基于LLVM的编译原理简明教程 (1) - 写编译器越来越容易了
进入21世纪,新的编程语言如雨后春笋一样不停地冒出来。需求当然是重要的驱动力量,但是在其中起了重要作用的就是工具链的改善。
2000年,UIUC的Chris Lattner主持开发了一套称为LLVM(Low Level Virtual Machine)的编译器工具库套件。后来,LLVM的scope越来越大,Low Level Virtual Machine已经不足以表示LLVM的全部,于是,LLVM就变成了正式的名字。LLVM可以用于常规编译器,JIT编译器,汇编器,调试器,静态分析工具等一系列跟编程语言相关的工作。
后来,Chris Lattner又主持开发了Clang,针对C/C++/Objective-C的前端。这个编译器直接挑战了GCC的统治地位。成为Apple系统的主要编译器,在Android中,指名使用Clang的模块也越来越多。
2012年,LLVM荣获美国计算机学会ACM的软件系统大奖,跟UNIX,WWW,TCP/IP,TeX,Java等经典系统作伴。
ACM系统奖完全名单
另外再八卦几句LLVM的主要作者和架构师Chris Lattner。这哥们生于1978年。
2005年,Chris Lattner加入Apple。因为Apple对于GCC支持Objective-C不力的不满,LLVM和Clang成为Apple替代GCC的杀手级武器。
2010年,Chris Lattner又开始主持开发Swift语言。
好了,言归正传。首先我们想说明的是,跟学院派的厚书给大家的印象不同,其实用LLVM写个简单的编译器是件容易的事情,因为大部分事情LLVM都替我们做了。
用LLVM做个简单的编译器很容易
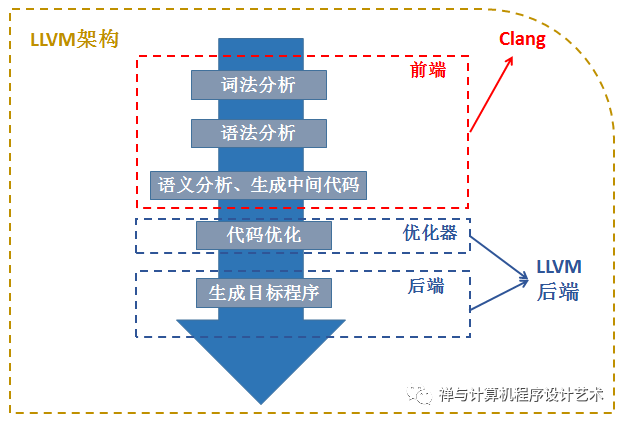
我们先看一个使用LLVM工具之后,实现一门编程语言的简图:
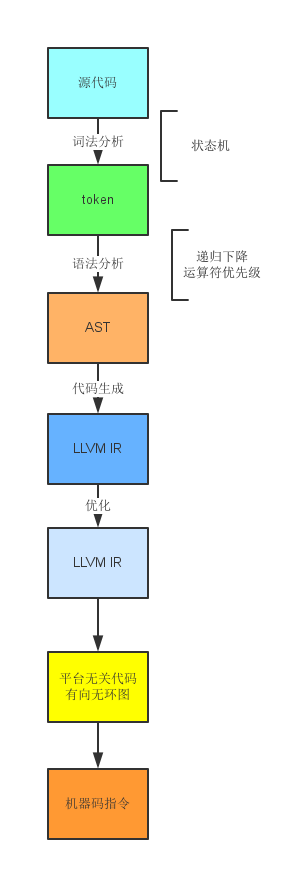
完全需要我们手工,或者依靠其他工具如lex, yacc来做的事情,是从源代码到token的词法分析和从token到AST的语法分析。也就是前端的主要部分需要我们来实现,毕竟我们是这门语言的定义者。在介绍LLVM的书里,讲前端的部分都是只占很小的篇幅的,所以大家可以take it easy.
在LLVM的万花筒语言例子里,带有注释的词法分析和语法分析也不过400行。大家如果觉得还复杂,后面我会带大家做一些更简单的,先完成一小部分功能,然后迭代式开发。区区百余行代码,不需要学习编译原理。
比如Clang就是一个实现了C/C++/Objective-C的前端。
从AST转LLVM开始,LLVM就开始提供一系列的工具帮助我们快速开发。从IR(中间指令代码)到DAG(有向无环图)再到机器指令,针对常用的平台,LLVM有完善的后端。也就是说,我们只要完成了到IR这一步,后面的工作我们就享有和Clang一样的先进生产力了。
口说无凭,有例子为证,这是将二元表达式AST转成IR的函数:
Value *BinaryExprAST::codegen() {
...switch (Op) {case '+':return Builder.CreateFAdd(L, R, "addtmp");case '-':return Builder.CreateFSub(L, R, "subtmp");case '*':return Builder.CreateFMul(L, R, "multmp");case '<':L = Builder.CreateFCmpULT(L, R, "cmptmp");// Convert bool 0/1 to double 0.0 or 1.0return Builder.CreateUIToFP(L, Type::getDoubleTy(TheContext), "booltmp");default:
...}
}如何生成加减乘除的IR,在这个阶段完全不用关心,LLVM会帮我们生成相应的代码。
下面我们再看一个声明函数原型的:
Function *PrototypeAST::codegen() {// Make the function type: double(double,double) etc.std::vector<Type *> Doubles(Args.size(), Type::getDoubleTy(TheContext));FunctionType *FT =FunctionType::get(Type::getDoubleTy(TheContext), Doubles, false);Function *F =Function::Create(FT, Function::ExternalLinkage, Name, TheModule.get());// Set names for all arguments.unsigned Idx = 0;for (auto &Arg : F->args())Arg.setName(Args[Idx++]);return F;
}词法分析
在正则表达式已经成为基本技能的今天,词法分析完全无门槛啊。正常情况下,我们只要写一组正则表达式,或者写个简单的状态机就可以了。
词法分析的输出是将源代码解析成一个个的token。这些token就是有类型和值的一些小单元,比如是关键字,还是数字,还是标识符等等。这个阶段不用管它们是如何组合的,都是干嘛的。
比如一个token类型是数值,值是3. 这个信息就已经足够了,至于这个3干嘛用,后面整理AST的时候再放到合适的位置上去。
至于什么时上下文无关语言,什么是确定有穷自动机,非确定有穷自动机等等这些,暂时都不需要了解。
语法分析
语法分析诚然是比词法分析要复杂一些。但是幸运的是,对于绝大多数语句和表达式来讲,并不需要高深的知识,“移进-归约”是个好方法,但是在我们学习的相当长的一段时期内都用不上。
语法分析的输出是抽象语法树AST,既然是棵树,自然构造时需要递归。所以在大部分的语句中,我们只按递归下降的方法就足够了。
对于表达式,递归下降还不够用,至少运算符还有优先级啊。所以针对表达式,我们还需要运算符优先分析法。SLR,LALR和LR暂时还用不上。
语法制导翻译和中间代码生成
从前面的简单例子中我们已经看到了,这部分大部分调用LLVM为我们提供的IR构造工具就可以了。入门阶段我们能想到的,如代码块,函数调用,控制结构等,LLVM都为我们准备好了。
优化
LLVM主我们提供了大量的优化Pass供我们选择和组合。在IR阶段和机器码阶段,我们都将花大量的篇幅来讨论优化。这可能也是我们真正感兴趣的部分。
词法分析很简单
我们看一个官方的例子,首先定义token的类型,有一种算一种吧。将来扩展都是体力活。
enum Token {tok_eof = -1,
...// primarytok_identifier = -4,tok_number = -5
};然后就是解析正则表达式,一点技术含量也没有,哈哈~
我对官方的版本做了一点删节,看起来可以更清楚一些:
static std::string IdentifierStr; // Filled in if tok_identifier
static double NumVal; // Filled in if tok_number/// gettok - Return the next token from standard input.
static int gettok() {static int LastChar = ' ';// Skip any whitespace.while (isspace(LastChar))LastChar = getchar();if (isalpha(LastChar)) { // identifier: [a-zA-Z][a-zA-Z0-9]*IdentifierStr = LastChar;while (isalnum((LastChar = getchar())))IdentifierStr += LastChar;
...return tok_identifier;}if (isdigit(LastChar) || LastChar == '.') { // Number: [0-9.]+std::string NumStr;do {NumStr += LastChar;LastChar = getchar();} while (isdigit(LastChar) || LastChar == '.');NumVal = strtod(NumStr.c_str(), nullptr);return tok_number;}...// Check for end of file. Don't eat the EOF.if (LastChar == EOF)return tok_eof;
...
}如果不想手写的话,lex, flex之类的工具很多,就是根据正则表达式来决定token类型,根据类型存一下对应的值。
如果token的类型多,就是搭积木,写正则。都是体力活~
够用的语法分析其实也很简单
上面介绍了,我们自顶向下,构造抽象语法树。
先定义个根类型吧:
/// ExprAST - Base class for all expression nodes.
class ExprAST {
public:virtual ~ExprAST() {}virtual Value *codegen() = 0;
};我们先来个简单的,就表示一个数字。这个好办,就一个节点,存个数值。
/// NumberExprAST - Expression class for numeric literals like "1.0".
class NumberExprAST : public ExprAST {double Val;public:NumberExprAST(double Val) : Val(Val) {}Value *codegen() override;
};再来一个例子,变量,就是一个变量名么。赋值是下一步的事情了。
/// VariableExprAST - Expression class for referencing a variable, like "a".
class VariableExprAST : public ExprAST {std::string Name;public:VariableExprAST(const std::string &Name) : Name(Name) {}Value *codegen() override;
};函数原型:
/// PrototypeAST - This class represents the "prototype" for a function,
/// which captures its name, and its argument names (thus implicitly the number
/// of arguments the function takes).
class PrototypeAST {std::string Name;std::vector<std::string> Args;public:PrototypeAST(const std::string &Name, std::vector<std::string> Args): Name(Name), Args(std::move(Args)) {}Function *codegen();const std::string &getName() const { return Name; }
};然后我们再看看如何通过token去构造一个数值的AST:
词法分析时,已经把这个数值暂存了,我们把它拿来用就是了。
/// numberexpr ::= number
static std::unique_ptr<ExprAST> ParseNumberExpr() {auto Result = llvm::make_unique<NumberExprAST>(NumVal);getNextToken(); // consume the numberreturn std::move(Result);
}再看看函数声明的:
/// prototype
/// ::= id '(' id* ')'
static std::unique_ptr<PrototypeAST> ParsePrototype() {if (CurTok != tok_identifier)return LogErrorP("Expected function name in prototype");std::string FnName = IdentifierStr;getNextToken();if (CurTok != '(')return LogErrorP("Expected '(' in prototype");std::vector<std::string> ArgNames;while (getNextToken() == tok_identifier)ArgNames.push_back(IdentifierStr);if (CurTok != ')')return LogErrorP("Expected ')' in prototype");// success.getNextToken(); // eat ')'.return llvm::make_unique<PrototypeAST>(FnName, std::move(ArgNames));
}先读函数名,再找左括号,然后是参数列表,最后是处理右括号。什么嘛,一点技术含量也没有。。。
上面例子这些,都是没有嵌套的,也不需要递归下降和算符优先。这些是处理比如二元表达式的时候才会遇到的。我们可以先学习容易的,先能把这些容易的组件组成一门虽然语言功能不全,但是真正实现了从源码到机器指令的编译器。
上面的例子都来自官方的例子万花筒(Keleidoscope)语言的片段。官方教程当然写得已经足够好,但是还是稍嫌复杂了点,能生成一个可玩的编译器的速度还是有点慢。我打算把学习曲线再降低一下,通过不断地迭代,一点一点搭起可玩的编译器,然后慢慢扩充功能。
Hello,LLVM
LLVM的下载
- 先下载LLVM
svn co http://llvm.org/svn/llvm-project/llvm/trunk llvm- 在LLVM的tools目录下,下载Clang(可选,但是建议):
cd llvm/tools
svn co http://llvm.org/svn/llvm-project/cfe/trunk clang- 在LLVM的projects目录下,可选下载compiler-rt,Libomp,libcxx,libcxxabi。反正我都下载了
svn co http://llvm.org/svn/llvm-project/compiler-rt/trunk compiler-rt
svn co http://llvm.org/svn/llvm-project/openmp/trunk openmp
svn co http://llvm.org/svn/llvm-project/libcxx/trunk libcxx
svn co http://llvm.org/svn/llvm-project/libcxxabi/trunk libcxxabiLLVM的编译
既然官方说大部分LLVM的开发者都使用Ninja,我们也就follow他们吧。
我在Mac下,所以使用Homebrew来安装CMake和Ninja。Linux与些类似,GCC版本太旧之类的请自助。Windows我还没试过,后面更新一下吧。
- 在LLVM目录下创建build目录
- cd build
- cmake -G Ninja
- Ninja
写个LLVM上的Hello,World程序吧
从AST转IR开始,我们都要用到LLVM的工具啦。先写个小程序学习一下LLVM的程序是如何编译的吧:
#include "llvm/IR/Module.h"
#include "llvm/IR/IRBuilder.h"
#include "llvm/IR/LLVMContext.h"
#include <cstdlib>
#include <map>
#include <memory>
#include <string>
#include <vector>static llvm::LLVMContext TheContext;
static llvm::IRBuilder<> Builder(TheContext);
static std::unique_ptr<llvm::Module> TheModule;
static std::map<std::string, llvm::Value *> NameValues;int main(){TheModule = llvm::make_unique<llvm::Module>("hello,llvm",TheContext);TheModule -> dump();return 0;
}输出结果如下:
; ModuleID = 'hello,llvm'
source_filename = "hello,llvm"如何链接LLVM的库
使用LLVM库的话,需要一大堆参数.
下面是在我的电脑上的参数:
-I/Users/ziyingliuziying/lusing/llvm/llvm/include -I/Users/ziyingliuziying/lusing/llvm/llvm/build/include -fPIC -fvisibility-inlines-hidden -Wall -W -Wno-unused-parameter -Wwrite-strings -Wcast-qual -Wmissing-field-initializers -pedantic -Wno-long-long -Wcovered-switch-default -Wnon-virtual-dtor -Wdelete-non-virtual-dtor -Werror=date-time -std=c++11 -fcolor-diagnostics -fno-exceptions -fno-rtti -D__STDC_CONSTANT_MACROS -D__STDC_FORMAT_MACROS -D__STDC_LIMIT_MACROS
-L/Users/ziyingliuziying/lusing/llvm/llvm/build/lib -Wl,-search_paths_first -Wl,-headerpad_max_install_names
-lLLVMCore -lLLVMSupport
-lcurses -lz -lm每次都这么写吓死人了啊。于是LLVM为我们提供了llvm-config工具。刚才我那一大串,是用下面的命令行生成的:
llvm-config --cxxflags --ldflags --system-libs --libs core完整的编译命令可以这么写:
clang++ -g toy.cpp `llvm-config --cxxflags --ldflags --system-libs --libs core` -o toy