目录
引用头指针的好处:
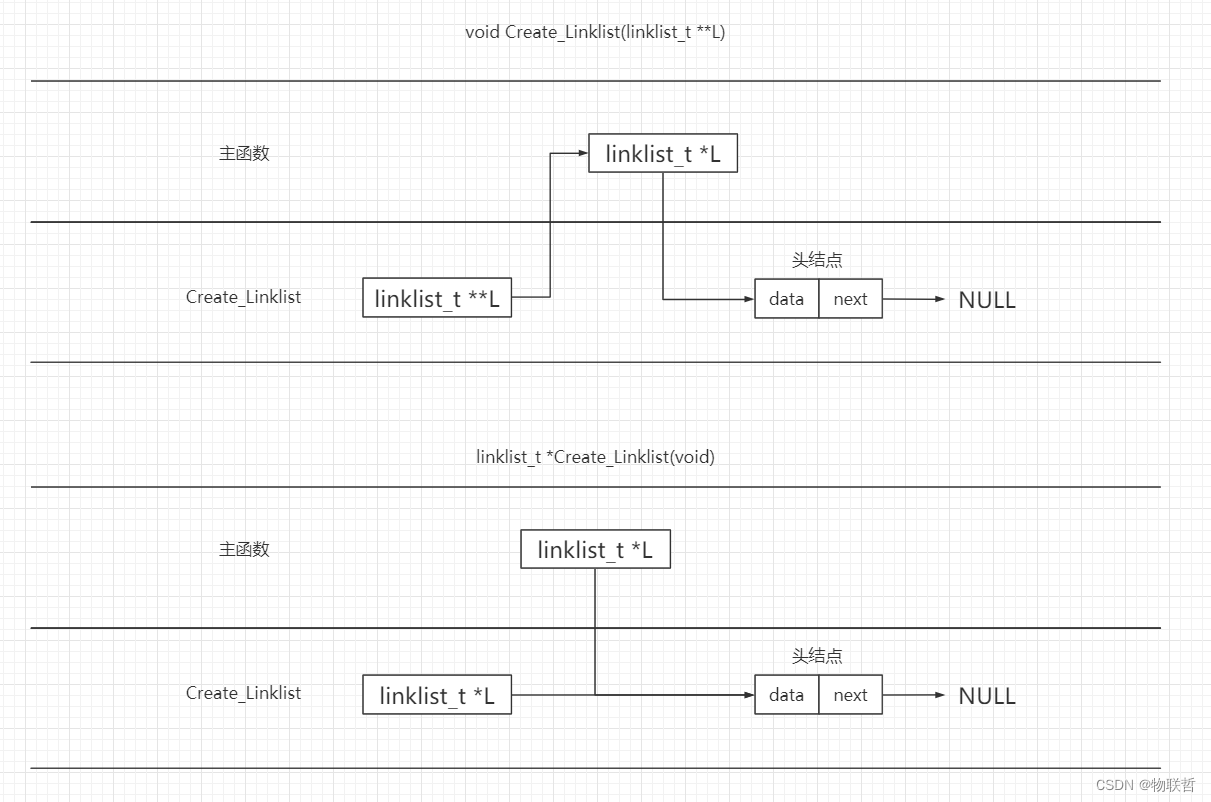
1.结点的定义和初始化单链表
2.判断单链表是否为空表
3.销毁单链表
4.清空单链表,头结点和头指针还在
5.求单链表表长
6.取单链表中指定位置的数据
7.按值查找,返回数据所在的地址,时间复杂度为O(n)编辑
8.按值查找,返回数据所在位置序号,时间复杂度为O(n)
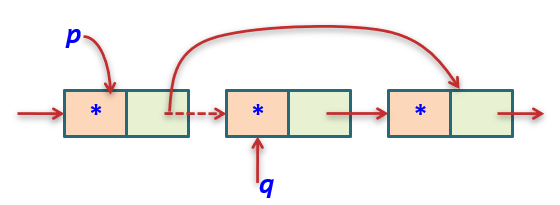
9.在第pos个元素之前插入数据元素e
10.删除第i个结点,时间复杂度为O(1),因为不需要移动结点,只需修改指针
11.单链表的建立:头插法
12.单链表的建立:尾插法
13.合并两个链表
引用头指针的好处:
1.使得在链表的第一个位置上的操作和在表的其他位置上的操作一致。
2.空表和非空表的处理一致。
1.结点的定义和初始化单链表
#include <stdio.h>//定义单链表的结点
typedef struct Lnode{ //node是结点的英文Elemtype data; //存放数据,Elemtype是虚拟的类型,真实情况这里可以是int、float等类型struct Lnode* next; //存放指向下一个结点的指针,而这个指针的类型是struct Lnode*型
}Lnode //将Lnode定义为struct Lnode型
typedef struct Lnode* Linklist; //Linklist表示指向struct Lnode这个结构体的指针
//L链表可以用Linklist L或Lnode *L表示, 指向某个结点的指针可以用Lnode *p或Linklist p表示//初始化单链表,L是一个指向单链表的指针
void initlist(Linklist L)
{L = (Linklist)malloc(sizeof(Lnode)); //头结点的类型为Lnode,头指针的类型为LinklistL->next = NULL;
}
//总结初始化:
//1.生成一个头结点(分配空间),将头指针L指向头结点,也就是头指针L赋值为头结点的地址
//2.将头结点的指针域赋值为空NULL2.判断单链表是否为空表
//判断单链表是否为空表
int is_Emptylist(Linklist L)
{//L指向的是头结点,头结点的指针域(L->next)为空,没有下一个结点,就是空表if(L->next == 0) return 0; //是空表elsereturn 1; //不是空表
}3.销毁单链表
//销毁单链表
void destroylist(Linklist L)
{Lnode* p; //定义一个指针p来指向结点,而结点是Lnode型,所以p的类型为Lnode *while(L != NULL) //NULL是最后一个结点的指针域,所以当L为NULL时表示最后一个结点已经销毁了{p = L; //将L的值赋给p,这样p也指向了L指向的结点L = L->next; //将下一个结点的地址放在当前结点的指针域(L->next)里,这样L就指向了下一个结点free(p); //销毁p指向的结点}
}
//总结销毁单链表:
//1.引入一个指针p来指向结点
//2.将L的值赋给p
//3.将L指向下一个结点
//4.销毁p指向的结点
//5.将L的值赋给p,此时L不再指向头结点,而是下一个结点,所以p指向了下一个结点
//6.将L指向下一个结点
//重复p指向L结点,L指向下一个结点,销毁p指向的结点,p指向L结点.......直到L为NULL4.清空单链表,头结点和头指针还在
//清空单链表,头结点和头指针还在
void clearlist(Linklist L)
{Lnode *p,*i; //引入两个指针变量指向结点,p指向当前要清除的结点,i指向p的下一个结点p = L->next; //将p指向首元结点,从首元结点开始清空,因为要保留头结点while(p != NULL) /*最后一个结点时,p->next(为NULL)赋给i,最后一个结点清空后i(为NULL)赋给p,这样就表示整个表就清空了*/{i = p->next; //i指向了下一个结点,这样上一个结点就可以清除了free(p); //清除结点p = i; //将p也指向i指向的结点}L->next = NULL; //将头结点的指针域设为NULL
}
//总结清空单链表
//1.将p指向首元结点(头结点的下一个结点)
//2.将p结点的指针域(next)赋给i指针,使i指向p的下一个结点
//3.清空p指针指向的结点
//4.将i赋给p,使p指向i指向的结点
//5.将p结点的指针域赋给i指针,使i再指向下一个结点,以此重复到p为NULL
//6.将L指向的结点,也就是头结点的指针域设为NULL5.求单链表表长
//求单链表表长
int listlength(Linklist L)
{Lnode* p;int i = 0; //用来计数,表示有几个结点,记得赋初值为0p = L->next; //L->next指向的是首元结点,所以p指向首元结点while(p != NULL) {i++; //第一次进循环,p已经是L->next了,如果p为null就代表没有首元结点,不会进入循环,此时i为0。p = p->next; //将p指向下一个结点}return i; //i就是表长
}6.取单链表中指定位置的数据
//取单链表中指定位置的数据
Elemtype GetElemList(Linklist L, int pos)
{Lnode* p;int k = 1; //k当做计数,初值为1,因为pos不是下标,所以不能为0p = L->next; //从首结点开始找while((p != NULL)&&(k<pos)) //p为NULL退出循环表示链表找完了也没找到或者链表是空的。k等于pos时退出循环,表示找到了{p = p->next;k++;}if((p == NULL)||(k>pos)) //k>pos代表pos为0或负数,因为k初值为1。return ERROR; //找不到return p->data; //找到了会跳出循环,直接执行此语句将找到的值return回去。没找到会执行上面的if语句,不会执行此语句
}
7.按值查找,返回数据所在的地址,时间复杂度为O(n)

//按值查找,返回数据所在的地址
Lnode* SearchPos(Linklist L, Elemtype e)
{Lnode* p;p = L->next; //从首元结点开始找while((e != p->data)&&(p != NULL)){ p = p->next;}return p; //若找不到,就意味着p为NULL,此时返回NULL。找到了,返回的p就是数据所在地址
}
8.按值查找,返回数据所在位置序号,时间复杂度为O(n)
//按值查找,返回数据所在位置序号
int SearchNum(Linklist L, Elemtype e)
{Lnode* p;int k = 1; //用来计数p = L->next; //从首元结点开始找while((p != NULL)&&(e != p->data)){p = p->next;k++;}if(e == p->data)return k; //找到了,返回位置序号elsereturn ERROR; //else就是p为NULL,找不到
}9.在第pos个元素之前插入数据元素e
找到第pos-1个结点的时间复杂度为O(n),但之后,不管在第pos-1位置插入几个元素,时间复杂度都为O(1)。

//在第pos个元素之前插入数据元素e
void insertlist(Linklist L, Elemtype e, int pos)
{int j = 1; //用来计数Lnode* p, *s; //s用来指向新加入的结点p = L; //从头结点开始,因为如果是在第1个元素之前插入,就应该是在头结点的后面插入while((p != NULL)&&(j<pos)) /* j=pos时循环结束,此时表示找到了,且p指向的是pos的前一个结点。或者,当p=NULL时循环结束,表示找不到*/{p = p->next; //找下一个结点j++;}if((p == NULL)||(j>pos)) /* pos不能为0或负数,所以j>pos是return ERROR。且pos不能大于表长,当pos大于表长的情况就是循环结束后p==NULL,此时应return ERROR*/return ERROR; s = (Linklist)malloc(sizeof(Lnode)); //给新插入的结点开辟空间,用来存放es->data = e; //将e存放在新结点的数据域里s->next = p->next; //将s的指针域指向原来的下一个结点p->next = s; //将p的指针域指向新的结点
}10.删除第i个结点,时间复杂度为O(1),因为不需要移动结点,只需修改指针
找到第i-1个结点的时间复杂度为O(n),但之后不管插入几个元素,时间复杂度为O(1)。
void DeleteNode(Linklist L, int i)
{Lnode *p, *s;int j = 0;p = L;while((p != NULL)&&(j<i-1)) //找第i-1个结点{p = p->next;j++;}if((p == NULL)||(j>i-1))return ERROR;s = p->next; //循环退出后p指向i-1个结点。这里是将第i个结点的地址暂存到s里p->next = s->next; //将p指向的结点里面存下一个结点的地址free(s); //删除s指向的结点
}11.单链表的建立:头插法
时间复杂度为O(n)

void createlist_H(Linklist L, int n) //n为创建的结点个数
{int i;Lnode* p;L = (Linklist)malloc(sizeof(Lnode)); //给头指针分配空间,也就是创建头结点L->next = NULL; //最开始是空表,所以没有首元结点的地址L->next为NULLfor(i = n; i>0; i--) //循环n次,创建n个结点{p = (Lnode*)malloc(sizeof(Lnode)); //p作为新结点scanf("%d",&p->data); //让用户输入数据p->next = L->next; //将L后面的结点(头结点后的结点)连在p的后面L->next = p; //将p插在头部作为首元结点}
}12.单链表的建立:尾插法
时间复杂度为O(n)

void createlist_R(Linklist L, int n)
{Lnode *r, *p; //r始终指向最后一个结点。p始终作为尾结点,插入到尾部int i;L = (Linklist)malloc(sizeof(Lnode));L->next = NULL;r = L; //首先是空表,最后一个结点也就是头结点,所以r=Lfor(i = 0; i < n; i++) //循环n次{p = (Lnode*)malloc(sizeof(Lnode)); //开辟新结点scanf("%d", &p->data); //用户输入数据p->next = NULL; //p作为尾结点所以指针域为NULLr->next = p; //将p插入到当前链表的尾部r = p; //r始终指向尾结点}
}13.合并两个链表
Linklist mergeTwoLists(Linklist list1, Linklist list2) {//创建一个新链表,此链表是带头结点的链表,list1和list2不是Linklist list3 = new ListNode();//创建一个新结点来指向链表3ListNode* p3 = list3;//当list1遍历完或list2遍历完时,循环退出while ((list1 != nullptr) && (list2 != nullptr)){//list1的元素小if (list1->val <= list2->val){//将list1指向的结点插入链表3p3->next = list1;//将指向链表3的结点指向下一个结点p3 = p3->next;//list1指向下一个结点list1 = list1->next;}//list2的元素小else{//将list2指向的结点插入链表3p3->next = list2;//将指向链表3的结点指向下一个结点p3 = p3->next;//list2指向下一个结点list2 = list2->next;}}//循环结束,表示有一个链表已经遍历完了,而且因为是有序链表,所以直接将另一个链表的剩下的结点插入到链表3里//或者用三目运算符:list3->next = p1 ? p1 : p2;if (list1 == nullptr){p3->next = list2;}else{p3->next = list1;}return list3->next;
}