一、实验目的
1.加深对递归下降分析法一种自顶向下的语法分析方法的理解。
2.根据文法的产生式规则消除左递归,提取公共左因子构造出相应的递归下降分析器。
二、实验内容
根据课堂讲授的形式化算法,编制程序实现递归下降分析器,能对常见的语句进行分析。
三、实验要求
首先对上下文无关文法进行检查,消除左递归和左公共因子,从逻辑上检测避免死循环和低效率处理。 采用每个产生式的左边的文法符号对应一个函数或过程的形式,编写程序实现一个递归下降分析器。注意这里的语法分析,是在词法分析的基础上进行的。
要求实现以下语法的递归下降分析:

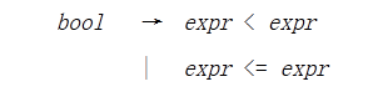


示例:
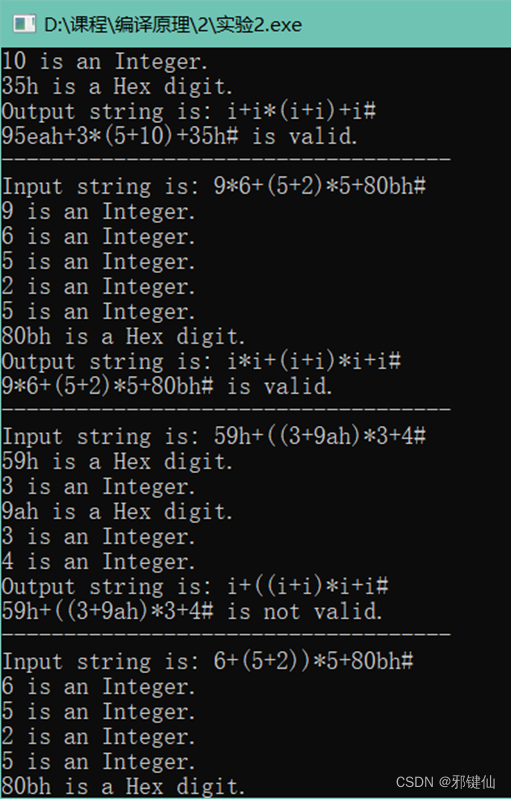
输入语句:
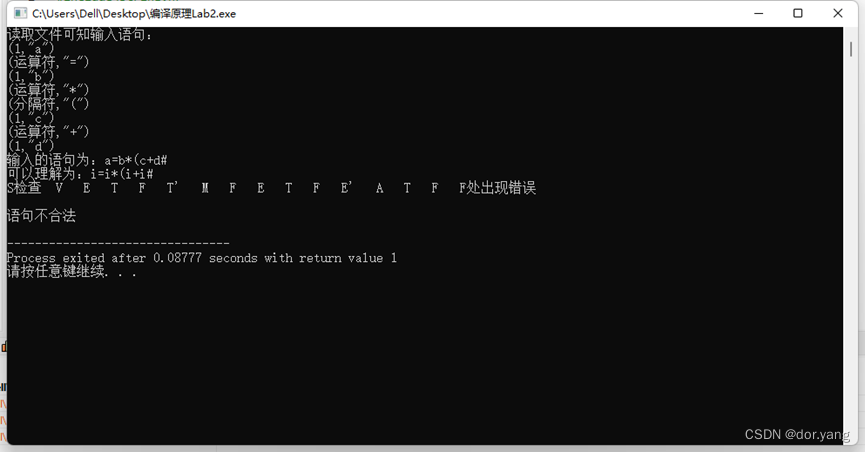
{i=2;while(i<=100){sum=sum+i;i=i+2;}
}推导过程:

四、算法分析
语法分析是编译程序的核心功能之一。语法分析的作用是识别有词法分析个哦出的单词符号串是否是给定文法的正确句子。递归下降分析属于自顶向下分析,即从文法的开始符号出发企图推到出与输入的单词符号串完全相匹配的句子。
这里的语法分析,是在词法分析的基础上进行的。输入示例内容,逐个读入单词,对其进行词法分析。采用每个产生式的左边的文法符号对应一个函数的形式,实现递归下降分析器。将最左推导的过程逐步完整输出,具体实现方式是将上一行的输出存储在一个字符串变量中,每次用产生式的右部替换字符串最左非终结符再输出。递归下降分析法是一种自顶向下的分析方法,文法的每个非终结符对应一个递归过程。分析过程就是从文法开始符出发执行一组递归过程,这样向下推导直到推出句子;或者说从根节点出发,自顶向下为输入串寻找一个最左匹配序列,建立一棵语法树。
代码:
#include<cstdio>
#include<cstring>
#include<ctype.h>
#include<iostream>
using namespace std;
char prog[1000],ch,ch1,token[1000],filename[30];
int p=0,sym=0,n,line=1;
FILE *fpin;
const char *keyword[22]={"if","else","while","do","main","int","float","for""double","return","const","void","continue","break","char","signed","enum","long","switch","case","auto","unsigned"};
char keywordtable[20][20],digittable[20][20],otherchartable[20][20],idtable[20][20],notetable[20][20],finaltable[100][20];
//存放保留字、存放数字、其他字符、标识符、注释、终结符
int finaltableint[100];
char word[20];
void otherchar();
void note();
void program();
void block();
void stmts();
void stmt();
void expr();
void expr1();
void term();
void term1();
void factor();int digit_num=0,keyword_num=0,otherchar_num=0,id_num=0,note_num=0;
int final_num=0,finalnum=0;
int flag_error=0; //0表示没有错误,1表示有错误
int flagerror=0;void initialize() //初始化数组word
{for(int i=0;i<20;i++){word[i]='\0';}
}void error()
{flag_error=1;printf("出现错误,停止分析!\n");
}void alpha()
{int i=0,flag;word[i++]=ch;ch=prog[p++];while(isalpha(ch)||isdigit(ch)) //将标识符放到word数组中 {word[i++]=ch;ch=prog[p++];} p--;flag=0;for(i=0;i<21;i++)//关键字 {if(strcmp(word,keyword[i])==0){flag=1;break;}}//只实现了部分保留字,可根据要求自行增删if(flag==1){strcpy(keywordtable[keyword_num++],word);strcpy(finaltable[final_num],word);if(strcmp(word,"if")==0)finaltableint[final_num++]=100;if(strcmp(word,"for")==0)finaltableint[final_num++]=200;if(strcmp(word,"else")==0)finaltableint[final_num++]=300;if(strcmp(word,"while")==0)finaltableint[final_num++]=400;if(strcmp(word,"do")==0)finaltableint[final_num++]=500;if(strcmp(word,"float")==0)finaltableint[final_num++]=600;if(strcmp(word,"int")==0)finaltableint[final_num++]=700;if(strcmp(word,"break")==0)finaltableint[final_num++]=800;}else{strcpy(idtable[id_num++],word); //存放标识符在word数组strcpy(finaltable[final_num],"id"); //与存放id到终结符表 finaltableint[final_num++]=1;}
}void digit()
{int i=0,flag;word[i++]=ch;ch=prog[p++];while(isdigit(ch)) //整数 {word[i++]=ch;ch=prog[p++];} p--;strcpy(digittable[digit_num++],word);strcpy(finaltable[final_num],"num");//数字数组,序号为99 finaltableint[final_num++]=99;} void note()
{int i=0;while(1){if(ch=='*'){ch=prog[p++];if(ch=='/')break;else{p--;word[i++]=ch; } }else if(ch=='\n'){break;}else{word[i++]=ch;}ch=prog[p++];}strcpy(notetable[note_num++],word);//将注释的内容放入注释表
}
void otherchar()
{switch(ch){case '!':{ch=prog[p++];if(ch=='='){strcpy(otherchartable[otherchar_num++],"!=");strcpy(finaltable[final_num],"!=");finaltableint[final_num++]=3;}else{p--;error();}}break;case '=':{ch=prog[p++];if(ch=='='){strcpy(otherchartable[otherchar_num++],"==");strcpy(finaltable[final_num],"==");finaltableint[final_num++]=4;}else{strcpy(otherchartable[otherchar_num++],"=");strcpy(finaltable[final_num],"=");finaltableint[final_num++]=5;p--;}}break;case '(':strcpy(otherchartable[otherchar_num++],"(");strcpy(finaltable[final_num],"(");finaltableint[final_num++]=6;break;case ')':strcpy(otherchartable[otherchar_num++],")");strcpy(finaltable[final_num],")");finaltableint[final_num++]=7;break;case ';':strcpy(otherchartable[otherchar_num++],";");strcpy(finaltable[final_num],";");finaltableint[final_num++]=8;break;case '{':strcpy(otherchartable[otherchar_num++],"{");strcpy(finaltable[final_num],"{");finaltableint[final_num++]=9;break;case '}':strcpy(otherchartable[otherchar_num++],"}");strcpy(finaltable[final_num],"}");finaltableint[final_num++]=10;break;case '|':{ch=prog[p++];if(ch=='|'){strcpy(otherchartable[otherchar_num++],"||");strcpy(finaltable[final_num],"||");finaltableint[final_num++]=11;}else{p--;error();}} break;case '&':{ch=prog[p++];if(ch=='&'){strcpy(otherchartable[otherchar_num++],"&&");strcpy(finaltable[final_num],"&&");finaltableint[final_num++]=12;}else{p--;error();}} break;case '+':strcpy(otherchartable[otherchar_num++],"+");strcpy(finaltable[final_num],"+");finaltableint[final_num++]=13;break;case '-':strcpy(otherchartable[otherchar_num++],"-");strcpy(finaltable[final_num],"-");finaltableint[final_num++]=19;break;case '>':{ch=prog[p++];if(ch=='='){strcpy(otherchartable[otherchar_num++],">=");strcpy(finaltable[final_num],">=");finaltableint[final_num++]=14;}else{strcpy(otherchartable[otherchar_num++],">");strcpy(finaltable[final_num],">");finaltableint[final_num++]=15;p--;}}break;case '<':{ch=prog[p++];if(ch=='='){strcpy(otherchartable[otherchar_num++],"<=");strcpy(finaltable[final_num],"<=");finaltableint[final_num++]=16;}else{strcpy(otherchartable[otherchar_num++],"<");strcpy(finaltable[final_num],"<");finaltableint[final_num++]=17;p--;}}break;case '*':strcpy(otherchartable[otherchar_num++],"*");strcpy(finaltable[final_num],"*");finaltableint[final_num++]=18;break;default:error();break;}
}void match(string str)
{char cha[20];//初始化数组cha for(int i=0;i<20;i++){cha[i]='\0';}for(int k=0;k<str.length();k++){cha[k]=str[k];}if(strcmp(finaltable[finalnum],cha)!=0){flagerror=1;return;}finalnum++;
}
void program()
{printf("program-->block\n");block();if(flagerror==1){error();return;}
}
void block()
{if(flagerror==1){return;}printf("block-->{stmts}\n");match("{");stmts();match("}");
}
void Bool()
{if(flagerror==1){return;}expr();switch(finaltableint[finalnum]){case 17:printf("bool-->expr < expr\n");match("<");expr();break;case 16:printf("bool-->expr <= expr\n");match("<=");expr();break;case 15:printf("bool-->expr > expr\n");match(">");expr();break;case 14:printf("bool-->expr >= expr\n");match(">=");expr();break;default:printf("bool-->expr\n");expr();break;}
}
void stmts()
{if(flagerror==1){return;}if(finaltableint[finalnum]==10){printf("stmts-->null\n");return;}printf("stmts-->stmt stmts\n");stmt();stmts();
}
void stmt()
{if(flagerror==1){return;}switch(finaltableint[finalnum]){case 1:printf("stmt-->id=expr;\n");match("id");match("=");expr();match(";");break;case 100:match("if");match("(");Bool();match(")");stmt();if(strcmp(finaltable[finalnum],"else")==0){printf("stmt-->if(bool) stmt else stmt\n");match("else");stmt();break;}else{printf("stmt-->if(bool) stmt\n");break; }case 400:printf("stmt-->while(bool) stmt\n");match("while");match("(");Bool();match(")");stmt();break;case 500:printf("stmt-->do stmt while(bool)\n");match("do");stmt();match("while");match("(");Bool();match(")");break;case 800:printf("stmt-->break\n");match("break");break;default:printf("stmt-->block\n");block();break;}
}void expr()
{if(flagerror==1){return;}printf("expr-->term expr1\n");term();expr1();
}
void expr1()
{if(flagerror==1){return;}switch(finaltableint[finalnum]){case 13:printf("expr1-->+term expr1\n");match("+");term();expr1();break;case 19:printf("expr1-->-term expr1\n");match("-");term();expr1();break;default:printf("expr1-->null\n");return;}
}
void term()
{if(flagerror==1){return;}printf("term-->factor term1\n");factor();term1();
}
void term1()
{if(flagerror==1){return;}switch(finaltableint[finalnum]){case 18:printf("term1-->*factor term1\n");match("*");factor();term1();break;case 2:printf("term1-->/factor term1\n");match("/");factor();term1();break;default:printf("term1-->null\n");return;}
}
void factor()
{if(flagerror==1){return;}switch(finaltableint[finalnum]){case 6:printf("factor-->(expr)\n");match("(");expr();match(")");break;case 1:printf("factor-->id\n");match("id");break;case 99:printf("factor-->num\n");match("num");break;default:flagerror=1;break;}
}//语法分析部分
void YufaBegin(){p=0;while(1){ ch=prog[p++]; if(ch=='#') break; if(isalpha(ch)||ch=='_') //isalpha测试字符是否为英文字母 //a-z或A-Z时返回非零值(不一定是1),否则返回零 {alpha(); //存入字母表initialize();}else if(isdigit(ch)) //用来判断字符lookahead是否为数字 {digit(); //存入数字表initialize();}else if(ch=='\t'||ch==' '||ch=='\n'){continue;}else if(ch=='/'){ch=prog[p++];if(ch=='*'||ch=='/'){note(); //存入注释表initialize();}else{p--; //把一个字符退回到输入流中//lookahead是写入的字符,stdin是文件流指针 strcpy(finaltable[final_num],"/"); //将"/"放到终结符号表中 strcpy(otherchartable[otherchar_num++],"/"); //将"/"放到其他符号表中 finaltableint[final_num++]=2; //"/"的序号是2 initialize();}}else{otherchar(); //其他字符存入otherchar表initialize();}}if(flag_error==0){finaltableint[final_num]='\0';printf("--------------------");printf("\n语法分析过程如下:\n");program(); //从开始符号program()向下推导if(finalnum==final_num)printf("语法分析完成!"); }
}void GetToken()
{sym=0;//先把token[]数组清空 for (n=0;n<1000;n++){token[n]='\0';}n=0;ch=prog[p++];ch1=prog[p];//跳过空格,回车,tab的识别 while(ch==' '||ch=='\t'){ch=prog[p++];}if(ch=='\n'){line++;return;}if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')||(ch=='_')) {//标识符 状态1sym=1;do{token[n++]=ch;ch=prog[p++];}while ((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')||(ch>='0'&&ch<='9'));//比较标识符与keyword的关键字是否相同,若相同转为状态2for(n=0;n<2;n++){if(strcmp(token,keyword[n])==0){sym=2;break; }}p--;return;}else if (ch>='0'&&ch<='9') { //识别到数字,置状态为3sym=3;do{ token[n++]=ch;ch=prog[p++];if(ch=='.'){sym=31;token[n++]=ch;ch=prog[p++];}if(ch=='S'){sym=32;ch=prog[p++];} if(ch=='L'){sym=33;ch=prog[p++];}if(ch=='O'){sym=34;ch=prog[p++];} if(ch=='H'){sym=35;ch=prog[p++];} }while(ch>='0'&&ch<='9'); p--;return;}//跳过注释的内容 else if(ch=='/' && ch1=='*'){ p++;do{ch=prog[p++];ch1=prog[p++];if(ch=='\n'){line++;}}while(ch!='*'||ch1!='/');return;}else if(ch=='/'&& ch1=='/'){p++;do{ch=prog[p++];}while(ch!='\n');line++;return;}else if(ch=='='&& ch1=='='){p++;sym=4;token[0]='=';token[1]='=';return;}else if(ch=='<'&& ch1=='='){p++;sym=4;token[0]='<';token[1]='=';return;}else if(ch=='>'&& ch1=='='){p++;sym=4;token[0]='>';token[1]='=';return;}else if(ch=='!'&& ch1=='='){p++;sym=4;token[0]='!';token[1]='=';return;} else if(ch=='&'&& ch1=='&'){p++;sym=4;token[0]='&';token[1]='&';return;} else if(ch=='|'&& ch1=='|'){p++;sym=4;token[0]='|';token[1]='|';return;}else {switch(ch)//识别关键符号 { case '=':case '<':case '>':case '/':case '+':case '-':case '*':case '{':case '}':case ';':case '(':case ')':case ',':case '\'':case '\"':sym=4;token[0]=ch;break;default:sym=-1;break;}}return;}//词法分析器部分
void CifaBegin()
{p=0;do {GetToken();//启动字符识别函数 switch(sym)//打印字符状态 {case 1:cout<<"("<<line<<" "<<token<<" "<<"标识符"<<")"<<endl;break;case 2:cout<<"("<<line<<" "<<token<<" "<<"保留字"<<")"<<endl;break;case 3:cout<<"("<<line<<" "<<token<<" "<<"整型"<<")"<<endl;break;case 31:cout<<"("<<line<<" "<<token<<" "<<"浮点型"<<")"<<endl;break;case 32:cout<<"("<<line<<" "<<token<<"S"<<" "<<"短类型"<<")"<<endl;break;case 33:cout<<"("<<line<<" "<<token<<"L"<<" "<<"长类型"<<")"<<endl;break;case 34:cout<<"("<<line<<" "<<token<<"O"<<" "<<"八进制数"<<")"<<endl;break;case 35:cout<<"("<<line<<" "<<token<<"H"<<" "<<"十六进制数"<<")"<<endl;break;case 4:cout<<"("<<line<<" "<<token<<" "<<"特殊符号"<<")"<<endl;break;case -1:cout<<"("<<line<<" "<<"错误!"<<")"<<endl;break;default:break;}}while(ch!='#');p=0;
}int main()
{cout<<"请输入要分析的语句:";//将文件内容存储到prog中 do{ch=getchar();prog[p++]=ch;}while(ch!='#');//调用词法分析部分 printf("-----------------\n");printf("词法分析结果如下:\n");ch=getchar( );CifaBegin();//调用语法分析部分 initialize();YufaBegin();return 0;
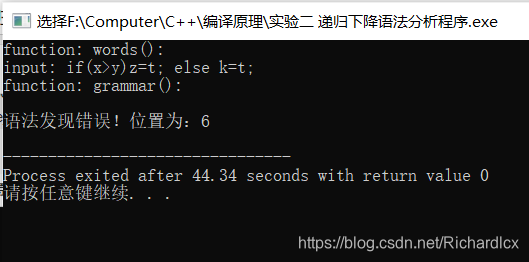
} 运行结果: