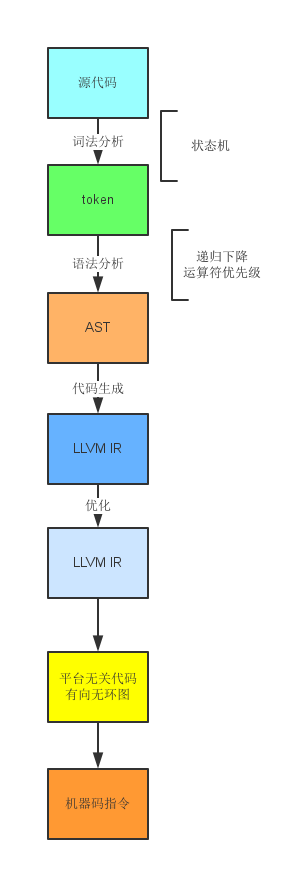
爬虫
首先我们在网站中打开我们要爬的网站
“http://maoyan.com/board/4”
这就是豆瓣高分电影前100的榜单.

然后我们点击f12,再刷新一次,就可以看到网页的基本信息了。
这时候我们来看一下第一部‘我不是药神中的代码信息。’

一个dd节点为一个电影的全部信息。
我们用正则表达式的方法去分析上面的代码,首先是class为board-index的排名信息。
我们用正则表达式应该是这么去写
<dd>.*?board-index.*?>(.*?)</i>
那我们接着分析第二部分的图片,我们看图片的节点一共有两点:两个img节点。
我们发现第二个img节点属性为data-src为图片链接,所以我们就分析这部分。
我们用正则表达式应该是这么去写
.*?data.src="(.*?)"
以此类推我们接着分析剩下所有的信息。
第三部分为电影名,电影名在p节点的class=name下面。
我们用正则表达式应该这么写
.*?name".*?a.*?>(.*?)</a>
那么接下来我们就写一个完整的信息:分别记录了排名,照片,名字,演员,时间,评分。
<dd>.*?board-index.*?>(.*?)</i>.*?data-src="(.*?)".*?name.*?a.*?>(.*?)</a>.*?star".*?>(.*?)</p>.*?releasetime.*?>(.*?)</p>.*?integer.*?>(.*?)</i>.*?fraction.*?>(.*?)</i>.*?</dd>
那我们就可以正式一步一步去做一份爬取任务了:
1.导入库:
import json
import requests
from requests.exceptions import RequestException
import re
import time #time库是用来延时访问,某些网站设置了反爬,不能快速连续访问该网站
2.抓取首页:
def get_one_page(url):try:headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'}response = requests.get(url, headers=headers)if response.status_code == 200:return response.textreturn Noneexcept RequestException:return None
3.正则提取:
def parse_one_page(html):pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)items = re.findall(pattern, html)for item in items:yield {'index': item[0],'image': item[1],'title': item[2],'actor': item[3].strip()[3:],'time': item[4].strip()[5:],'score': item[5] + item[6]}
4.写入文件:
def write_to_file(content):with open('result.txt', 'a', encoding='utf-8') as f:f.write(json.dumps(content, ensure_ascii=False) + '\n')
5.分页爬取:

我们可以看到,一页有10个电影。那我们爬取TOP100,则需要看10页的电影内容。

当我们切到下一页的时候,我们发现网站名称后多了offset=10.第三页的时候则是offest=20.
那我们就明白了,我们可以根据offest来对TOP100进行分页爬虫。
def main(offset):url = 'http://maoyan.com/board/4?offset=' + str(offset)html = get_one_page(url)for item in parse_one_page(html):print(item)write_to_file(item)
if __name__ == '__main__':for i in range(10):main(offset=i * 10)time.sleep(1) #猫眼多了反爬虫,所以我们要延时等待。完整代码:
import json
import requests
from requests.exceptions import RequestException
import re
import timedef get_one_page(url):try:headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36'}response = requests.get(url, headers=headers)if response.status_code == 200:return response.textreturn Noneexcept RequestException:return Nonedef parse_one_page(html):pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a'+ '.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>'+ '.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)items = re.findall(pattern, html)for item in items:yield {'index': item[0],'image': item[1],'title': item[2],'actor': item[3].strip()[3:],'time': item[4].strip()[5:],'score': item[5] + item[6]}def write_to_file(content):with open('result.txt', 'a', encoding='utf-8') as f:f.write(json.dumps(content, ensure_ascii=False) + '\n')def main(offset):url = 'http://maoyan.com/board/4?offset=' + str(offset)html = get_one_page(url)for item in parse_one_page(html):print(item)write_to_file(item)if __name__ == '__main__':for i in range(10):main(offset=i * 10)time.sleep(1)如果爬取过程中发现只爬取到了前10或者前20的内容就停止了。
那我们回到TOP100的网页,发现了他让我们进行图片的验证(反爬虫)
由于我们现在还没学到解决这类问题的方法。
所以我们自己进入网页验证完之后,再运行一次就能成功了。