目录
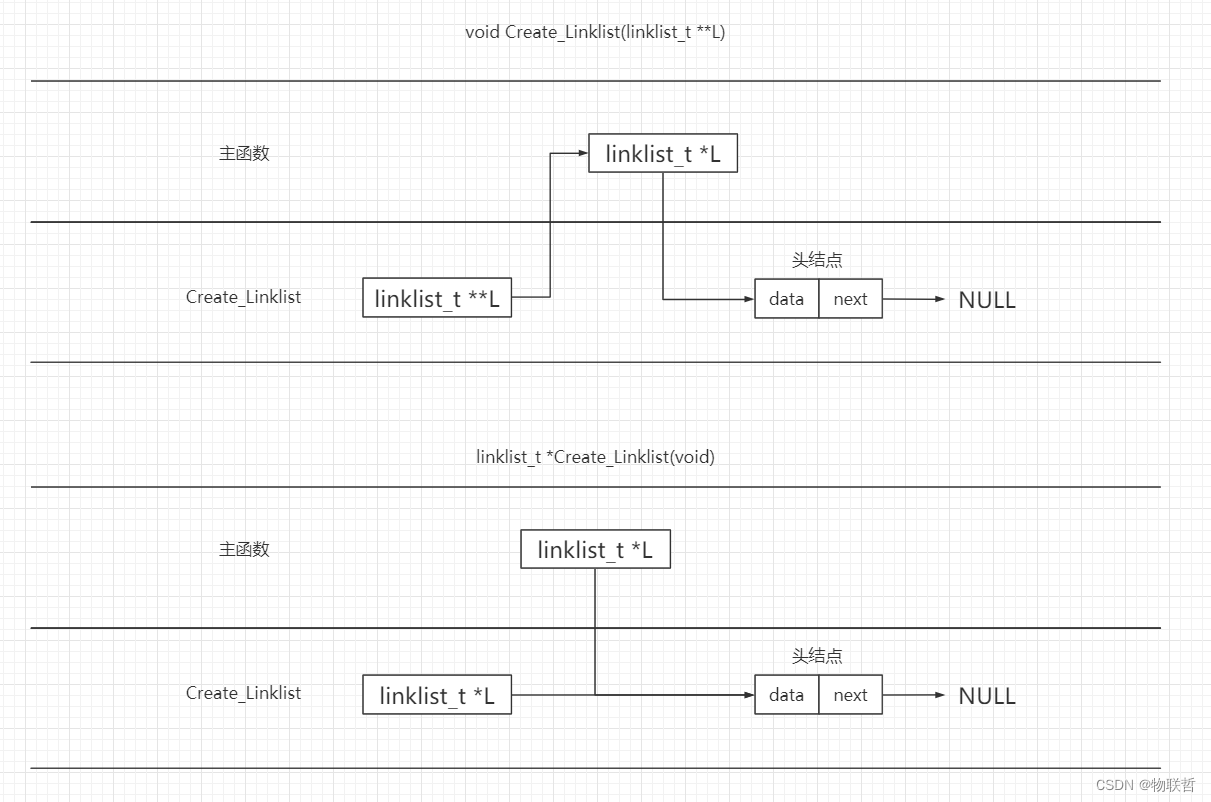
结构体,这里讨论的都是带头节点的
一、单链表建立
1、头插法:利用头指针控制链表节点的增加
代码:
2、尾插法:
二、遍历
三、插入:(pos代表要插入的位置)
四、删除
五、销毁
六、查找
单链表的查找分为按位查找和按值查找(只讨论带头结点)
七、带头结点的插入排序
八、删除无序链表中值重复出现的节点(两种解决方法)
九、反转一个单链表
十、单链表的归并排序
十一、待补充
总结:单链表基本操作集合
代码:myself
结构体,这里讨论的都是带头节点的
typedef struct Node{int value;struct Node* next;
}*Link;
一、单链表建立
1、头插法:利用头指针控制链表节点的增加
核心:
newNode->next = head->next;
head->next = newNode;

代码:
//头插法创建链表
Link headCreateLink(int n){//头指针初始化部分Link head,newNode;head = (Link)malloc(sizeof(struct Node));head->next = NULL;while(n--){newNode = (Link)malloc(sizeof(struct Node));scanf("%d",&newNode->value);// 主要核心,新节点指向头指针的下一节点,头指针指向新节点。newNode->next = head->next;head->next = newNode;}return head;
}
2、尾插法:
需要借助一个辅助指针rear,指向当前链表最后一个节点,每次处理辅助指针指向的节点和新增的节点的关系即可。
核心:
newNode->next = rear->next;
rear->next = newNode;
rear = rear->next;

//尾插法创建链表
Link rearCreateLink(int n){//头指针初始化以及rear指针初始化指向头指针。Link head,rear,newNode;head = (Link)malloc(sizeof(struct Node));head->next = NULL;rear = head;while(n--){newNode = (Link)malloc(sizeof(struct Node));scanf("%d",&newNode->value);// 主要核心,新节点指向rear的下一节点,rear的下一节点指向新节点(顺序切记不可搞反),rear指向新节点。newNode->next = rear->next;rear->next = newNode;rear = rear->next;} return head;
}
二、遍历
void TraverseList( LinkList L )
{LinkList p = L->next ;while( p ){printf( "%d " , p->data ) ;//可以对结点的值进行修改p = p->next ;}printf( "\n" ) ;
}三、插入:(pos代表要插入的位置)
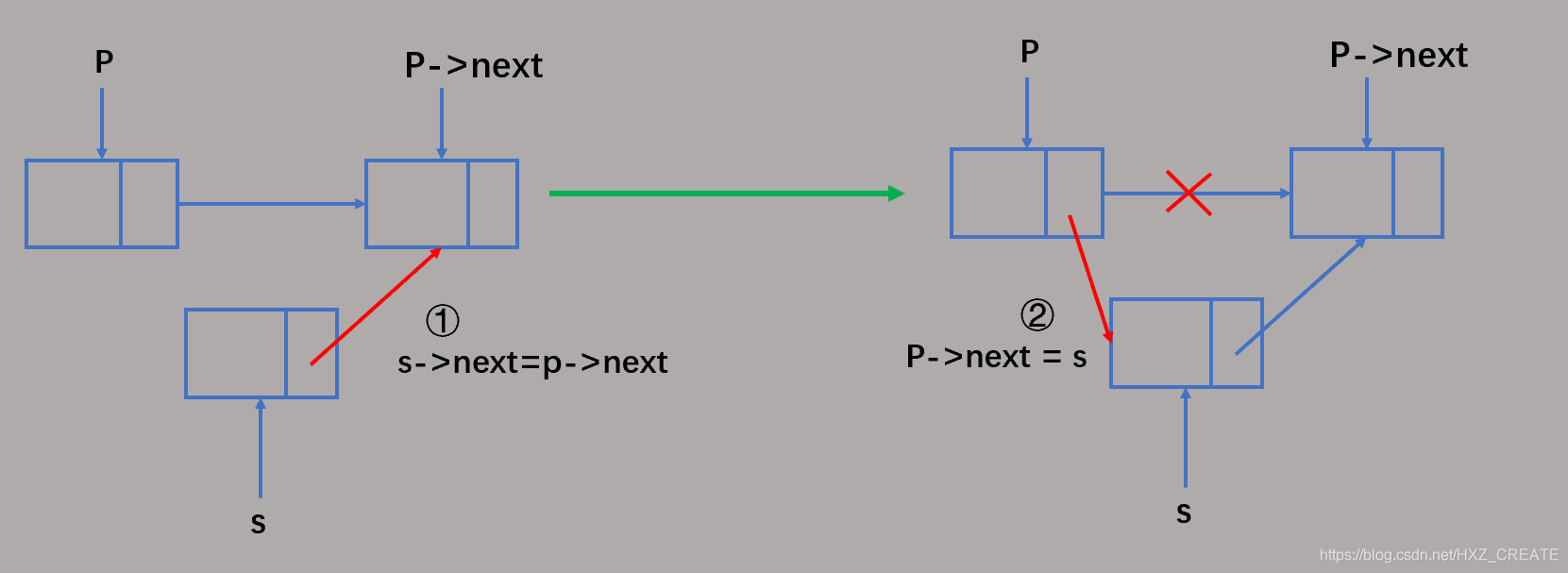
Status ListInsert( LinkList *L , int pos , int e )
{int j = 1 ;LinkList p , s ;p = *L ;while( p && ( j < pos ) ){p = p->next ;j++ ;}if( !p || ( j > pos ) )return ERROR ;s = ( LinkList )malloc( sizeof( Node ) ) ;s->data = e ;s->next = p->next ;p->next = s ;return OK ;
}四、删除

Status ListDelete( LinkList *L , int pos , int *val )
{int j = 1 ;LinkList p , q ;p = *L ;while( ( p->next ) && j < pos ){p = p->next ;j++ ;}if( !( p->next ) || ( j > pos ) )return ERROR ;q = p->next ; //注意这行不能和下面互换位置p->next = q->next ;*val = q->data ;free( q ) ;//一定要free掉要删除的结点,防止内存溢出return OK ;
}
五、销毁
销毁单链表:
Status DestoryList( LinkList *L )
{LinkList p , q ; //如果只是free(*L)是不够的,因为这样的话只是删除了链表的头节点,而且直接这样删除的话就找不到头节点以后的节点了p = ( *L )->next;while( p ){q = p->next ;free( p ) ;p = q ;}( *L )->next = NULL ;return OK ;
}
六、查找
单链表的查找分为按位查找和按值查找(只讨论带头结点)
根据值查找:
LinkList *GetByNum(LinkList *head,int num){LinkList *p=head->next;while(p!=NULL){if(p->data==num)return p;//找到返回结点指针 p=p->next;} return NULL;//找不到返回NULL
}
根据节点查找:
LinkList *GetById(LinkList *head,int i){int j=0;if(i<=0)return NULL;//保证序号合法 LinkList *p=head;while(p->next!=NULL){p=p->next;j+=1;//以头节点指向的节点为序号1对应的节点 } if(i==j)return p;return NULL;
}
//求表的长度
int Length(LinkList L){int len = 0;LNode *p = L;while(p->next!=NULL){p=p->next;len++;}return len;
}
七、带头结点的插入排序
c语言带头节点的单链表插入排序_ejdjdk的博客-CSDN博客_c语言链表头插法排序
八、删除无序链表中值重复出现的节点(两种解决方法)
删除无序链表中值重复出现的节点(两种解决方法)_Whynotwu的博客-CSDN博客_无序单链表删除重复节点
九、反转一个单链表
【图文解析】反转一个单链表_giturtle's blog-CSDN博客_反转链表
十、单链表的归并排序
怎样实现链表的归并排序_weixin_30644369的博客-CSDN博客
写给自己看的单链表(5):归并排序_lyrich随便写写-CSDN博客_有头结点的单链表归并排序
写给自己看的单链表(2):进阶操作_lyrich随便写写-CSDN博客
十一、待补充
总结:单链表基本操作集合
删除
(1)删除链表中值最小的节点
(2)删除链表中值最小的节点并由最后一个节点补充
(3)删除第K个位置的节点
(4)删除给定值的节点
(5)删除倒数第K个位置的节点插入
(1)在第i个位置后面插入查找
(1)统计单链表中节点值为给定值的节点个数排序
(1)插入排序
(2)单链表实现选择排序
(3)归并排序
(4)将单链表化为分两个部分,左半部分小于给定值val,右半部分大于等于给定值val其他
(1)反转链表
(2)删除相同的多余节点的算法
(3)合并两个单链表
(4)将单链表调整为堆,并在堆中插入一个元素,使其还是堆
代码:myself
#include <iostream>
#include <fstream>
#include <stdlib.h>
#include <set>using namespace std;typedef struct link
{int val;struct link *next;
}*Link, LinkNode;void create(Link &head) //带头结点, 默认头结点的位置编号为0, 尾插法
{Link newNode, rear;int val, cnt;head = new LinkNode;head->next = NULL;rear = head;cout << "你输入节点个数:";cin >> cnt;for(int i = 0; i < cnt; i ++ ){newNode = new LinkNode;cin >> newNode->val;newNode->next = rear->next;rear->next = newNode;rear = newNode;}
}void show(Link L)
{L = L->next;if(L == NULL){cout << "链表为空" << endl;return ; } cout << "链表如下:" << endl;while(L){cout << L->val << " ";L = L->next;}cout << endl;
}void InsertSort(Link &head)
{Link pre, r, cur, tmp;cur = head->next->next;head->next->next = NULL;while(cur){pre = head;r = head->next;while(r && r->val < cur->val){pre = pre->next;r = r->next;}tmp = cur;cur = cur->next;pre->next = tmp;tmp->next = r;}
}Link merge(Link L1, Link L2) //合并两个升序的单链表并使新的单链表仍然有序
{Link head, p1, p2, rear; p1 = L1->next;p2 = L2->next;head = new LinkNode;head->next = NULL;rear = head;while(p1 && p2){if(p1->val < p2->val) {//不要加上了p1->next = rear!!!这里不是插入节点!!! rear->next = p1;rear = p1;p1 = p1->next;}else{rear->next = L2;rear = L2; p2 = p2->next;}}rear->next = p1 ? p1 : p2;return head;}void deleteMinNode(Link &L, int &min_val) //直接删除最小值节点
{Link minPre, cur;int min;minPre = L;cur = L->next;if(cur == NULL){cout << "链表为空!" << endl;return ;}min = cur->val;while(cur->next){if(cur->next->val < min){min = cur->next->val;minPre = cur;}cur = cur->next;}cur = minPre->next;minPre->next = cur->next;free(cur); //删除就要释放 min_val = min;
}void swapMinNode(Link &L, int &min_val) //删除最小值节点并由最后一个节点补充
{//思路:将最小值节点替换为最后一个节点,然后删除最后一个节点 Link minPre, cur, curPre;int minx;minPre = L;curPre = L;cur = curPre->next;if(cur == NULL) {cout << "链表为空!" << endl; return ;}minx = cur->val;while(cur->next){if(cur->next->val < minx){minx = cur->next->val;minPre = cur;}curPre = cur;cur = cur->next;}minPre->next->val = cur->val; curPre->next = cur->next;free(cur);min_val = minx;
}void deleteByPos(Link &L, int pos) //删除pos位置的节点
{int j = 1;Link pre, goal; //第k个节点的前驱节点, 目标节点 pre = L;while(pre->next && j < pos){j ++ ;pre = pre->next;}goal = pre->next;if(pos < j || goal == NULL){cout << "节点不存在!" << endl;return ;}pre->next = goal->next;free(goal);
}void insertNode(Link &L, int pos) //在pos位置之前插入节点
{int j = 1, val;Link newNode, preNode;preNode = L;while(j < pos && preNode){ j ++ ;preNode = preNode->next;} if(pos < j || preNode == NULL){cout << "插入位置不正确" << endl;return ;}cout << "请输入要插入的数据: ";cin >> val; newNode = new LinkNode;newNode->val = val;newNode->next = preNode->next; preNode->next = newNode;
}void deleteNodeByNum(Link &L, int val) //删除具有给定值val的节点
{Link pre, goalNode; pre = L;if(pre->next == NULL){cout << "链表为空!" << endl;return ;}while(pre->next){if(pre->next->val == val){goalNode = pre->next;pre->next = goalNode->next;free(goalNode);}else{/*当有连续的两个val值的时候只会删除一个因为在删除一个val之后pre后移一位指向了下一个val值的节点 所以当我们删除了一个val值节点之后不要后移pre指针 */pre = pre->next;}}
}int getValNum(Link &L, int val) //查找节点值为给定值val的节点个数
{L = L->next;int cnt = 0;if(L == NULL){cout << "链表为空" << endl;return 0;}while(L){if(L->val == val) cnt ++ ;L = L->next; } return cnt;
}void SelectSort(Link &L)//单链表上的简单选择排序算法
{int tmp;Link p, q, minp;for(p = L->next; p; p = p->next) //遍历所有节点, 注意跳过头结点 {minp = p; //默认当前节点是值最小的节点 for(q = p->next; q; q = q->next) //在当前节点和后面所有节点中找到一个值最小的节点 if(q->val < minp->val)minp = q;if(minp != p) //如果当前节点不是最小值节点就交换值 {tmp = p->val;p->val = minp->val;minp->val = tmp;}}
}//归并排序 -- 就地归并
Link MergeListCore(Link head1, Link head2) //两个单链表head1和head2的归并排序
{//如果head1或者head2==NULL,直接返回另一个 if (head1 == NULL) return head2;if (head2 == NULL)return head1;//如果head1和head2均不为空,让值小的作为头, if (head1->val <= head2->val) {head1->next = MergeListCore(head1->next, head2); //head1作为头 return head1;}if (head1->val > head2->val) {head2->next = MergeListCore(head1, head2->next); //head2作为头 return head2;}
}Link MergeSortCore(Link head)
{if (head->next == NULL) //只有一个节点返回 return head;//如果区间长度不为1,递归划分左右区间 //左区间长度为len/2上取整,右区间长度为len/2下取整,即左区间长度减去右区间长度等于1/0 Link slow, fast;slow = head;fast = slow->next;while (fast != NULL) {fast = fast->next;if (fast != NULL) { slow = slow->next;fast = fast->next;}}Link righthead;righthead = slow->next;slow->next = NULL;
// cout << "text: " << head->val << " " << righthead->val << endl;//继续划分 head = MergeSortCore(head);righthead = MergeSortCore(righthead);return MergeListCore(head, righthead);
}void MergeSort(Link &head)
{if(head->next == NULL) return ;head->next = MergeSortCore(head->next);
} bool checkLift(Link &L) //判断一个单链表是否递增, 这里相等也算递增
{Link pre = L->next;if(pre == NULL){cout << "链表为空!" << endl;return false;}while(pre->next != NULL){if(pre->next->val < pre->val) return false;else pre = pre->next;}return true;
} Link partition(Link head, int x) //根据x的值把单链表分割成两个区间
{/*pre指针的作用:pre指向可以与cur的值做交换的节点如果cur的值小于x,我们需要把cur的值放到链表的前面但又希望小于x的值在排序后仍然保持原来的顺序,即保持稳定性例如,原本是1,2,我们希望排序后仍然是1,2而不是2,1 那么我们就要记录当前已经遍历到的小于x的最后一个元素的后继,就是pre那么初始时pre就要放在第一个元素的位置了 pre左侧的元素肯定时小于x的 因为只要cur的值小于x,pre就要后移一位而在初始状态下,pre和cur是指向同一元素的只有当当前元素的值大于x时,cur移动,而pre不移动也就说明[pre,cur)这个区间的值肯定时大于x的我们不会把一个小于x的值交换到右侧 cur指针的作用:找到一个小于x的值与pre交换,因为pre肯定在cur的左边所以小于x的就可以被放到左半区 */ Link pre = head->next; Link cur = head->next; //cur遍历单链表所有元素 while(cur){if(cur->val < x){int temp = pre->val;pre->val = cur->val;cur->val = temp;pre = pre->next;}cur = cur->next;}return head;
}//删除链表中的重复元素
void deleteDuplecate(Link &L)//方法一:哈希表法,时间复杂度O(n) 额外空间复杂度O(n)
{set<int> S;Link cur, pre;pre = L;cur = L->next;if(cur == NULL){cout << "链表为空" << endl;return ;}while(cur != NULL){if(S.count(cur->val)) //不需要修改pre指针,因为此时pre就指向了cur后移的位置 pre->next = cur->next;else{S.insert(cur->val);pre = cur; }cur = cur->next;}
} Link reverseList(Link &head) //反转链表
{//思路:头插入创建一个新链表 Link newHead;Link tmpNode;newHead = new LinkNode;newHead->next = NULL;head = head->next;while(head != NULL){tmpNode = head;head = head->next; tmpNode->next = newHead->next;newHead->next = tmpNode;/*head = head->next;必须放在tmpNode->next = newHead->next;的后面否则tmpNode指向newHead,head也会指向newHead 例如下面的test()! */}return newHead;
}void test(Link L)
{//list:1 2 3 4 5Link p, q;q = L->next;p = q;p->next = NULL;if(q->next == NULL) cout << "NULL";else cout << q->next->val;//输出NULL
} void deleteNthFromEnd(Link &head, int n) //删除倒数第k个节点
{// 设链表长度为len // 双指针法,让fast先走n步,然后fast和slow一起走,// 当fast走到链表尾部(NULL)处,fast一共走了len步,slow走了len-n步// 正数len-n就是倒数第n的位置 if(head->next == NULL){cout << "链表为空" << endl;return ;}Link slow = head, fast = head, pre;for(int i = 0; i < n; i ++ ) fast = fast->next;while(fast != NULL){fast = fast->next;pre = slow;slow = slow->next;}pre->next = slow->next;
}int main()
{int min;Link L1, L2;create(L1); show(L1);create(L2); show(L2);Link L3 = merge(L1, L2);show(L3);return 0;
}