同事的一个问题:
MySQL的ibdata1文件越来越大,这是为啥、
看着别扭,怎么搞小它?
ibdata1文件是什么?
ibdata1是一个用来构建innodb系统表空间的文件,这个文件包含了innodb表的元数据、undo日志、修改buffer和双写buffer。随着数据库的使用,ibdata1文件会越来越大,innodb_autoextend_increment选项则指定了该文件每次自动增长的步进,默认是8M.
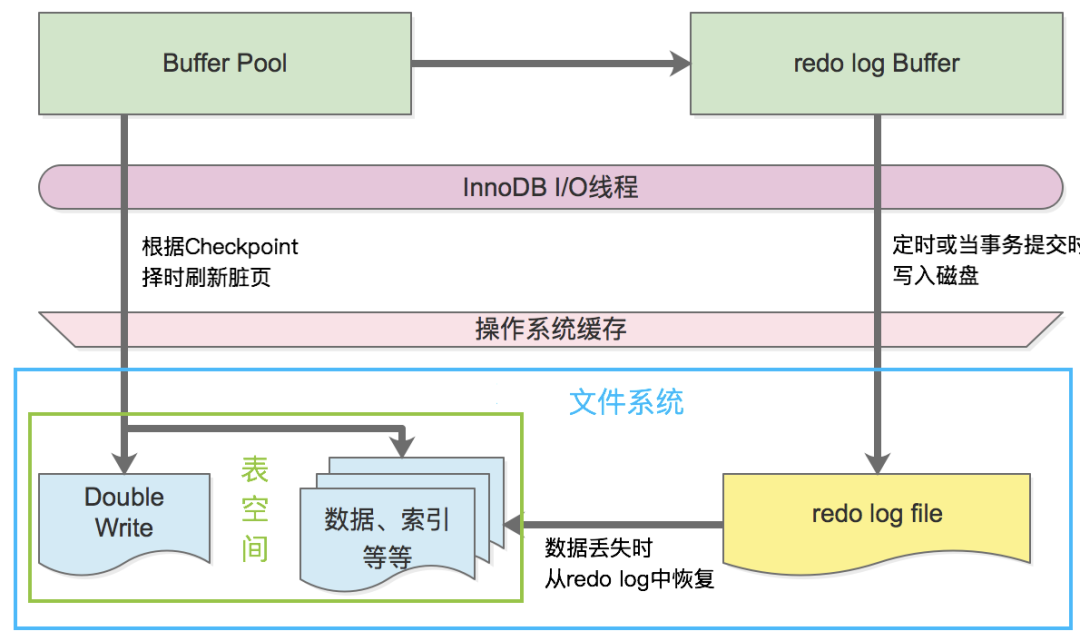
熟悉Oracle的亲,可以把ibdata理解成redo日志。
当在MySQL中对InnoDB表进行更改时,这些更改首先存储在InnoDB日志缓冲区的内存中,然后写入通常称为重做日志(redo logs)的InnoDB日志文件中。
介绍MySQL InnoDB 日志缓冲区(Log Buffer)的文章链接如下:
传送门:
知识分享 | MySQL InnoDB 日志缓冲区(Log Buffer)讲解
这里放张图
my.cnf中的参数设置形式:
innodb_data_file_path = ibdata1:256M;ibdata2:128M:autoextend
什么原因导致ibdata1越来越大?
上文也说了,ibdata1存放innodb表的元数据、undo日志、修改buffer和双写buffer,是MYSQL的最主要的数据,随着数据库越来越大,表也会越来越大。
尤其是innodb_file_per_table参数未开启的话,新创建表的数据和索引会存在系统表空间中,增加更加更快。
该如何处理呢?
业务数据使用独享表空间,将不用的业务表空间分别单独存放。MySQL开启独享表空间的参数是Innodb_file_per_table,会为每个Innodb表创建一个.ibd的文件。
没开启,怎么减小ibdata的大小?
两个操作步骤:
1.初始参数中修改innodb_data_file_path=1,保证业务数据被单独存放。
举例:innodb_data_file_path = ibdata1:32M;ibdata2:16M:autoextend
2.使用mysqldump做下数据的导出和导入
步骤2实操如下:
- 导出数据库中所有数据
# mysqldump -uroot -p --socket=/tmp/mysql.sock --single-transaction --master-data=2 --all-databases -E -R --triggers --set-gtid-purged=off > /tmp/all-database.dump - 删除数据库中数据
mysql> drop database dbname; - 停止MySQL
# /etc/init.d/mysqld stop
或
#mysqladmin -uroot -p shutdown - 删除ibdata1文件(移动到/tmp下)
# mv /var/lib/mysql/ibdata1 /tmp
# mv /var/lib/mysql/ib_logfile0 /tmp
# mv /var/lib/mysql/ib_logfile1 /tmp - my.cnf设定
# vi /etc/my.cnf
开启独享表空间,并指定ibdata1大小为256M,ibdata2大小128M,自动扩张。
innodb_file_per_table = 1
和
innodb_data_home_dir = /mysqldata/data
innodb_data_file_path = ibdata1:256M;ibdata2:128M:autoextend - 启动MySQL
# /etc/init.d/mysqld start
或者
#mysqld_safe --defaults-file=/etc/my.cnf --user=mysql & - 导入数据
# mysql -u root -p < /tmp/all-database.dump - 搞定
发问:使用mysqldump缩小ibdata时,mysqldump导出导入太慢,如何减少业务中断时间?
回答:充分利用主从架构来做,怎么做?
步骤如下:
1.主库mysqldump出导出文件,并scp到从库;
2.从库做逻辑恢复,并使用gtid追平主库数据(注意此刻的从库已经修改了innodb_file_per_table = 1和innodb_data_file_path = ibdata1:256M;ibdata2:128M:autoextend)
3.为保险起见,可找个业务空闲窗口,切换下高可用至从库(此刻的从库变为新主),并对外恢复业务数据访问
4.原主做mysqldump恢复,并追平新主数据,此刻原主为新从
5.搞定。
具体实操,不再赘述。
文章结束。
以下是个人微信公众号,欢迎关注: