一些问题。
2.3 正确使用volatile:
正确使用volatile需要理解Java的内存模型和多线程编程的基础知识。
根据经验总结,volatile最适合在一个线程写,其他线程读的场景。
2.4 CAS指令与原子类:
互斥同步最主要的问题就是进行线程阻塞和唤醒所带来的性能的额外损耗,因此这种同步被称为阻塞同步,它属于悲观的并发策略,我们称之为悲观锁。
目前,在Java中应用最广泛的非阻塞同步是CAS。
2.5 线程安全类的应用:
2.6 读写锁的应用:
2.7 线程安全性文档说明:
Netty已经对一些重要的类进行线程安全的详细说明。
2.8 不要依赖线程优先级:
(二) 优化建议:
1. 发送队列容量设置上限控制:
Netty的NIO消息发送队列ChannelOutboundBuffer并没有容量上限控制,它会随着消息的积压自动扩展,直到达到0x7ffffff。
如果网络对方处理速度比较慢,导致TCP滑窗长时间为0;或者消息发送方发送速度过快,或者一次批量发送消息量过大,都可能会导致ChannelOutboundBuffer的内存膨胀,这可能会导致系统的内存溢出。
建议优化方式如下:在启动客户端或者服务端的时候,通过启动项的ChannelOption设置发送队列的长度,或者通过 -D 启动参数配置该长度。
2. 回推发送失败的消息:
当网络发生故障时,Netty会关闭链路,然后循环释放待未发送的消息,最后通知监听Listener。这样的处理策略值得商榷,对于大多数用户而言,并不关心底层的网络IO异常,他们希望链路恢复之后可以自动将尚未发送的消息重新发送给对方,而不是简单的销毁。
Netty销毁尚未发送的消息,用户可以通过监听器来得到消息发送异常通知,但是却无法获取原始待发送的消息。如果要实现重发,需要自己缓存消息,如果发送成功,自己删除,如果发送失败,重新发送。这对于大多数用户而言,非常麻烦,用户在开发业务代码的同时,还需要考虑网络IO层的异常并为之做特殊的业务逻辑处理。
下面我们看下Mina(另一个Java网络框架)的实现,当发生链路异常之后,Mina会将尚未发送的整包消息队列封装到异常对象中,然后推送给用户Handler,由用户来决定后续的处理策略。相比于Netty的“野蛮”销毁策略,Mina的策略更灵活和合理,由用户自己决定发送失败消息的后续处理策略。
大多数场景下,业务用户会使用RPC框架,他们通常不需要直接针对Netty编程,如果Netty提供了发送失败消息的回推功能,RPC框架就可以进行封装,提供不同的策略给业务用户使用,例如:
缓存重发策略:当链路发生异常之后,尚未发送成功的消息自动缓存,待链路恢复正常之后重发失败的消息。
失败删除策略:当链路发生异常之后,尚未发送成功的消息自动销毁,它可能是非重要消息,例如日志消息,也可能是由业务直接监听异常并做特殊处理。
3.异常处理要谨慎:
尽管Reactor线程主要处理IO操作,发生的异常通常是IO异常,但是,实际上在一些特殊场景下会发生非IO异常,如果仅仅捕获IO异常可能就会导致Reactor线程跑飞。为了防止发生这种意外,在循环体内一定要捕获Throwable,而不是IO异常或者Exception。
捕获Throwable之后,即便发生了意外未知对异常,线程也不会跑飞,它休眠1S,防止死循环导致的异常绕接,然后继续恢复执行。这样处理的核心理念就是:
某个消息的异常不应该导致整条链路不可用。
某条链路不可用不应该导致其他链路不可用。
某个进程不可用不应该导致其他集群节点不可用。
六、Netty与TCP:
1. Netty解决TCP粘包与拆包问题:
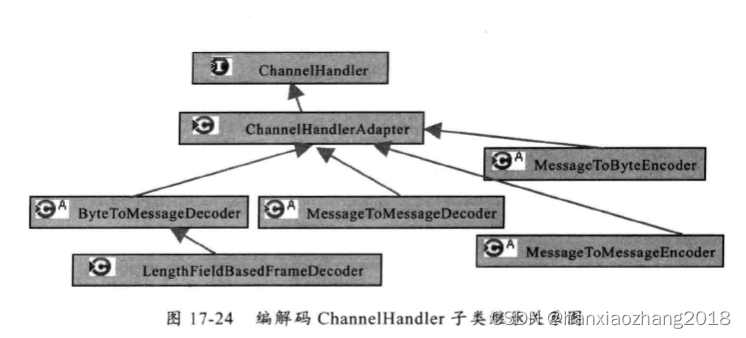
LengthFieldBasedFrameDecoder与LengthFieldPrepender:
Netty提供了LengthFieldBasedFrameDecoder/LengthFieldPrepender,自动屏蔽TCP底层的拆包和粘包问题,只需要传入正确的参数,即可轻松解决“读半包“问题。
发送方使用LengthFieldPrepender给实际内容Content进行编码添加报文头Length字段,接受方使用LengthFieldBasedFrameDecoder进行解码。
七、重点问题:
1. Netty如果保证ChannelPipeline的线程安全?
Netty使用synchronized关键字,保证同步块内的所有操作的原子性。
在加入链表之前,Netty还会检查该Handler是否已经被添加过及其名字是否有重复,如果该Handler不是共享而且被添加,会过抛出异常,如果名字重复,也会抛出异常。
2. 如果保证ChannelHandler的线程安全?(2点)
保证每个Channel尽量都拥有自己的Handler,而不是Handler在多个Channel之间共享。
不推荐使用下面的代码写法,如果想这么写,需要在ServerHandler用注解@ChannelHandler.Sharable明确表明这是一个共享的handler,而且是线程安全的。
ServerBootstrap b = new ServerBootstrap();ServerHandler serverHandler = new ServerHandler();b.group(bossGroup, workerGroup) .channel(NioServerSocketChannel.class) .childHandler(new ChannelInitializer<SocketChannel>() { @Override public void initChannel(SocketChannel ch) { ch.pipeline().addLast(serverHandler); } });
推荐这种写法:ch.pipeline().addLast(new ServerHandler())
尽量不使用共享资源,如果使用了共享资源,在操作时需要对共享资源进行同步,如加锁。
3. Nett的对象池:(重要)
为什么用对象池:
为了避免过多的创建对象和频繁的GC,才使用了对象池。Netty在创建ByteBuf时,先从对象池获取一个对象,如果没有找到可用的对象,才会去创建一个新的ByteBuf对象。
为什么说Recycler是"轻量级"的对象池?
功能简单:对象池只提供了创建和回收的基本接口,没有复杂的诸如有效性检测、空闲回收和拒绝策略等一些复杂功能。
逻辑简单:实现逻辑清晰简单,没有复杂的算法逻辑。
对象池的使用原理:
Netty的缓冲区实现类,通过聚合的方式引入Recycler类。在申请缓冲区时,先从Recycler中获取,如果没有再创建。在缓冲区使用完毕后,也会被回收到Recycler中,方便下次使用时,直接从Recycler中获取。
Recycler类的简单介绍:
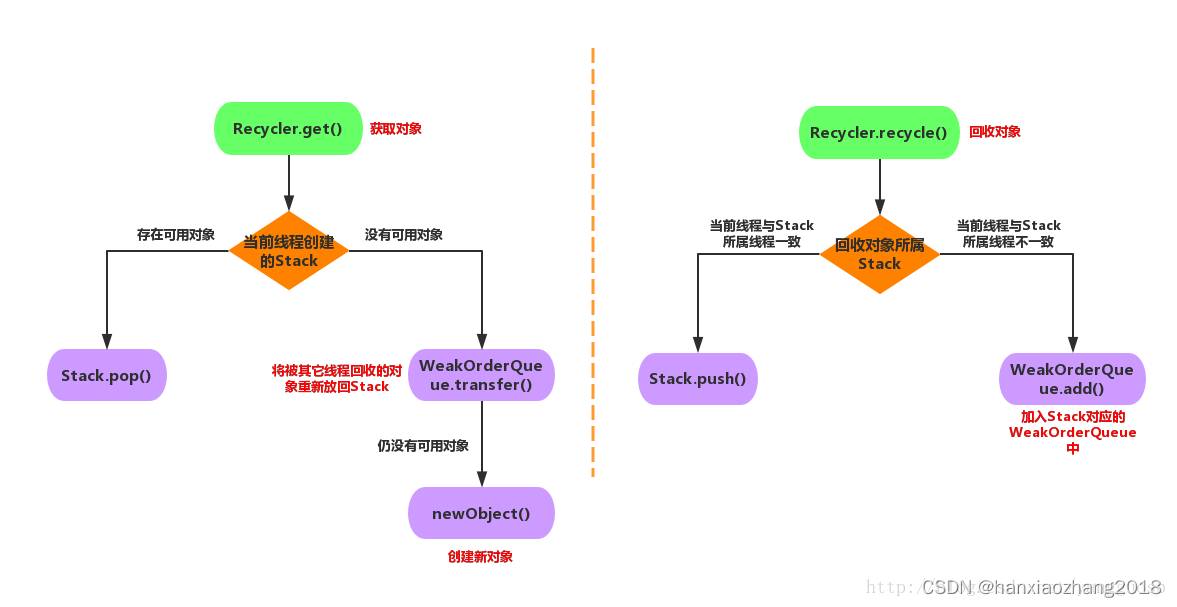
它是一个抽象类,以下是Netty4中实现结构。但是在Netty5中进行了简化,没有了WeakOrderQueue(不去存储其他线程回收到本线程的Stack),FastThreadLocal 也变成了ThreadLocal。
Recycler的核心方法:
get():获取一个对象;
recycle(T, Handle):回收一个对象,T为对象泛型;
newObject(Handle):当没有可用对象时,创建对象;
Recycler的核心属性:
DefaultHandle:对象的包装类,在Recycler中缓存的对象都会包装成DefaultHandle类。
Stack: 存储本线程的回收对象 。
对象的获取和回收对应Stack的pop(获取对象时,从Stack中pop出1个DefaultHandle)和push(回收对象时,将对象包装成DefaultHandle push到Stack中)。
Stack会与线程绑定(每个用到Recycler的线程都会拥有1个Stack),在该线程中获取对象,是从该线程的Stack中pop出的一个可用对象。
WeakOrderQueue:存储其它线程回收到本线程stack的对象。
当某个线程从Stack中获取不到对象时,会从WeakOrderQueue中获取对象。
每个线程的Stack拥有1个WeakOrderQueue链表,链表中每个节点对应1个其它线程的WeakOrderQueue,其它线程回收到该Stack的回收对象,就存储在这个WeakOrderQueue里。
Link:WeakOrderQueue中包含1个Link链表,回收对象存储在链表某个Link节点里,当Link节点存储的回收对象时,会新建1个Link放在Link链表尾。
Recycler获取和回收流程:
获取过程:
使用 FastThreadLocal.get() 从线程对象中获取 InternalThreadLocalMap,然后从InternalThreadLocalMap获取Stack对象,从Stack中pop一个DefaultHandler对象,如果Stack中有值,直接从栈中弹出一个元素。
如果Stack中没有值,那么从WeakOrderQueue获取,遍历WeakOrderQueue的Link,将Link中的元素迁移到Stack。
如果发现用完了的Link,断开链接,在Head中记录释放了多少空间(Link的容量默认是16)。
如果在遍历WeakOrderQueue的过程中,发现其对应的线程已经被垃圾回收了,那么将这个WeakOrderQueue中的所有元素移到Stack中。
Tips:FastThreadLocalThread对象是直接通过一个属性引用InternalThreadLocalMap,而从ThreadLocal中查找性能较差。
回收过程:
如果当前DefaultHandler对应的Stack的线程对象就是当前线程对象,直接存到Stack的数组中即可。
, WeakOrderQueue>> DELAYED_RECYCLED属性中,这个属性的容量默认是CPU个数乘以2。调用WeakOrderQueue的add方法,检查最后一个Link容量是否已满,如果没有满,将值存入,如果满了,检查是否超过Stack允许的WeakOrderQueue的容量(默认是2048),没有超过就创建一个新的Link存入。
Tips:这样可以有效提高并发量,除了构建WeakOrderQueue需要线程安全之外,其他的操作就不需要锁啦。
Recycler的无锁化的思考:
如何实现无锁化?
每个线程对应一个对象池,只有该线程,可以获取对象和回收对象。即实现池的无锁化。
技术点:FastThreadLocal、Recycler中的Stack对象。
如何在其他线程中无锁化回收?
例如线程A分配了对象,经过一系列传递,在线程B中调用回收对象,如何解决?
首先,在当前线程的Stack对象中,创建一个WeakOrderQueue,将需要回收的对象添加到该队列中。然后,再将回收对象挪移到自身的对象池中,实现复用。
技术点:队列的存取不会冲突,可以无锁化。
何时将对象挪到自己的池中来?
当自身的对象池用光的时候,才将垃圾箱中的对象挪移过来。
回收方式 -> 计数回收:
通过某种自增计数handleRecycleCount,达到某个设定阈值时,将回收掉。Netty 值默认设置为8,池内的对象只能用8次,就回收掉。
4. Netty的内存池:(重要)
内存分配思想:
现有内存最大化利用,减少内存碎片。
Netty底层的内存分配是采用 jemalloc 【G 马洛克】算法思想。它主要通过Arena和Thread Cache(核心思想)技术,在多线程场景下也有出色的内存分配效率。
Arena:分而治之思想的体现,将任务派发给多个人,每个人独立管理,互不干涉,即避免线程竞争。
Thread Cache机制:每个线程有自己的内存缓存器,内存分配在这个线程内完成,就不需要和其他线程竞争。
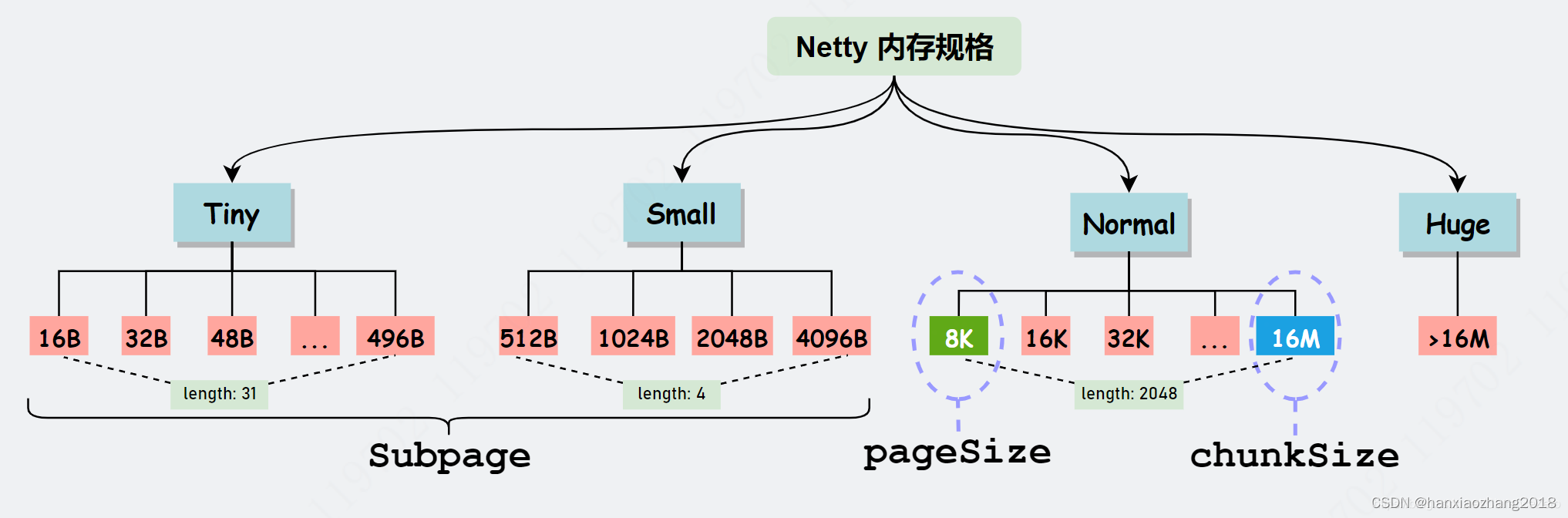
内存规格:
内存大小划分(四类,从小到大):Tiny [0B,512B)、Small [512B,8K) 、Normal [8K,16M]、 Huge (16M, 无限大)
Tips:使用内存时,会上向取整,比如500B,向上取整512B,它就是Samll类型。
Normal类型:Netty默认使用,Normal类型向操作系统申请的内存大小为16MB。
Huge类型(它属于大型缓存):内存大小大于16MB,不做缓存、不做池化,直接以 Unpool 的形式分配内存,用完后回收。
内存池结构:
1. PoolArena:
概念:PoolArena是指向系统或JVM堆申请一块内存区域,它与Memory Arena概念的类似。
类分:HeapPoolArena和DirectPoolArena。
特点:Netty会固定分配多个Arena,Arena默认数量与CPU 核数有关。创建多个Arena 用来缓解资源竞争的问题,从而提高内存分配效率。
数据结构:
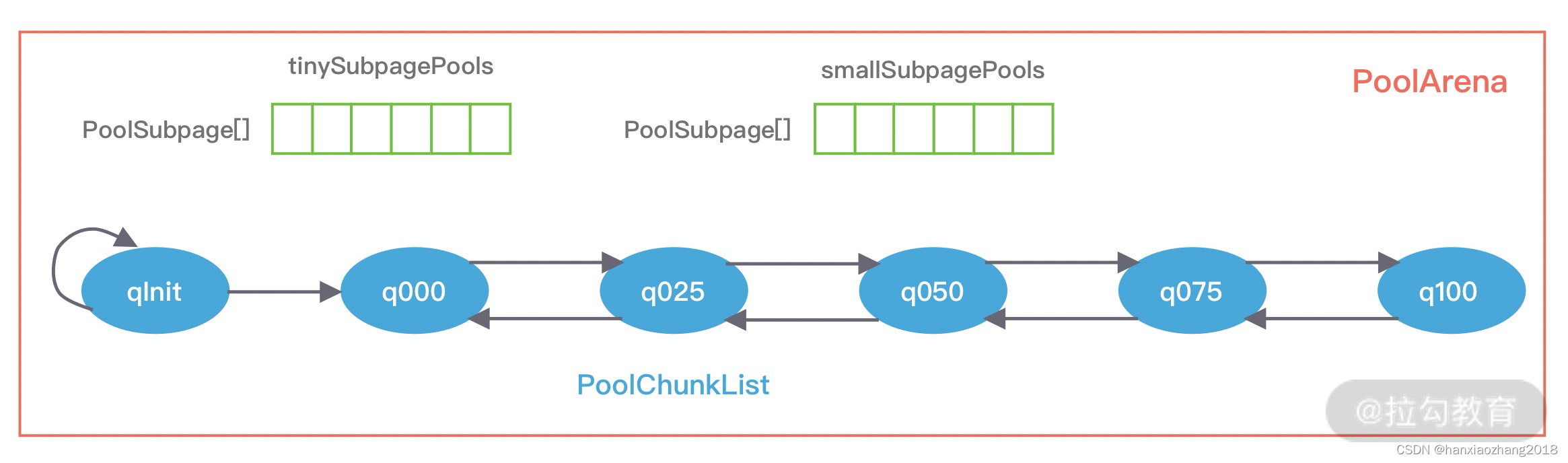
包含两个PoolSubpage类型的数组(分别存放Tiny和Small 类型的内存块)和六个PoolChunkList(分别存储不同利用率的Chunk),构成一个双向循环链表。
PoolArena对应实现了PoolSubPage和PoolChunk中的内存分配,其中PoolSubpage用于分配小于8K的内存,PoolChunkList用于分配大于8K的内存。
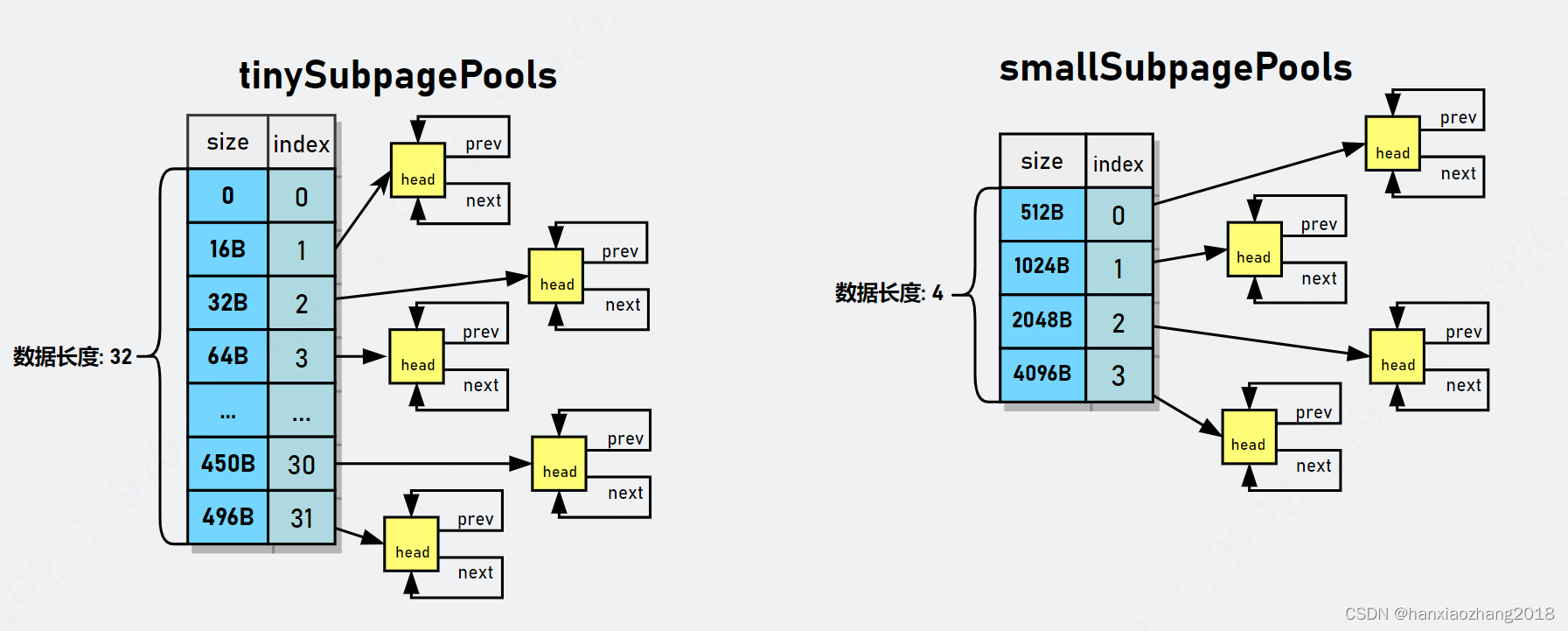
PoolSubpage类型的数组有两个规格:tinySubpagePools和smallSubpagePools。对于Tiny规格,内存单位最小为16B,按16B依次递增,共31种情况,再加上数据0位置代表0B,一种32种情况;对于Small规格,内存单位最小为512B,共分为 512B、1024B、2048B、4096B四种情况,分别对应两个数组的长度大小。
2. PoolChunkList:
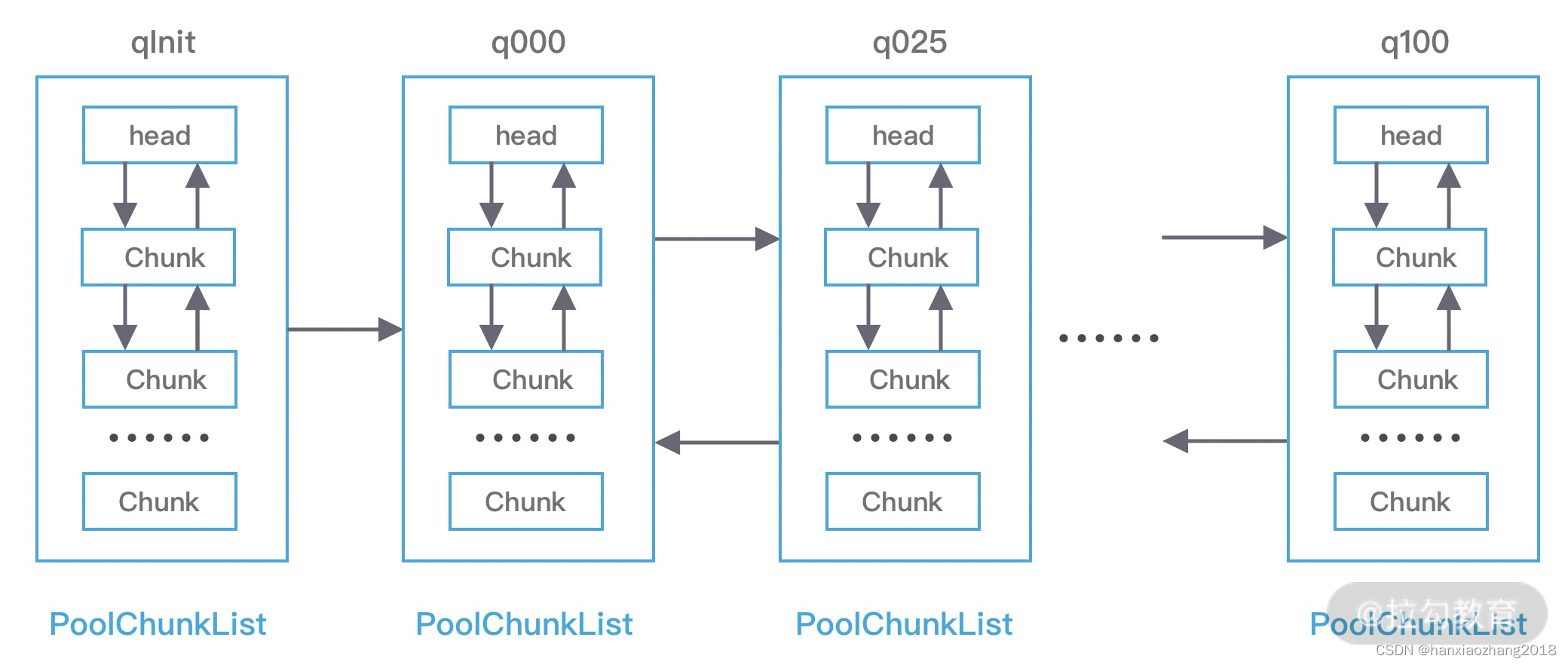
概念:PoolChunkList负责管理多个PoolChunk的生命周期,同一个ChunkList中存放内存使用率相近的Chunk,Chunk以双向链表的形式连接在一起。
PoolArena初始化了6个PoolChunkList,分别为 qInit、q000、q025、q050、q075、q100,它代表不同的内存使用率:
qInit:内存使用率为0 ~ 25% 的Chunk;q000:内存使用率为1 ~ 50% 的Chunk;
q025:内存使用率为25% ~ 75% 的Chunk;q050:内存使用率为50% ~ 100% 的Chunk;
q075:内存使用率为75% ~ 100% 的Chunk;q100:内存使用率为100% 的Chunk。
Tips:每个PoolChunkList上下线有重叠,避免因为内存使用率在临界值,一直移动,造成性能损耗。
3. PoolChunk:
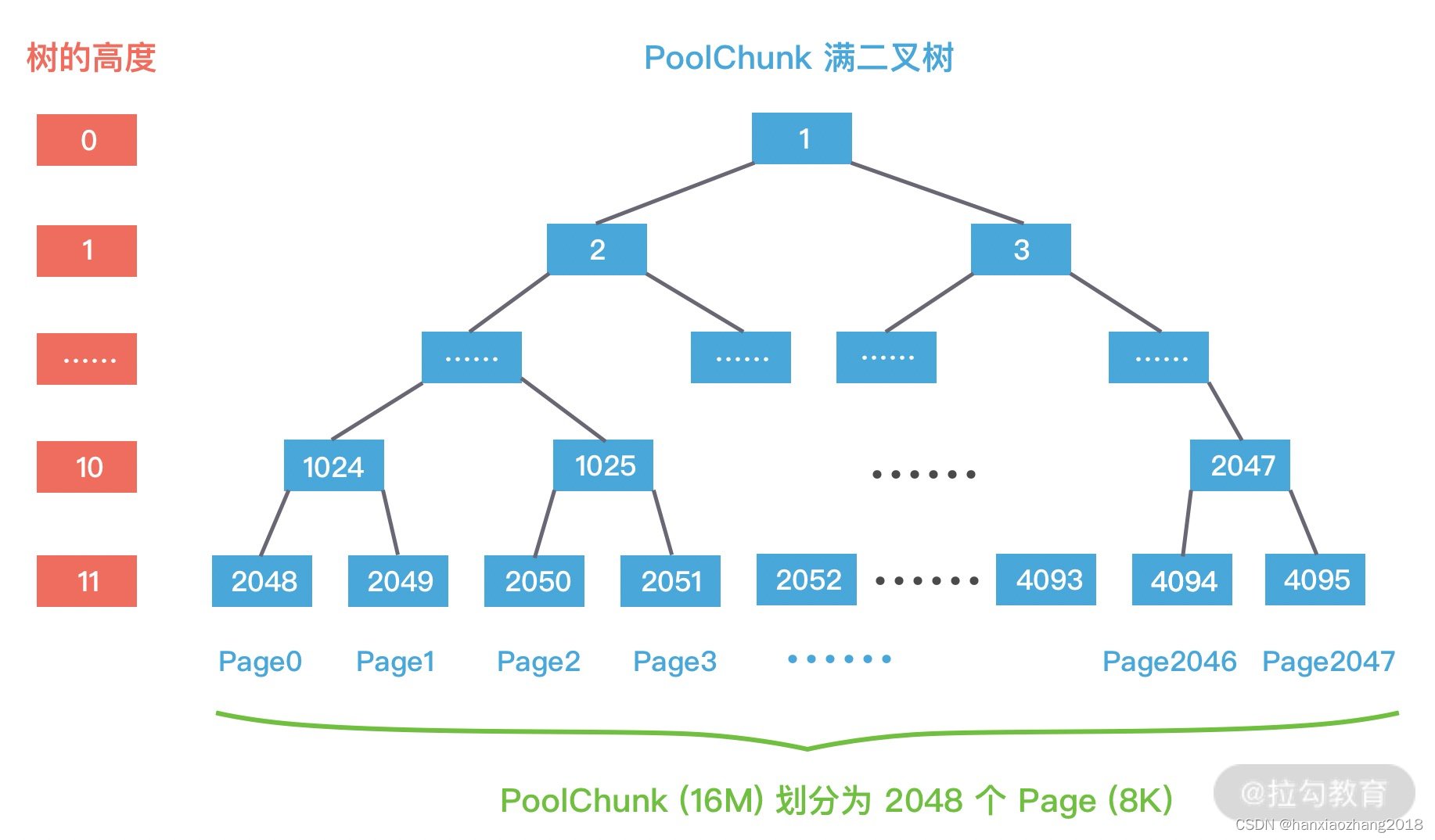
Netty内存的分配和回收都是基于PoolChunk完成的,PoolChunk是真正存储内存数据的地方,每个PoolChunk的默认大小为16M。
PoolChunk可以理解为Page的集合,一个PoolChunk分配成2048个Page,最终形成一颗满二叉树。
二叉树中所有子节点的内存,都属于其父节点管理。
每个节点都记录了自己在整个Memory Arean中的偏移地址,当一个节点代表的内存区域被分配出去之后,这个节点就会标记为已分配。
4. PoolPage:
PoolPage是 PoolChunk用于管理内存的基本单位。
每个Page默认大小是8K。
5. PoolSubPage:
在小内存分配的场景下(分配的内存大小小于一个Page,即内存小于8K),会使用PoolSubpage进行管理。
PoolSubpage是如何记录内存块的使用状态的呢?
PoolSubpage通过位图bitmap记录子内存是否已经被使用,bit 的取值为0或者1。如下图所示:
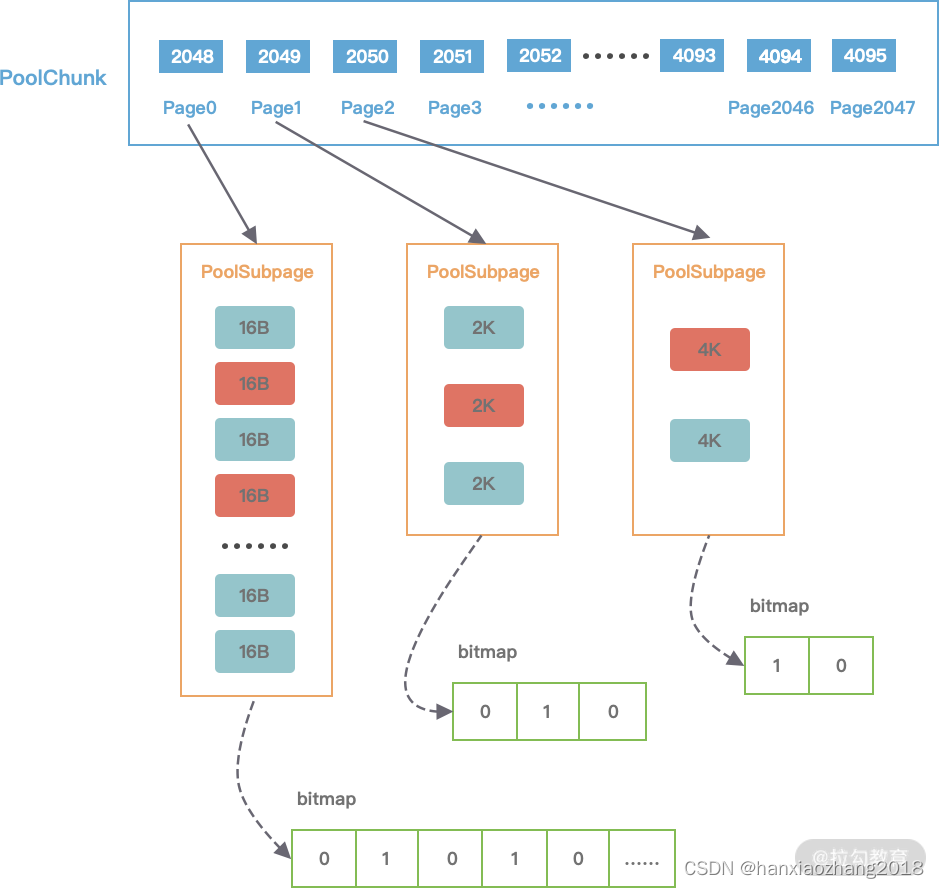
PoolSubpage和PoolArena之间是如何联系起来的?
PoolArena在创建时,会初始tinySubpagePools和smallSubpagePools两个PoolSubpage类型的数组,数组的大小分别为 32 和 4。
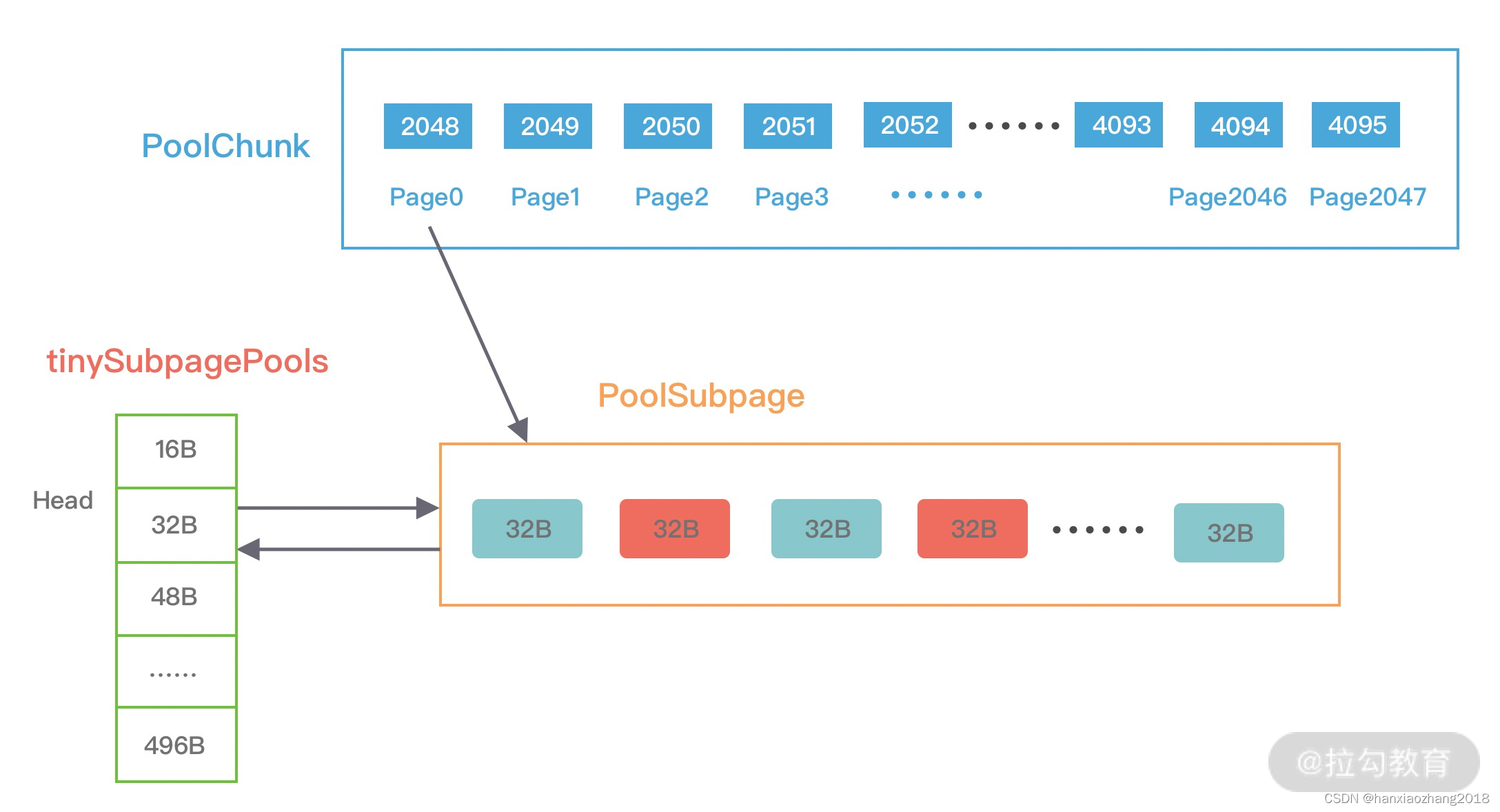
假如现在需要分配20B的内存,会向上取整为32B,从满二叉树的第11层找到一个PoolSubpage节点,并把它等分为 8KB/32B = 256个小内存块,然后找到这个PoolSubpage节点对应的PoolArena,将PoolSubpage节点与tinySubpagePools[1] 对应的head节点连接成双向链表,形成下图所示的结构:
6. PoolThreadCache & MemoryRegionCache
PoolThreadCache的概念:PoolThreadCache是本地线程缓存的意思。当内存释放时,Netty并没有将缓存归还给PoolChunk,而是使用 PoolThreadCache缓存起来,当下次有同样规格的内存分配时,直接从PoolThreadCache取出使用即可。
PoolThreadCache的缓存数据类型:Tiny、Small、Normal 三种类型的数据,而且根据堆内和堆外内存的类型进行了区分。
PoolThreadCache的重要数据结构:MemoryRegionCache。
MemoryRegionCache 有三个重要的属性,分别为 queue,sizeClass 和 size,下图是不同内存规格所对应的 MemoryRegionCache属性取值范围:
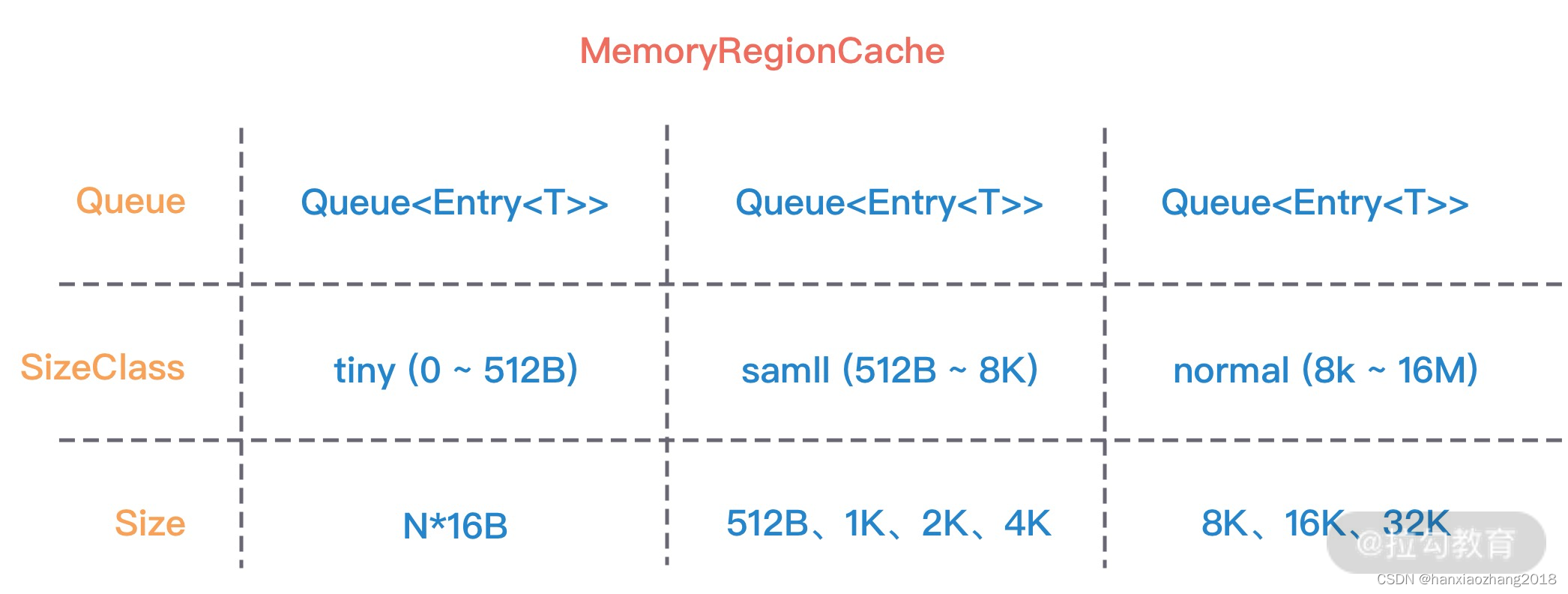
MemoryRegionCache 实际就是一个队列,当内存释放时,将内存块加入队列当中,下次再分配同样规格的内存时,直接从队列中取出空闲的内存块。
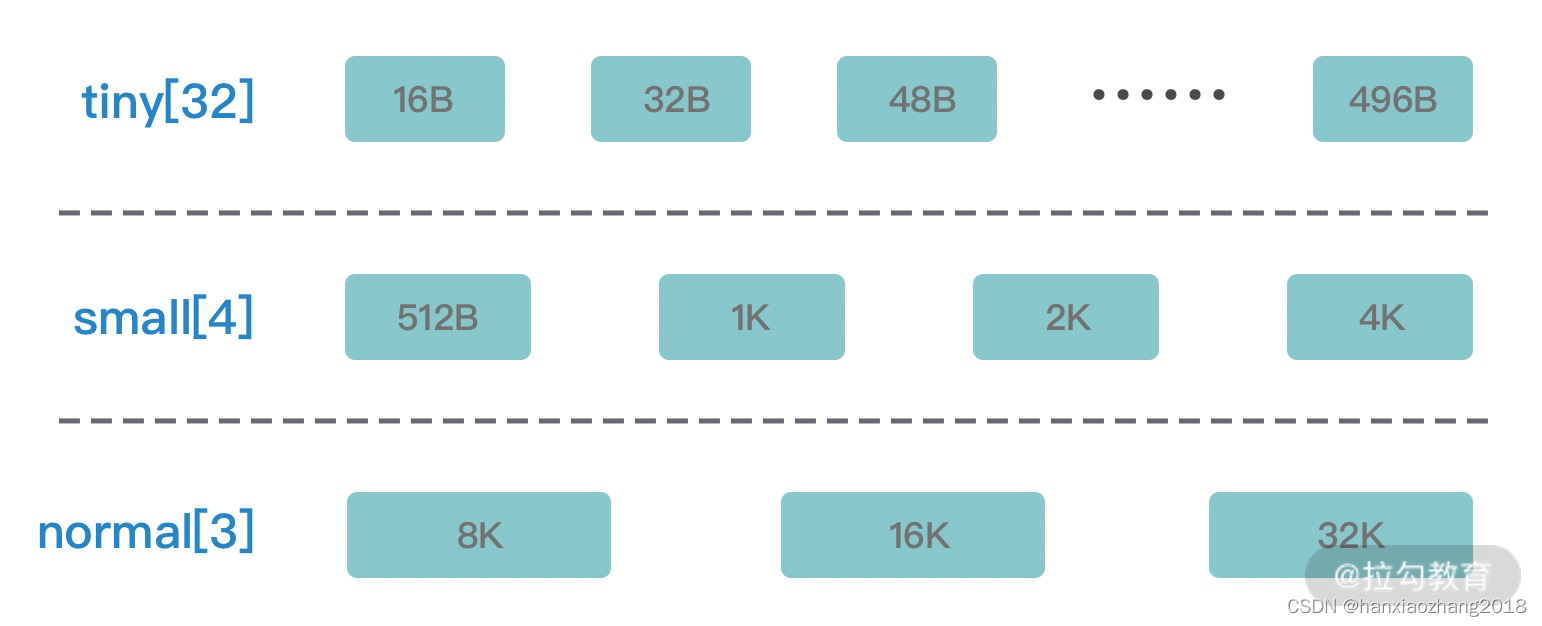
PoolThreadCache将不同规格大小的内存,使用单独的MemoryRegionCache 维护,如下图所示,图中的每个节点都对应一个 MemoryRegionCache,例如Tiny场景下对应的32种内存规格会使用32个MemoryRegionCache维护,所以PoolThreadCache源码中Tiny、Small、Normal 类型的MemoryRegionCache数组长度分别为 32、4、3。
内存分配原理:
Netty中负责线程分配的组件有两个:PoolArena和PoolThreadCache。PoolArena是多个线程共享的,每个线程会固定绑定一个 PoolArena,PoolThreadCache是每个线程私有的缓存空间,如下图所示:

Netty根据不同内存规格采用不同的分配策略:
分配内存大于8K时,PoolChunk中采用的Page级别的内存分配策略。
分配内存小于8K时,由PoolSubpage负责管理的内存分配策略。
分配内存小于8K 时,为了提高内存分配效率,由PoolThreadCache本地线程缓存提供的内存分配。
1. Page级别的内存分配:
每个PoolChunk默认为16M,PoolChunk是通过伙伴算法管理多个Page,每个PoolChunk被划分为2048个Page,最终通过一颗满二叉树实现。伙伴算法尽可能保证了分配内存地址的连续性,可以有效地降低内存碎片。
具体分配见文章
2. Subpage级别的内存分配:
在分配小于8K的内存时,PoolChunk不在分配单独的Page,而是将Page划分为更小的内存块,由PoolSubpage进行管理。e 已经没有可分配的内存块,此时需要从 PoolArena 中 tinySubpagePools[1] 的双向链表中删除。
具体分配见文章
3. PoolThreadCache的内存分配:
PoolArena分配的内存被释放时,Netty并没有将缓存归还给PoolChunk,而是使用PoolThreadCache缓存起来,当下次有同样规格的内存分配时,直接从 PoolThreadCache 取出使用即可。
分配流程:
分配Tiny、Small、Normal类型的内存时,优先尝试从PoolThreadCache 中进行分配:
1. 对申请的内存大小做向上取整,例如,20B的内存大小会取整为32B。
2. 当申请的内存大小小于8K时,分为Tiny和Small 两种情况,分别都会优先尝试从PoolThreadCache 分配内存,如果 PoolThreadCache分配失败,才会走PoolArena的分配流程。
3. 当申请的内存大小大于8K,但是小于Chunk的默认大小16M,属于Normal 的内存分配,也会优先尝试PoolThreadCache 分配内存,如果PoolThreadCache 分配失败,才会走PoolArena的分配流程。
当申请的内存大小大于Chunk的16M,则不会经过PoolThreadCache,直接进行分配。
内存回收原理:
当用户线程释放内存时,会将内存块缓存到本地线程的PoolThreadCache缓存中,这样在下次分配内存时会提高分配效率。
但是当内存块被用完一次后,再没有分配需求,Netty是如何实现内存释放的?Netty记录了allocate()的执行次数,默认每执行 8192 次,就会触发PoolThreadCache调用一次 trim() 进行内存整理,会对PoolThreadCache中维护的六个MemoryRegionCache数组分别进行整理。