目录
一、实验目的和要求
二、实验内容
三、实验环境
四、实验步骤
1、语法分析所依据的文法;
2、给出消除左递归及提取左公因子的文法;
五、测试要求
六、实验步骤
1、语法分析所依据的文法
2、给出消除左递归及提取左公因子的文法;
3、关键代码
七、实验结果与分析
一、实验目的和要求
- 理解自顶向下语法分析方法;
- 用递归下降技术实现语法分析器;
二、实验内容
算术表达式的文法是G[E]:
E→E+T| E-T| T
T→T*F| T/F| F
F→(E)| i
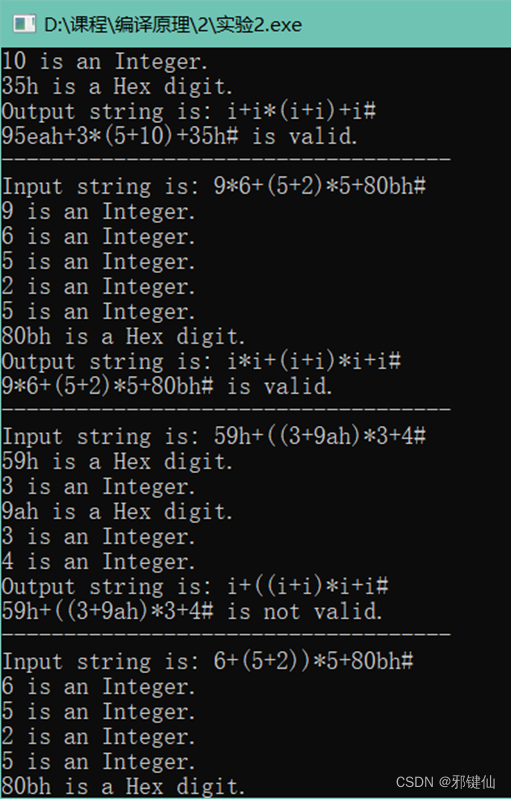
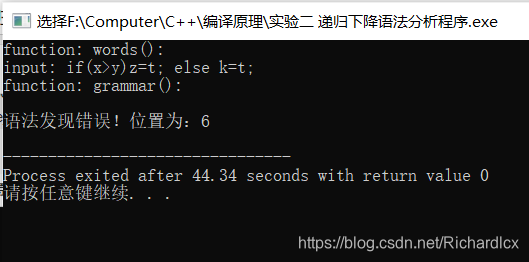
用递归下降分析法按文法G[E]对算术表达式(包括+、-、*、/、()的算术表达式)进行语法分析,判断该表达式是否正确。
三、实验环境
处理器 AMD Ryzen 7 5800H with Radeon Graphics3.20 GHz
机带RAM 16.0 GB(13.9 GB可用)
Win10家庭版20H2 X64
PyCharm 2012.2
Python 3.10
四、实验步骤
1、准备:阅读课本有关章节,将上述算术表达式的文法改造成LL(1)文法(即消除左递归和提取左公因子);
2、参考课件P52编写递归下降分析程序。
1、语法分析所依据的文法;
算术表达式的文法是G[E]:
E→E+T| E-T| T
T→T*F| T/F| F
F→(E)| i
2、给出消除左递归及提取左公因子的文法;
将文法G[E]改造为LL(1)文法如下:
G’[E]:
E → TE’
E’ → +TE’| -TE’|ε
T → FT’
T’→ *FT’|/FT’|ε
F → (E)| i
五、测试要求
1、为降低难度,表达式中不含变量,只含单个无符号整数或i;
2、如果遇到错误的表达式,应输出错误提示信息(该信息越详细越好);
3、测试用的表达式建议事先放在文本文件中,一行存放一个表达式,以分号结束。而语法分析程序的输出结果写在另一个文本文件中;
4、程序输入/输出示例:
输入如下表达式(以分号为结束)和输出结果:
(a)i; 或 1;
输出:正确
(b)i+i; 或 1+2;
输出:正确
(c)(i+i)*i+i-(i+i*i); 或 (1+2)*3+4-(5+6*7);
输出:正确
(d)((i+i)*i+i; 或 ((1+2)*3+4;
输出:错误,缺少右括号
(e)i+i+i+(*i/i); 或 1+2+3+(*4/5)
输出:错误
5、选作:对学有余力的同学,可增加功能:当判断一个表达式正确时,输出计算结果。
六、实验步骤
1、语法分析所依据的文法
算术表达式的文法是G[E]:
E→E+T| E-T| T
T→T*F| T/F| F
F→(E)| i
2、给出消除左递归及提取左公因子的文法;
将文法G[E]改造为LL(1)文法如下:
G’[E]:
E → TE’
E’ → +TE’| -TE’|ε
T → FT’
T’→ *FT’|/FT’|ε
F → (E)| i
3、关键代码
<!--BianYiYuanLiShiYan/yufafenxi_rtda.py-->
'''
在实验一的基础上进行语法分析
递归下降分析法
E→TE'
E'→+TE'| -TE' |ε
T→FT'
T'→*FT'| /FT' |ε
F→(E) | id |num保留关键字及种别编码
Static_word = {"begin": 1, "end": 2, "if": 3, "then": 4, "while": 5,"do": 6, "const": 7, "var": 8, "call": 9, "procedure": 10}算符和界符及种别编码
Punctuation_marks = {"+": 11, "-": 12, "*": 13, "/": 14, "odd": 15, "=": 16, "<>": 17, "<": 18, ">": 19,"<=": 20, ">=": 21, ":=": 22, "(": 23, ")": 24, ".": 25, ",": 26, ";": 27}常数的种别编码为28,标识符的种别编码为29,非法字符的种别编码为30
'''
# 导入词法分析的程序
from cifafenxi_rtda import *# 由于实验二的特殊性,单独把i(id)当做保留字处理
Static_word["i"] = 0# i + - * 、 ( ) num的种别编码
Lab2_word = [0, 11, 12, 13, 14, 23, 24, 28]# 出错标志
Err = 0# 位置标志
Index = 0# 算术表达式是否符合文法
Correct = "***************正确!"
Error = "*************错误!"# 语法分析结果写入文件
def WriteFile(string):fW = open(pathW, 'a')fW.write(string + "\n")fW.close()# 开始正式语法分析前首先判断该算术表达式中的各个字符以及首尾字符是否符合要求
def First():index = 0if (Result_Lex[0][0] in [0, 23, 28]) and (Result_Lex[0][-1] in [0, 24, 28]):for i in Result_Lex[:-2]:if i not in Lab2_word:index += 1breakelse:continueelse:index += 1return index# E→TE'
def E():global Errif Err == 0:T()E1()# E'→+TE'| -TE' |ε
def E1():global Err, Indexif Err == 0 and Index != len(Result_Lex[0]):if Result_Lex[0][Index] in [11, 12]:Index += 1if Index != len(Result_Lex[0]) - 1:T()E1()else:Index = len(Result_Lex[0])elif Result_Lex[0][Index] != 24:Err = 1# T→FT'
def T():global Errif Err == 0:F()T1()# T'→*FT'| /FT' |ε
def T1():global Err, Indexif Err == 0 and Index != len(Result_Lex[0]):if Result_Lex[0][Index] in [13, 14]:Index += 1if Index != len(Result_Lex[0]) - 1:F()T1()else:Index = len(Result_Lex[0])elif Result_Lex[0][Index] not in [11, 12, 24]:Err = 1# F→(E) | id |num
def F():global Err, Indexif Err == 0:if Result_Lex[0][Index] in [0, 28]:Index += 1elif Result_Lex[0][Index] == 23:Index += 1E()if Result_Lex[0][Index] != 24:Err = 1Index += 1else:Err = 1# 分析主程序
def Analysis_Gs():global Err, Indexif First() == 0:F()while Index < len(Result_Lex[0]):if Result_Lex[0][Index] in [11, 12]:E1()elif Result_Lex[0][Index] in [13, 14]:T1()else:Index = len(Result_Lex[0])Err = 1if Err == 0:print("语法分析结果:" + Correct)else:print("语法分析结果:" + Error)else:print("语法分析结果:" + Error)if __name__ == '__main__':# 首先运行词法分析程序Lex_main()# 运行语法分析程序Analysis_Gs()
<!--BianYiYuanLiShiYan/cifafenxi_rtda.py-->
"""
PL/0程序大纲:
1、PL/0语言的单词结构
关键字(10个):begin, end ,if ,then, while, do, const, var,call,procedure
标识符:字母序列,最大长度10
常数:整型常数
算符和界符(17个):+, -, *,/,odd,=,<>,<,>,<=,>=,:=,(,) ,, ,.,;
2、单词的种别划分标识符 作为一种常数 作为一种算符和界符每个单词作为一个单独种别
3、PL/0的语言的词法分析器将要完成以下工作:
(1)跳过分隔符(如空格,回车,制表符);
(2)识别诸如begin,end,if,while等保留字;
(3)识别非保留字的一般标识符。
(4)识别数字序列。
(5)识别:=,<=,>=之类的特殊符号。
"""# 输入文件路径
pathR = ""# 输出文件路径
pathW = ""# 保存所有字符
strAll = []# 保存词法分析后的字符及种别编码
Result_Lex = [[], []]# 保留关键字及种别编码
Static_word = {"begin": 1, "end": 2, "if": 3, "then": 4, "while": 5,"do": 6, "const": 7, "var": 8, "call": 9, "procedure": 10}# 算符和界符及种别编码
Punctuation_marks = {"+": 11, "-": 12, "*": 13, "/": 14, "odd": 15, "=": 16, "<>": 17, "<": 18, ">": 19,"<=": 20, ">=": 21, ":=": 22, "(": 23, ")": 24, ".": 25, ",": 26, ";": 27}# 常数的种别编码为28,标识符的种别编码为29,非法字符的种别编码为30# 空格或换行
Blank = {" ", "\n"}# 中文说明
Explanation = ["保留字", "加号", "减号", "乘号", "除号", "odd运算符", "等于号", "不等于号", "小于号","大于号", "小于等于号", "大于等于", "赋值符号", "左括号", "右括号", "点号", "逗号", "分号", "常数", "标识符"]# 判断字符数否为保留关键字
def Is_static(string):if string in Static_word:return Trueelse:return False# 判断字符是否为算符或者界符
def Is_marks(string):if string in Punctuation_marks:return Trueelse:return False# 判断是不是空格或者换行
def Is_blank(string):if string in Blank:return Trueelse:return False# 读取文件所有字符并保存在一个列表中
def Scanner():fR = open(pathR) # 返回一个文件对象lines = fR.readlines() # 调用文件的 readline()方法for line in lines:for i in line:strAll.append(i)fR.close()# strAll.pop()# 多次重复的操作语句
def Option(num, temp, explanation):fW = open(pathW, 'a')txt = '%-20s%s' % ("(" + str(num) + "," + temp + ")", explanation + ":" + temp)# txt = "({0},{1})\t{2}:{3}".format(num, temp, explanation, temp)print(txt)fW.write(txt + "\n")fW.close()Result_Lex[0].append(int(num))Result_Lex[1].append(temp)# 结束
def End(id):if id >= len(strAll):return True# 词法分析主方法
def Analysis_Lex():"""共分为四大块,分别是标识符、常数、算符或界符、空格或换行、非法字符,对应下面的 if, elif, elif, elif和 else"""# 索引值id = 0# 忽略代码段开头的空格或换行while Is_blank(strAll[id]):id += 1# 从第一个有意义的字符开始循环识别直至最后一个字符while id < len(strAll):# 保存临时结果temporary = ""# 判断是否为保留字或者标识符if ('a' <= strAll[id] <= 'z') or ('A' <= strAll[id] <= 'Z'):while ('0' <= strAll[id] <= '9') or ('a' <= strAll[id] <= 'z') or ('A' <= strAll[id] <= 'Z'):temporary += strAll[id]id += 1if End(id): break# 判断是否未保留字if Is_static(temporary):num = Static_word[temporary]Option(num, temporary, Explanation[0])# 判断是否为特殊运算符oddelif temporary == "odd":num = Punctuation_marks[temporary]Option(num, temporary, Explanation[num - 10])# 否则为非保留字标识符else:Option("29", temporary, Explanation[-1])# 判断是否为常数(正数或小数)elif '0' <= strAll[id] <= '9':while ('0' <= strAll[id] <= '9') or strAll[id] == ".":if strAll[id] != ".":temporary += strAll[id]id += 1if End(id): breakelif strAll[id] == "." and ('0' <= strAll[id + 1] <= '9'):temporary += strAll[id]id += 1if End(id): breakelse:breakOption("28", temporary, Explanation[-2])# 判断是否为运算符或界符elif Is_marks(strAll[id]) or strAll[id] == ":":temporary += strAll[id]# 判断小于号三种情况:小于、小于等于、不等于if strAll[id] == "<":if strAll[id + 1] == ">" or strAll[id + 1] == "=":temporary += strAll[id + 1]id += 2num = Punctuation_marks[temporary]Option(num, temporary, Explanation[num - 10])else:id += 1num = Punctuation_marks[temporary]Option(num, temporary, Explanation[num - 10])# 判断大于号两种情况:大于、大于等于elif strAll[id] == ">":if strAll[id + 1] == "=":temporary += strAll[id + 1]id += 2num = Punctuation_marks[temporary]Option(num, temporary, Explanation[num - 10])else:id += 1num = Punctuation_marks[temporary]Option(num, temporary, Explanation[num - 10])# 判断赋值符号特殊情况elif strAll[id] == ":":if strAll[id + 1] == "=":temporary += strAll[id + 1]id += 2num = Punctuation_marks[temporary]Option(num, temporary, Explanation[num - 10])# 单独的冒号不是运算符或界符,当非法字符处理else:id += 1Option("30", temporary, "非法字符")# 其他运算法或界符else:id += 1num = Punctuation_marks[temporary]Option(num, temporary, Explanation[num - 10])# 对空格、换行过滤elif Is_blank(strAll[id]):id += 1continue# 对非法字符的处理else:temporary += strAll[id]id += 1Option("30", temporary, "非法字符")def Lex_main():# 获取代码文件print("请输入要分析的代码文件(.txt)路径及完整名称:", end='')global pathR, pathWpathR = input()# 读入代码文件Scanner()# 读入保存结果文件print("请输入保存结果的文件(.txt)路径及完整名称:", end='')pathW = input()# 开始分析代码文件及结果写入# print(strAll)print('%-16s%s' % ("(种别编码,字符)", "中文介绍:字符"))print("-------------词法分析结果为-------------\n")# 打开需要写入结果的文档(不存在则创建)并开始写入!f = open(pathW, 'a')f.write('%-16s%s' % ("(种别编码,字符)", "中文介绍:字符\n"))f.write("-------------词法分析结果为-------------\n")f.close()# 程序实现主方法Analysis_Lex()# 程序运行点
if __name__ == '__main__':Lex_main()
七、实验结果与分析